 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021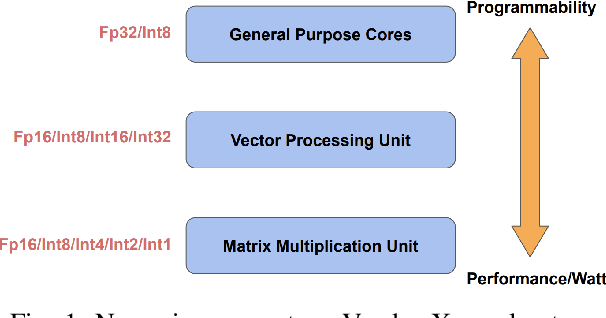
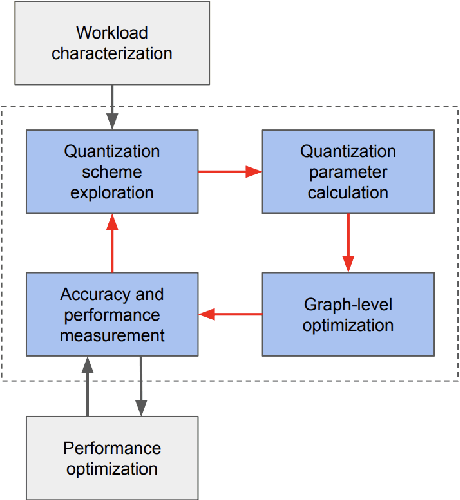
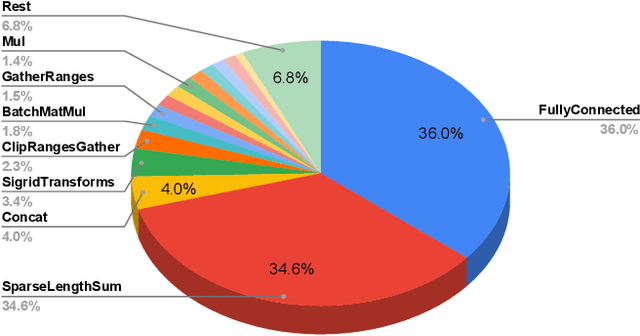
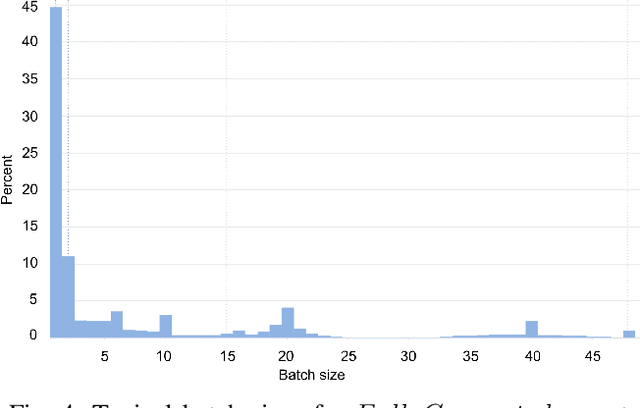
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021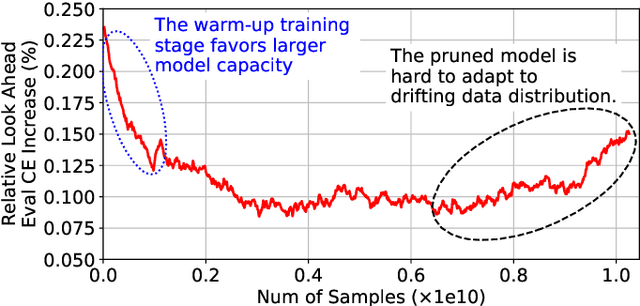

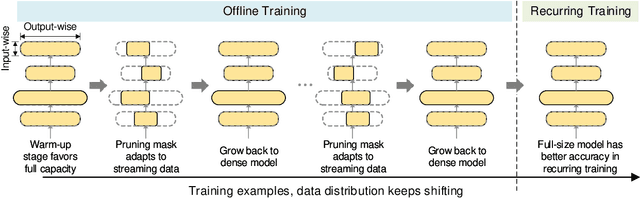

Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021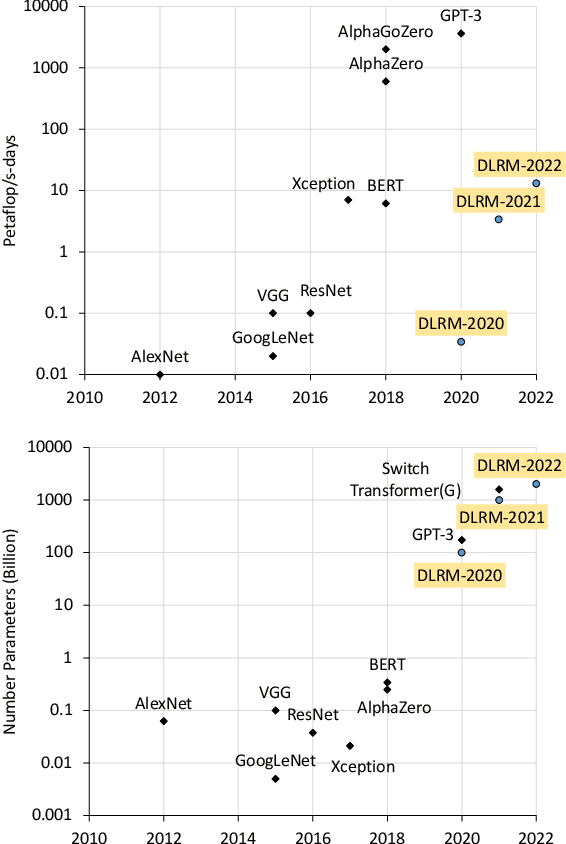

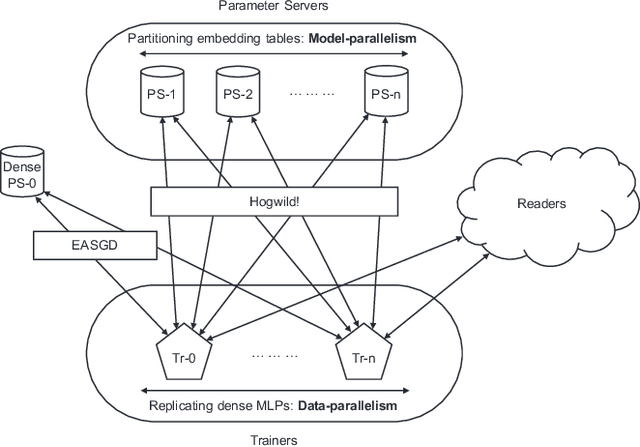
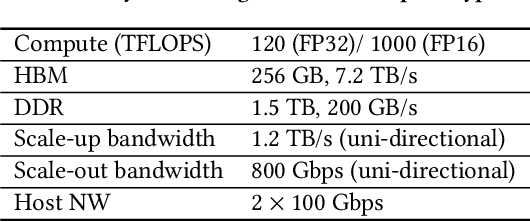
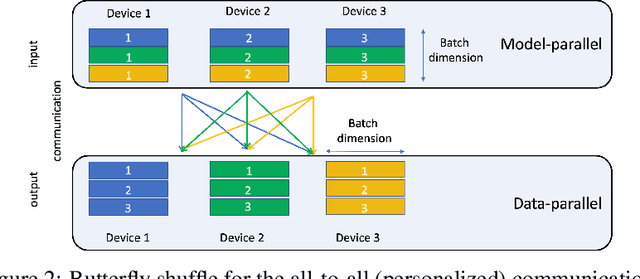
