 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018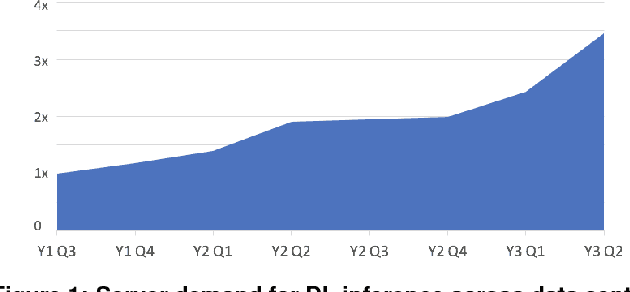
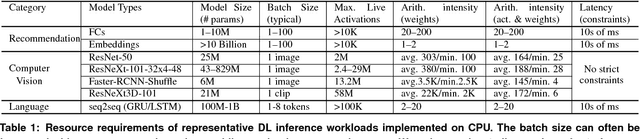
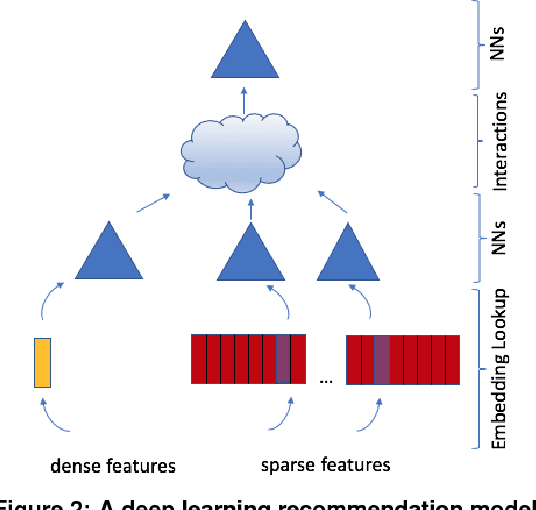
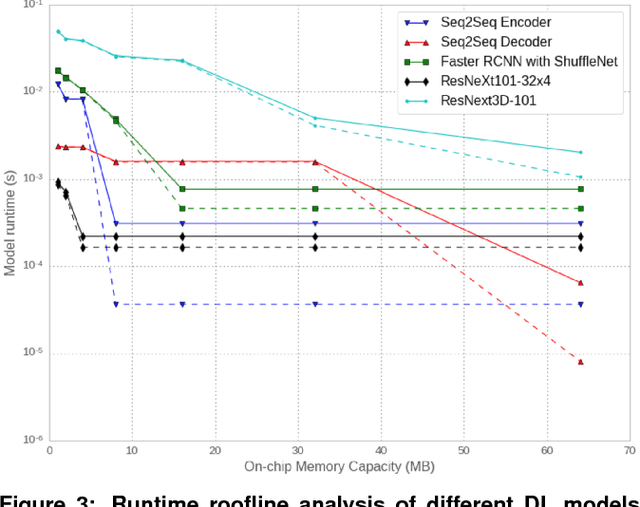
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.
On Periodic Functions as Regularizers for Quantization of Neural Networks
Nov 24, 2018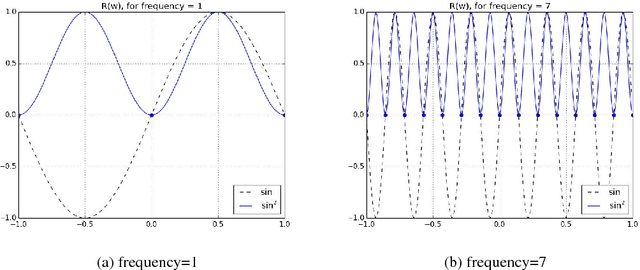
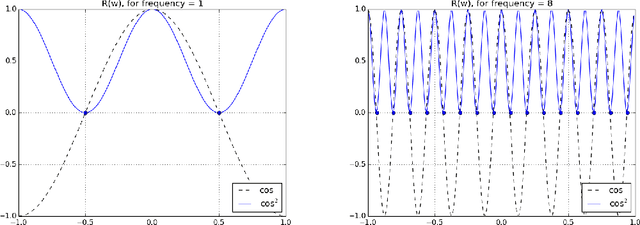
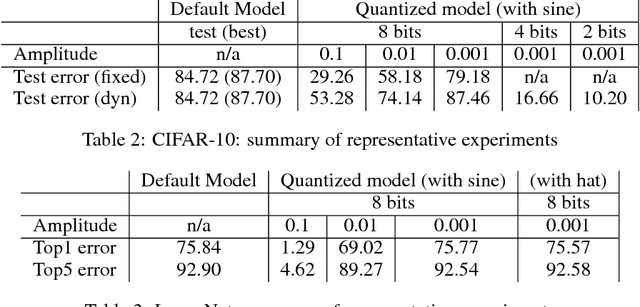
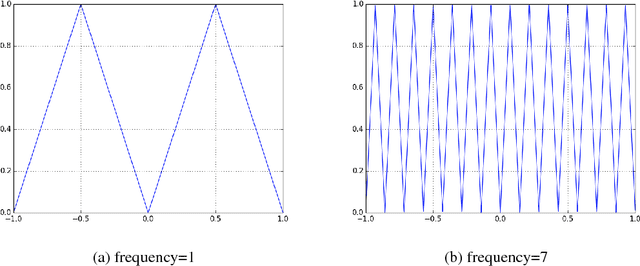
Deep learning models have been successfully used in computer vision and many other fields. We propose an unorthodox algorithm for performing quantization of the model parameters. In contrast with popular quantization schemes based on thresholds, we use a novel technique based on periodic functions, such as continuous trigonometric sine or cosine as well as non-continuous hat functions. We apply these functions component-wise and add the sum over the model parameters as a regularizer to the model loss during training. The frequency and amplitude hyper-parameters of these functions can be adjusted during training. The regularization pushes the weights into discrete points that can be encoded as integers. We show that using this technique the resulting quantized models exhibit the same accuracy as the original ones on CIFAR-10 and ImageNet datasets.
