 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyDi QA-WANA: A Benchmark for Information-Seeking Question Answering in Languages of West Asia and North Africa
Jul 23, 2025We present TyDi QA-WANA, a question-answering dataset consisting of 28K examples divided among 10 language varieties of western Asia and northern Africa. The data collection process was designed to elicit information-seeking questions, where the asker is genuinely curious to know the answer. Each question in paired with an entire article that may or may not contain the answer; the relatively large size of the articles results in a task suitable for evaluating models' abilities to utilize large text contexts in answering questions. Furthermore, the data was collected directly in each language variety, without the use of translation, in order to avoid issues of cultural relevance. We present performance of two baseline models, and release our code and data to facilitate further improvement by the research community.
Multitask Multilingual Model Adaptation with Featurized Low-Rank Mixtures
Feb 27, 2024Adapting pretrained large language models (LLMs) to various downstream tasks in tens or hundreds of human languages is computationally expensive. Parameter-efficient fine-tuning (PEFT) significantly reduces the adaptation cost, by tuning only a small amount of parameters. However, directly applying PEFT methods such as LoRA (Hu et al., 2022) on diverse dataset mixtures could lead to suboptimal performance due to limited parameter capacity and negative interference among different datasets. In this work, we propose Featurized Low-rank Mixtures (FLix), a novel PEFT method designed for effective multitask multilingual tuning. FLix associates each unique dataset feature, such as the dataset's language or task, with its own low-rank weight update parameters. By composing feature-specific parameters for each dataset, FLix can accommodate diverse dataset mixtures and generalize better to unseen datasets. Our experiments show that FLix leads to significant improvements over a variety of tasks for both supervised learning and zero-shot settings using different training data mixtures.
FIAT: Fusing learning paradigms with Instruction-Accelerated Tuning
Sep 12, 2023Learning paradigms for large language models (LLMs) currently tend to fall within either in-context learning (ICL) or full fine-tuning. Each of these comes with their own trade-offs based on available data, model size, compute cost, ease-of-use, and final quality with neither solution performing well across-the-board. In this article, we first describe ICL and fine-tuning paradigms in a way that highlights their natural connections. Based on these connections, we propose a new learning paradigm called FIAT that fuses the best of these paradigms together, enabling prompt-engineered instructions and chain-of-thought reasoning with the very largest models while also using similar methods to perform parameter updates on a modestly-sized LLM with parameter-efficient tuning. We evaluate FIAT's effectiveness on a variety of multilingual tasks and observe that FIAT performs better than both ICL and fine-tuning at scales ranging from 100-10,000 training examples. We hope that FIAT provides a practical way of harnessing the full potential of LLMs without needing to make a hard choice between learning paradigms.
The Devil is in the Errors: Leveraging Large Language Models for Fine-grained Machine Translation Evaluation
Aug 14, 2023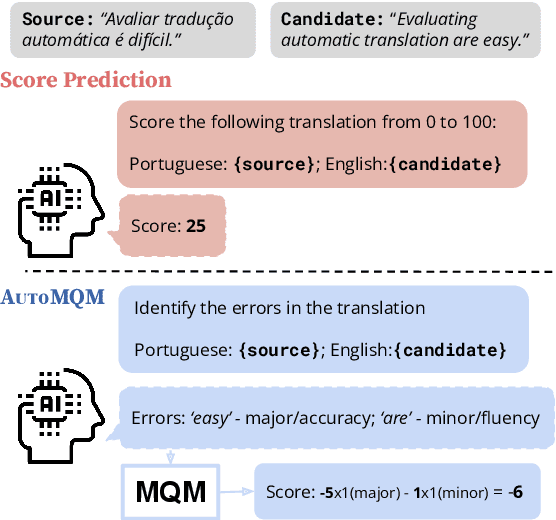

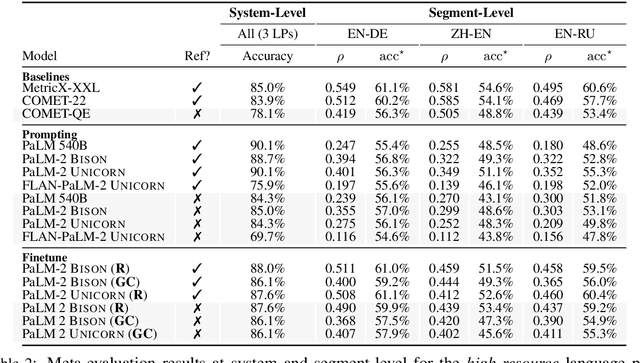
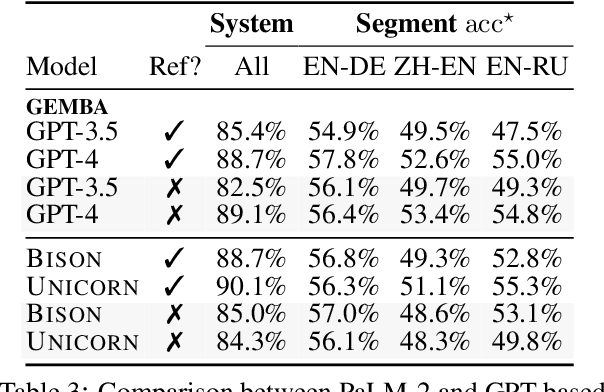
Automatic evaluation of machine translation (MT) is a critical tool driving the rapid iterative development of MT systems. While considerable progress has been made on estimating a single scalar quality score, current metrics lack the informativeness of more detailed schemes that annotate individual errors, such as Multidimensional Quality Metrics (MQM). In this paper, we help fill this gap by proposing AutoMQM, a prompting technique which leverages the reasoning and in-context learning capabilities of large language models (LLMs) and asks them to identify and categorize errors in translations. We start by evaluating recent LLMs, such as PaLM and PaLM-2, through simple score prediction prompting, and we study the impact of labeled data through in-context learning and finetuning. We then evaluate AutoMQM with PaLM-2 models, and we find that it improves performance compared to just prompting for scores (with particularly large gains for larger models) while providing interpretability through error spans that align with human annotations.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