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
FBGEMM: Enabling High-Performance Low-Precision Deep Learning Inference
Jan 13, 2021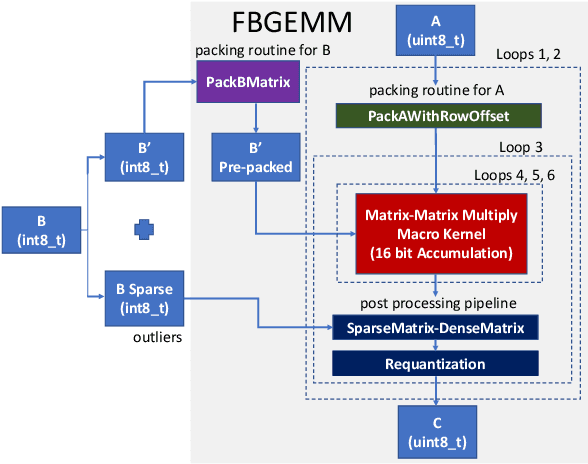
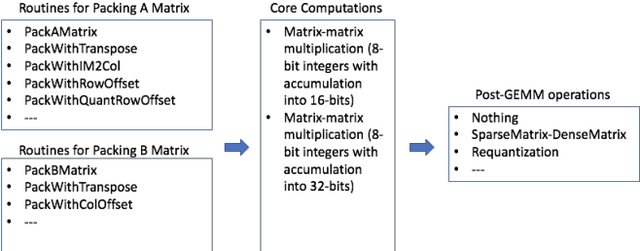
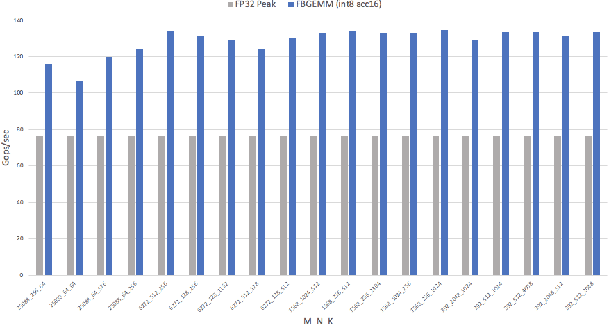
Deep learning models typically use single-precision (FP32) floating point data types for representing activations and weights, but a slew of recent research work has shown that computations with reduced-precision data types (FP16, 16-bit integers, 8-bit integers or even 4- or 2-bit integers) are enough to achieve same accuracy as FP32 and are much more efficient. Therefore, we designed fbgemm, a high-performance kernel library, from ground up to perform high-performance quantized inference on current generation CPUs. fbgemm achieves efficiency by fusing common quantization operations with a high-performance gemm implementation and by shape- and size-specific kernel code generation at runtime. The library has been deployed at Facebook, where it delivers greater than 2x performance gains with respect to our current production baseline.