Enabling Sparse Winograd Convolution by Native Pruning
Oct 13, 2017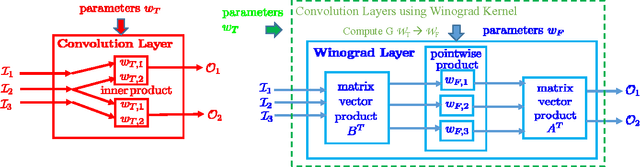
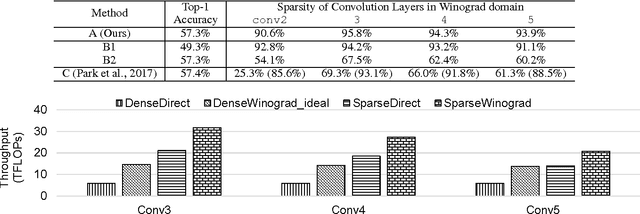
Sparse methods and the use of Winograd convolutions are two orthogonal approaches, each of which significantly accelerates convolution computations in modern CNNs. Sparse Winograd merges these two and thus has the potential to offer a combined performance benefit. Nevertheless, training convolution layers so that the resulting Winograd kernels are sparse has not hitherto been very successful. By introducing a Winograd layer in place of a standard convolution layer, we can learn and prune Winograd coefficients "natively" and obtain sparsity level beyond 90% with only 0.1% accuracy loss with AlexNet on ImageNet dataset. Furthermore, we present a sparse Winograd convolution algorithm and implementation that exploits the sparsity, achieving up to 31.7 effective TFLOP/s in 32-bit precision on a latest Intel Xeon CPU, which corresponds to a 5.4x speedup over a state-of-the-art dense convolution implementation.
Faster CNNs with Direct Sparse Convolutions and Guided Pruning
Jul 28, 2017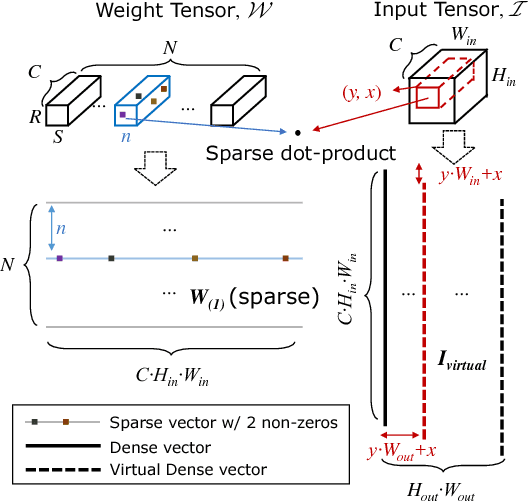

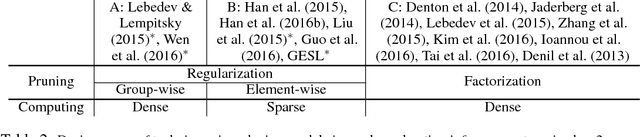
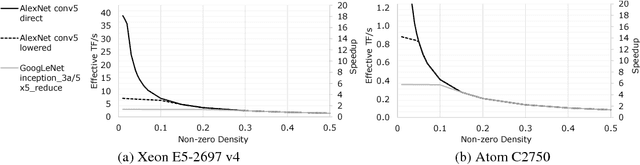
Phenomenally successful in practical inference problems, convolutional neural networks (CNN) are widely deployed in mobile devices, data centers, and even supercomputers. The number of parameters needed in CNNs, however, are often large and undesirable. Consequently, various methods have been developed to prune a CNN once it is trained. Nevertheless, the resulting CNNs offer limited benefits. While pruning the fully connected layers reduces a CNN's size considerably, it does not improve inference speed noticeably as the compute heavy parts lie in convolutions. Pruning CNNs in a way that increase inference speed often imposes specific sparsity structures, thus limiting the achievable sparsity levels. We present a method to realize simultaneously size economy and speed improvement while pruning CNNs. Paramount to our success is an efficient general sparse-with-dense matrix multiplication implementation that is applicable to convolution of feature maps with kernels of arbitrary sparsity patterns. Complementing this, we developed a performance model that predicts sweet spots of sparsity levels for different layers and on different computer architectures. Together, these two allow us to demonstrate 3.1--7.3$\times$ convolution speedups over dense convolution in AlexNet, on Intel Atom, Xeon, and Xeon Phi processors, spanning the spectrum from mobile devices to supercomputers. We also open source our project at https://github.com/IntelLabs/SkimCaffe.