 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping the PsyCogMetrics AI Lab to Evaluate Large Language Models and Advance Cognitive Science -- A Three-Cycle Action Design Science Study
Mar 13, 2026This study presents the development of the PsyCogMetrics AI Lab (psycogmetrics.ai), an integrated, cloud-based platform that operationalizes psychometric and cognitive-science methodologies for Large Language Model (LLM) evaluation. Framed as a three-cycle Action Design Science study, the Relevance Cycle identifies key limitations in current evaluation methods and unfulfilled stakeholder needs. The Rigor Cycle draws on kernel theories such as Popperian falsifiability, Classical Test Theory, and Cognitive Load Theory to derive deductive design objectives. The Design Cycle operationalizes these objectives through nested Build-Intervene-Evaluate loops. The study contributes a novel IT artifact, a validated design for LLM evaluation, benefiting research at the intersection of AI, psychology, cognitive science, and the social and behavioral sciences.
* 10 pages. Prepared: April 2025; submitted: June 15, 2025; accepted: August 2025. In: Proceedings of the 59th Hawaii International Conference on System Sciences (HICSS 2026), January 2026
Counterweights and Complementarities: The Convergence of AI and Blockchain Powering a Decentralized Future
Mar 11, 2026This editorial addresses the critical intersection of artificial intelligence (AI) and blockchain technologies, highlighting their contrasting tendencies toward centralization and decentralization, respectively. While AI, particularly with the rise of large language models (LLMs), exhibits a strong centralizing force due to data and resource monopolization by large corporations, blockchain offers a counterbalancing mechanism through its inherent decentralization, transparency, and security. The editorial argues that these technologies are not mutually exclusive but possess complementary strengths. Blockchain can mitigate AI's centralizing risks by enabling decentralized data management, computation, and governance, promoting greater inclusivity, transparency, and user privacy. Conversely, AI can enhance blockchain's efficiency and security through automated smart contract management, content curation, and threat detection. The core argument calls for the development of ``decentralized intelligence'' (DI) -- an interdisciplinary research area focused on creating intelligent systems that function without centralized control.
* 7 pages, Editorial, published in ACM SIGMIS Database Vol. 56, Iss. 2
Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Jul 05, 2024DLRM is a state-of-the-art recommendation system model that has gained widespread adoption across various industry applications. The large size of DLRM models, however, necessitates the use of multiple devices/GPUs for efficient training. A significant bottleneck in this process is the time-consuming all-to-all communication required to collect embedding data from all devices. To mitigate this, we introduce a method that employs error-bounded lossy compression to reduce the communication data size and accelerate DLRM training. We develop a novel error-bounded lossy compression algorithm, informed by an in-depth analysis of embedding data features, to achieve high compression ratios. Moreover, we introduce a dual-level adaptive strategy for error-bound adjustment, spanning both table-wise and iteration-wise aspects, to balance the compression benefits with the potential impacts on accuracy. We further optimize our compressor for PyTorch tensors on GPUs, minimizing compression overhead. Evaluation shows that our method achieves a 1.38$\times$ training speedup with a minimal accuracy impact.
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021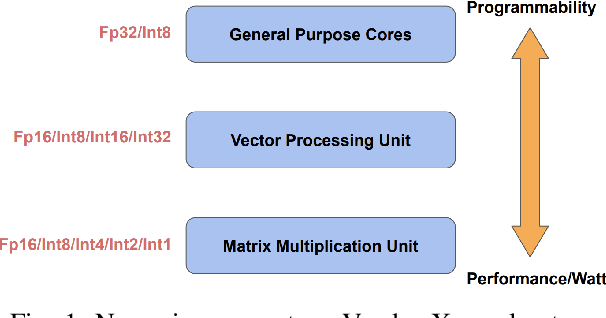
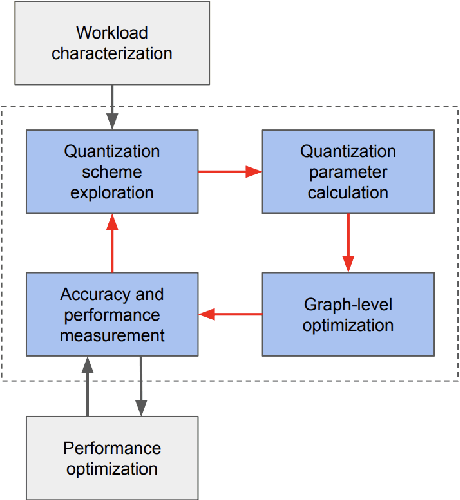
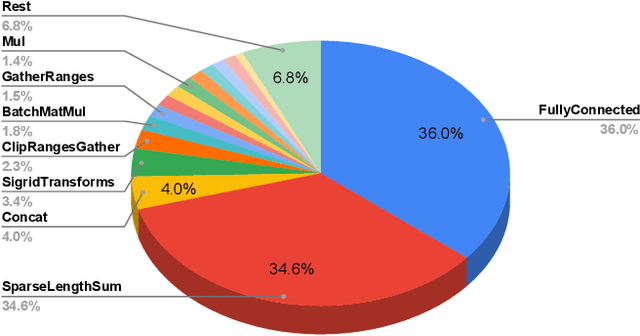
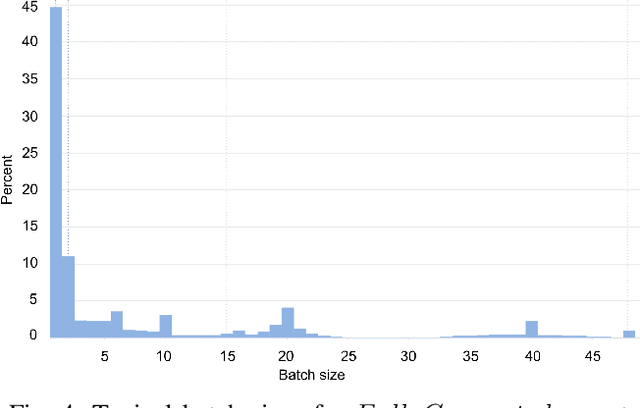
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.