Mixed-Precision Embedding Using a Cache
Oct 23, 2020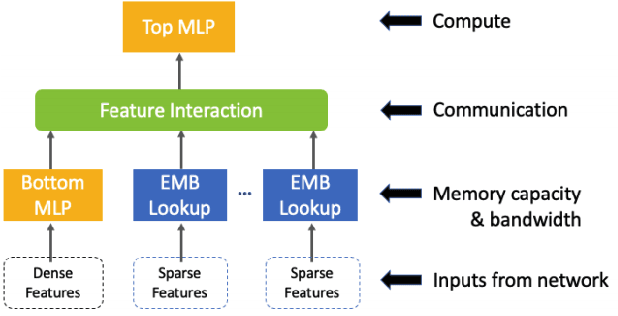

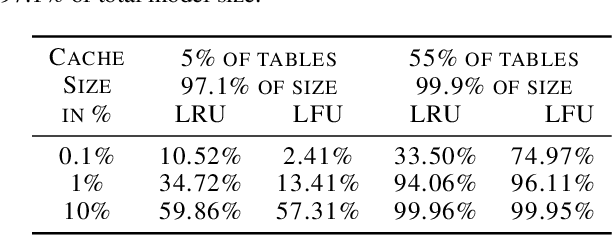
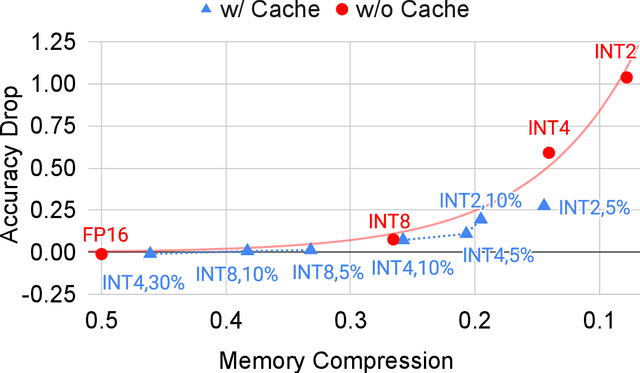
In recommendation systems, practitioners observed that increase in the number of embedding tables and their sizes often leads to significant improvement in model performances. Given this and the business importance of these models to major internet companies, embedding tables for personalization tasks have grown to terabyte scale and continue to grow at a significant rate. Meanwhile, these large-scale models are often trained with GPUs where high-performance memory is a scarce resource, thus motivating numerous work on embedding table compression during training. We propose a novel change to embedding tables using a cache memory architecture, where the majority of rows in an embedding is trained in low precision, and the most frequently or recently accessed rows cached and trained in full precision. The proposed architectural change works in conjunction with standard precision reduction and computer arithmetic techniques such as quantization and stochastic rounding. For an open source deep learning recommendation model (DLRM) running with Criteo-Kaggle dataset, we achieve 3x memory reduction with INT8 precision embedding tables and full-precision cache whose size are 5% of the embedding tables, while maintaining accuracy. For an industrial scale model and dataset, we achieve even higher >7x memory reduction with INT4 precision and cache size 1% of embedding tables, while maintaining accuracy, and 16% end-to-end training speedup by reducing GPU-to-host data transfers.
Adaptive Dense-to-Sparse Paradigm for Pruning Online Recommendation System with Non-Stationary Data
Oct 21, 2020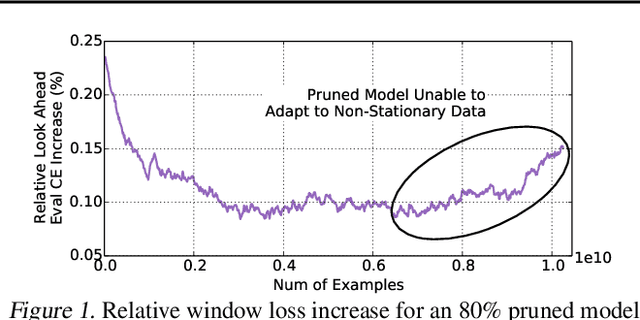
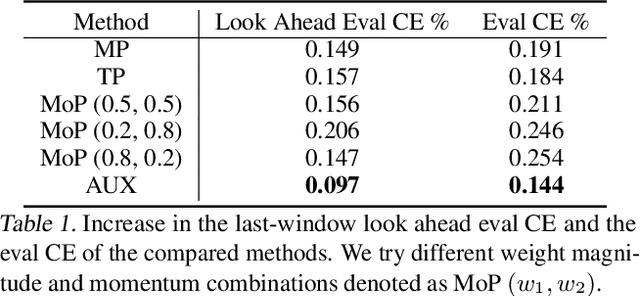
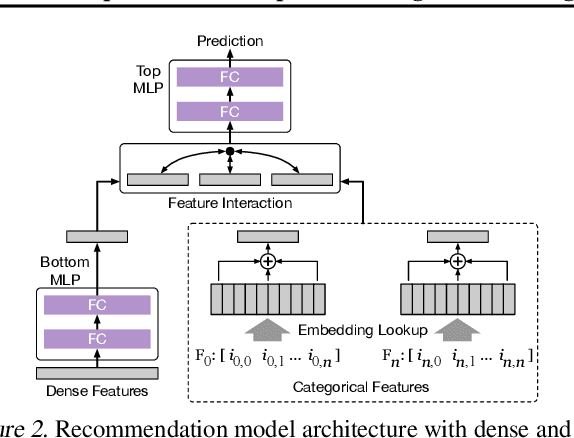
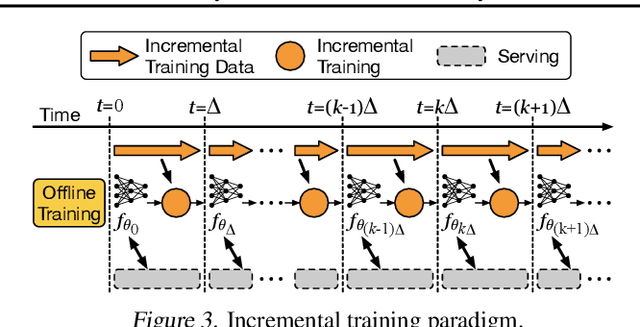