Evaluating and Modeling Attribution for Cross-Lingual Question Answering
May 23, 2023



Trustworthy answer content is abundant in many high-resource languages and is instantly accessible through question answering systems, yet this content can be hard to access for those that do not speak these languages. The leap forward in cross-lingual modeling quality offered by generative language models offers much promise, yet their raw generations often fall short in factuality. To improve trustworthiness in these systems, a promising direction is to attribute the answer to a retrieved source, possibly in a content-rich language different from the query. Our work is the first to study attribution for cross-lingual question answering. First, we collect data in 5 languages to assess the attribution level of a state-of-the-art cross-lingual QA system. To our surprise, we find that a substantial portion of the answers is not attributable to any retrieved passages (up to 50% of answers exactly matching a gold reference) despite the system being able to attend directly to the retrieved text. Second, to address this poor attribution level, we experiment with a wide range of attribution detection techniques. We find that Natural Language Inference models and PaLM 2 fine-tuned on a very small amount of attribution data can accurately detect attribution. Based on these models, we improve the attribution level of a cross-lingual question-answering system. Overall, we show that current academic generative cross-lingual QA systems have substantial shortcomings in attribution and we build tooling to mitigate these issues.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
Beyond Contrastive Learning: A Variational Generative Model for Multilingual Retrieval
Dec 21, 2022Contrastive learning has been successfully used for retrieval of semantically aligned sentences, but it often requires large batch sizes or careful engineering to work well. In this paper, we instead propose a generative model for learning multilingual text embeddings which can be used to retrieve or score sentence pairs. Our model operates on parallel data in $N$ languages and, through an approximation we introduce, efficiently encourages source separation in this multilingual setting, separating semantic information that is shared between translations from stylistic or language-specific variation. We show careful large-scale comparisons between contrastive and generation-based approaches for learning multilingual text embeddings, a comparison that has not been done to the best of our knowledge despite the popularity of these approaches. We evaluate this method on a suite of tasks including semantic similarity, bitext mining, and cross-lingual question retrieval -- the last of which we introduce in this paper. Overall, our Variational Multilingual Source-Separation Transformer (VMSST) model outperforms both a strong contrastive and generative baseline on these tasks.
MIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
Jul 02, 2022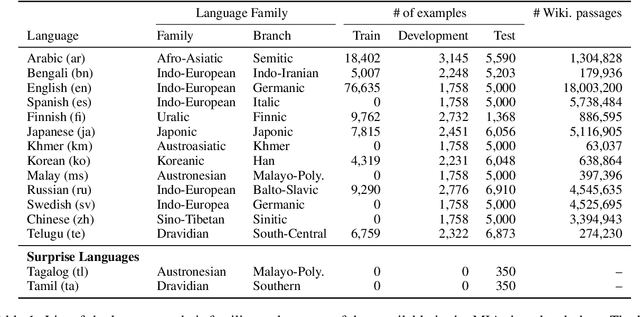
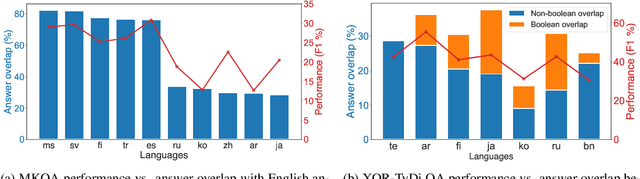
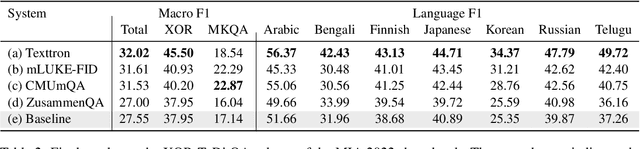
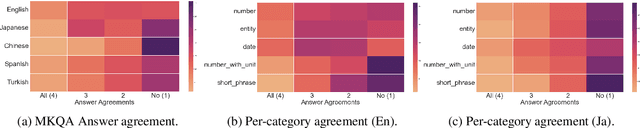
We present the results of the Workshop on Multilingual Information Access (MIA) 2022 Shared Task, evaluating cross-lingual open-retrieval question answering (QA) systems in 16 typologically diverse languages. In this task, we adapted two large-scale cross-lingual open-retrieval QA datasets in 14 typologically diverse languages, and newly annotated open-retrieval QA data in 2 underrepresented languages: Tagalog and Tamil. Four teams submitted their systems. The best system leveraging iteratively mined diverse negative examples and larger pretrained models achieves 32.2 F1, outperforming our baseline by 4.5 points. The second best system uses entity-aware contextualized representations for document retrieval, and achieves significant improvements in Tamil (20.8 F1), whereas most of the other systems yield nearly zero scores.