 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Supervised Models And Learned Speech Representations For Classifying Intelligibility Of Disordered Speech On Selected Phrases
Jul 08, 2021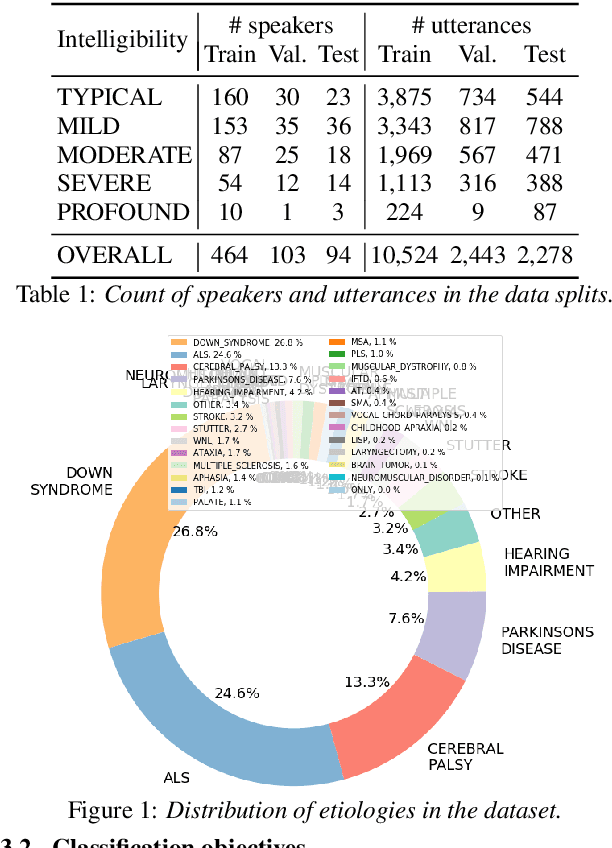
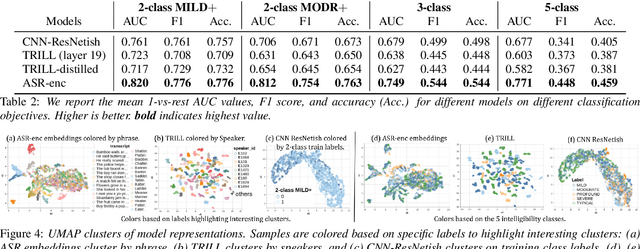
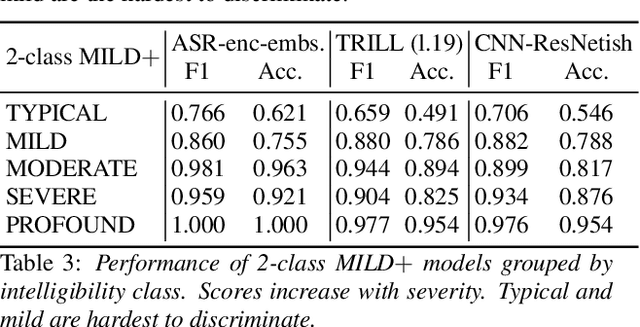
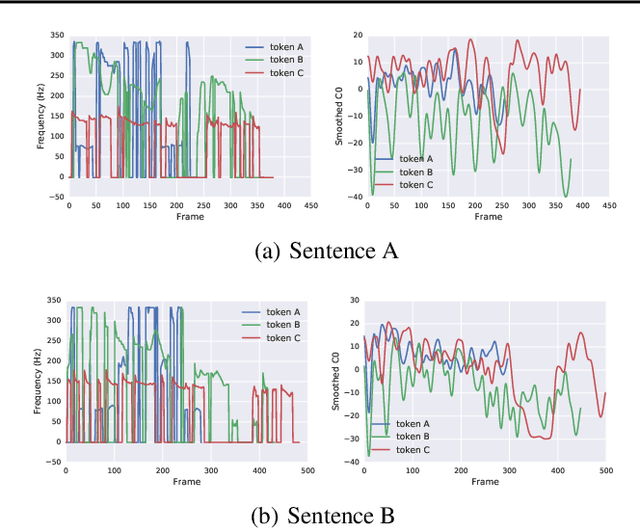
Automatic classification of disordered speech can provide an objective tool for identifying the presence and severity of speech impairment. Classification approaches can also help identify hard-to-recognize speech samples to teach ASR systems about the variable manifestations of impaired speech. Here, we develop and compare different deep learning techniques to classify the intelligibility of disordered speech on selected phrases. We collected samples from a diverse set of 661 speakers with a variety of self-reported disorders speaking 29 words or phrases, which were rated by speech-language pathologists for their overall intelligibility using a five-point Likert scale. We then evaluated classifiers developed using 3 approaches: (1) a convolutional neural network (CNN) trained for the task, (2) classifiers trained on non-semantic speech representations from CNNs that used an unsupervised objective [1], and (3) classifiers trained on the acoustic (encoder) embeddings from an ASR system trained on typical speech [2]. We found that the ASR encoder's embeddings considerably outperform the other two on detecting and classifying disordered speech. Further analysis shows that the ASR embeddings cluster speech by the spoken phrase, while the non-semantic embeddings cluster speech by speaker. Also, longer phrases are more indicative of intelligibility deficits than single words.