Large scale deep learning provides a tremendous opportunity to improve the quality of content recommendation systems by employing both wider and deeper models, but this comes at great infrastructural cost and carbon footprint in modern data centers. Pruning is an effective technique that reduces both memory and compute demand for model inference. However, pruning for online recommendation systems is challenging due to the continuous data distribution shift (a.k.a non-stationary data). Although incremental training on the full model is able to adapt to the non-stationary data, directly applying it on the pruned model leads to accuracy loss. This is because the sparsity pattern after pruning requires adjustment to learn new patterns. To the best of our knowledge, this is the first work to provide in-depth analysis and discussion of applying pruning to online recommendation systems with non-stationary data distribution. Overall, this work makes the following contributions: 1) We present an adaptive dense to sparse paradigm equipped with a novel pruning algorithm for pruning a large scale recommendation system with non-stationary data distribution; 2) We design the pruning algorithm to automatically learn the sparsity across layers to avoid repeating hand-tuning, which is critical for pruning the heterogeneous architectures of recommendation systems trained with non-stationary data.
Post-Training 4-bit Quantization on Embedding Tables
Nov 05, 2019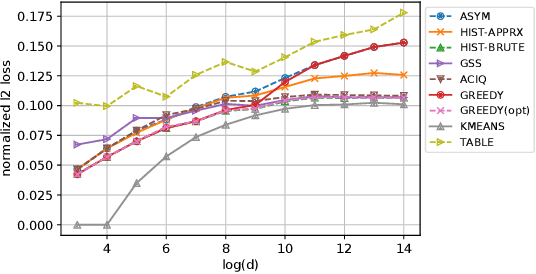

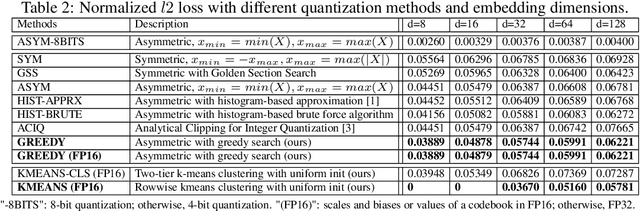
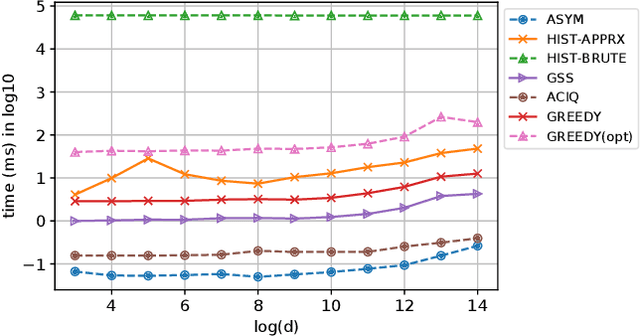
Continuous representations have been widely adopted in recommender systems where a large number of entities are represented using embedding vectors. As the cardinality of the entities increases, the embedding components can easily contain millions of parameters and become the bottleneck in both storage and inference due to large memory consumption. This work focuses on post-training 4-bit quantization on the continuous embeddings. We propose row-wise uniform quantization with greedy search and codebook-based quantization that consistently outperforms state-of-the-art quantization approaches on reducing accuracy degradation. We deploy our uniform quantization technique on a production model in Facebook and demonstrate that it can reduce the model size to only 13.89% of the single-precision version while the model quality stays neutral.
A Study of BFLOAT16 for Deep Learning Training
Jun 13, 2019
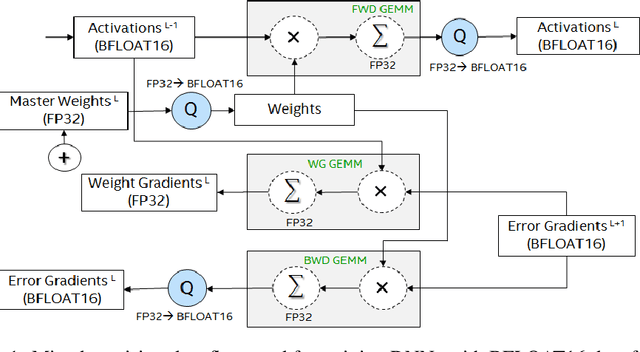
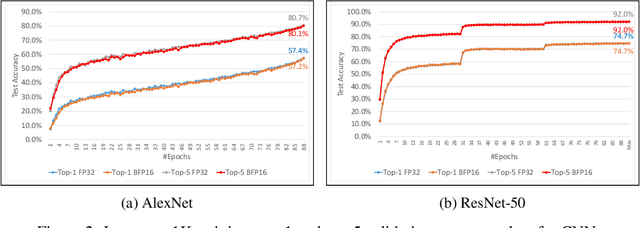

This paper presents the first comprehensive empirical study demonstrating the efficacy of the Brain Floating Point (BFLOAT16) half-precision format for Deep Learning training across image classification, speech recognition, language modeling, generative networks and industrial recommendation systems. BFLOAT16 is attractive for Deep Learning training for two reasons: the range of values it can represent is the same as that of IEEE 754 floating-point format (FP32) and conversion to/from FP32 is simple. Maintaining the same range as FP32 is important to ensure that no hyper-parameter tuning is required for convergence; e.g., IEEE 754 compliant half-precision floating point (FP16) requires hyper-parameter tuning. In this paper, we discuss the flow of tensors and various key operations in mixed precision training, and delve into details of operations, such as the rounding modes for converting FP32 tensors to BFLOAT16. We have implemented a method to emulate BFLOAT16 operations in Tensorflow, Caffe2, IntelCaffe, and Neon for our experiments. Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters.
Deep Learning Recommendation Model for Personalization and Recommendation Systems
May 31, 2019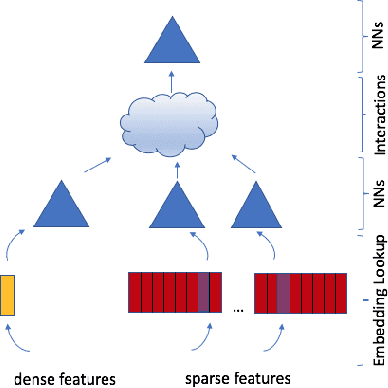

With the advent of deep learning, neural network-based recommendation models have emerged as an important tool for tackling personalization and recommendation tasks. These networks differ significantly from other deep learning networks due to their need to handle categorical features and are not well studied or understood. In this paper, we develop a state-of-the-art deep learning recommendation model (DLRM) and provide its implementation in both PyTorch and Caffe2 frameworks. In addition, we design a specialized parallelization scheme utilizing model parallelism on the embedding tables to mitigate memory constraints while exploiting data parallelism to scale-out compute from the fully-connected layers. We compare DLRM against existing recommendation models and characterize its performance on the Big Basin AI platform, demonstrating its usefulness as a benchmark for future algorithmic experimentation and system co-design.