Towards Learning a Universal Non-Semantic Representation of Speech
Mar 02, 2020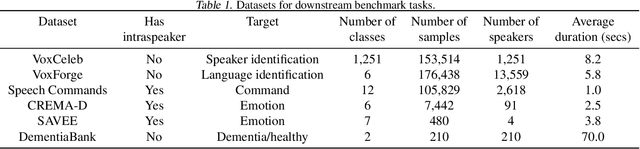
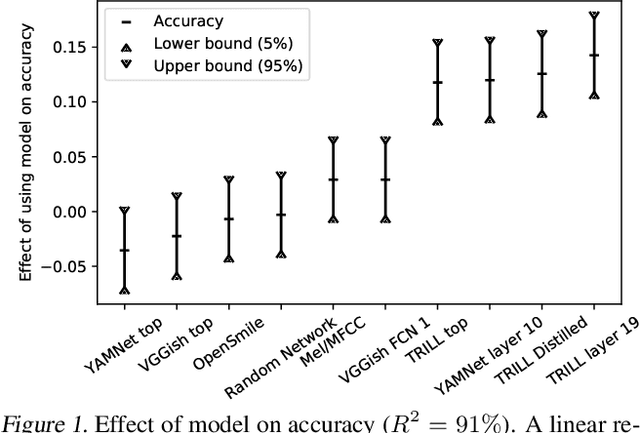
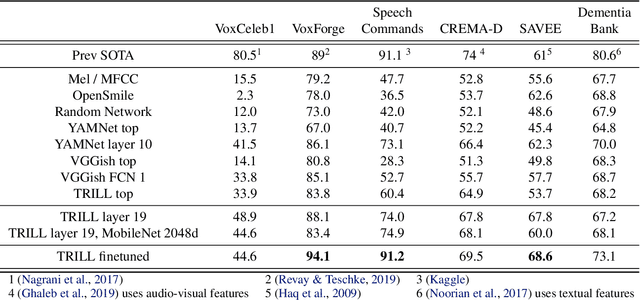
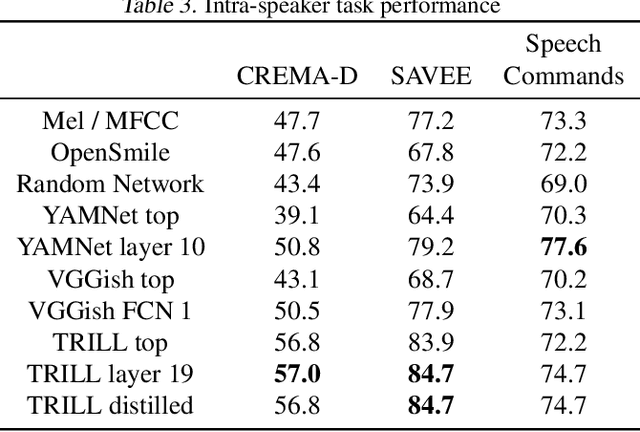
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.