Spatial-Winograd Pruning Enabling Sparse Winograd Convolution
Jan 08, 2019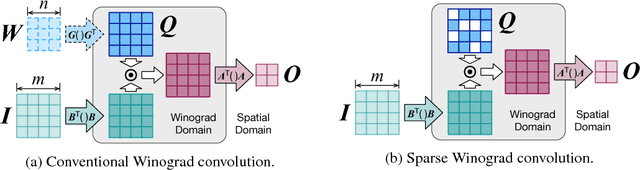
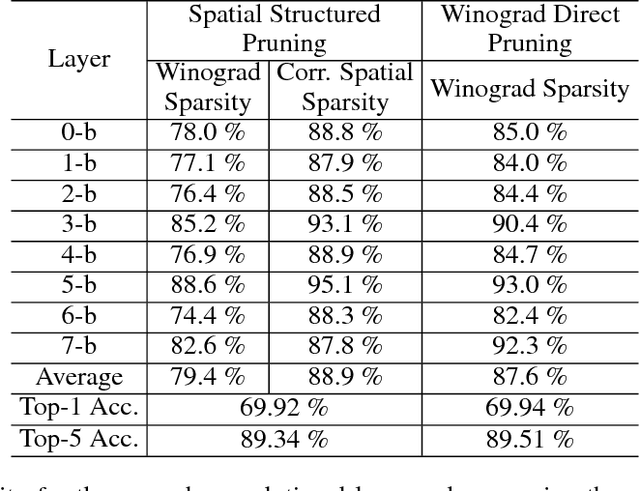
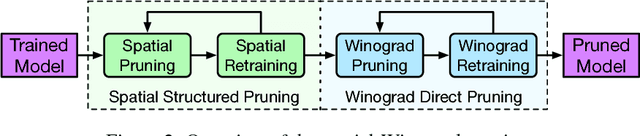
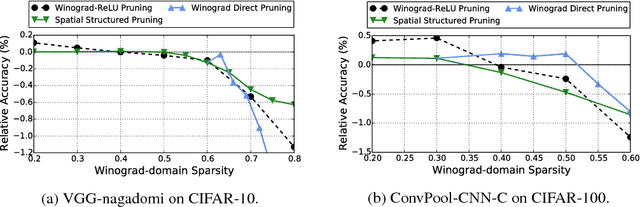
Deep convolutional neural networks (CNNs) are deployed in various applications but demand immense computational requirements. Pruning techniques and Winograd convolution are two typical methods to reduce the CNN computation. However, they cannot be directly combined because Winograd transformation fills in the sparsity resulting from pruning. Li et al. (2017) propose sparse Winograd convolution in which weights are directly pruned in the Winograd domain, but this technique is not very practical because Winograd-domain retraining requires low learning rates and hence significantly longer training time. Besides, Liu et al. (2018) move the ReLU function into the Winograd domain, which can help increase the weight sparsity but requires changes in the network structure. To achieve a high Winograd-domain weight sparsity without changing network structures, we propose a new pruning method, spatial-Winograd pruning. As the first step, spatial-domain weights are pruned in a structured way, which efficiently transfers the spatial-domain sparsity into the Winograd domain and avoids Winograd-domain retraining. For the next step, we also perform pruning and retraining directly in the Winograd domain but propose to use an importance factor matrix to adjust weight importance and weight gradients. This adjustment makes it possible to effectively retrain the pruned Winograd-domain network without changing the network structure. For the three models on the datasets of CIFAR10, CIFAR-100, and ImageNet, our proposed method can achieve the Winograd domain sparsities of 63%, 50%, and 74%, respectively.