Personalizing ASR for Dysarthric and Accented Speech with Limited Data
Jul 31, 2019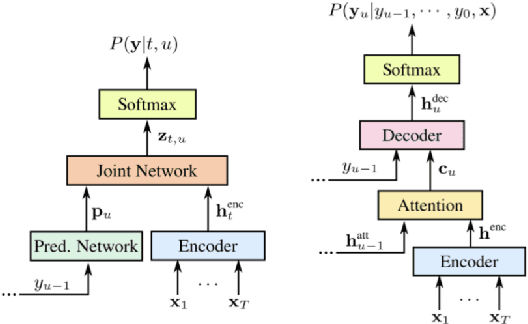
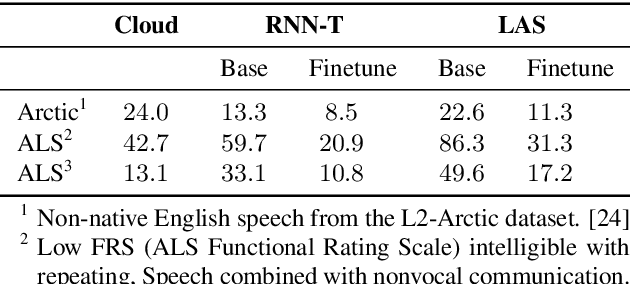
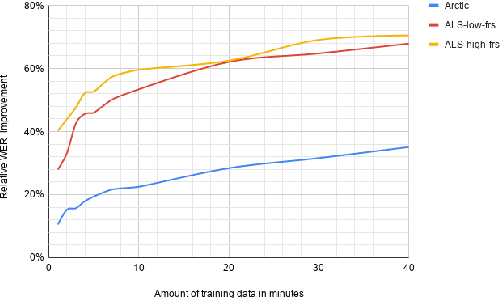
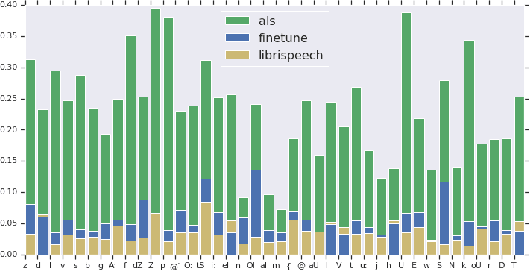
Automatic speech recognition (ASR) systems have dramatically improved over the last few years. ASR systems are most often trained from 'typical' speech, which means that underrepresented groups don't experience the same level of improvement. In this paper, we present and evaluate finetuning techniques to improve ASR for users with non-standard speech. We focus on two types of non-standard speech: speech from people with amyotrophic lateral sclerosis (ALS) and accented speech. We train personalized models that achieve 62% and 35% relative WER improvement on these two groups, bringing the absolute WER for ALS speakers, on a test set of message bank phrases, down to 10% for mild dysarthria and 20% for more serious dysarthria. We show that 71% of the improvement comes from only 5 minutes of training data. Finetuning a particular subset of layers (with many fewer parameters) often gives better results than finetuning the entire model. This is the first step towards building state of the art ASR models for dysarthric speech.
Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
Mar 24, 2018
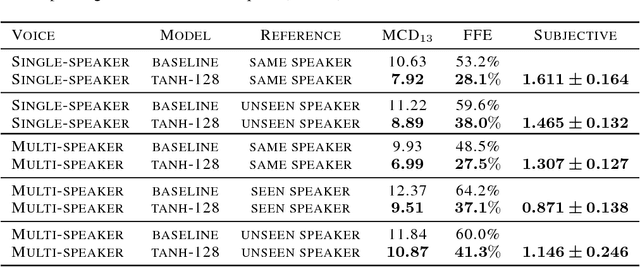

We present an extension to the Tacotron speech synthesis architecture that learns a latent embedding space of prosody, derived from a reference acoustic representation containing the desired prosody. We show that conditioning Tacotron on this learned embedding space results in synthesized audio that matches the prosody of the reference signal with fine time detail even when the reference and synthesis speakers are different. Additionally, we show that a reference prosody embedding can be used to synthesize text that is different from that of the reference utterance. We define several quantitative and subjective metrics for evaluating prosody transfer, and report results with accompanying audio samples from single-speaker and 44-speaker Tacotron models on a prosody transfer task.
Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
Mar 23, 2018
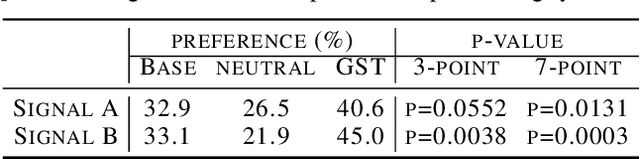

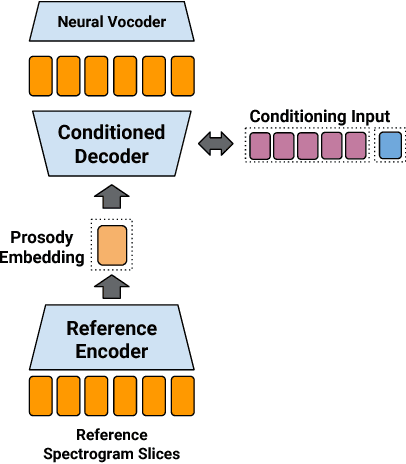
In this work, we propose "global style tokens" (GSTs), a bank of embeddings that are jointly trained within Tacotron, a state-of-the-art end-to-end speech synthesis system. The embeddings are trained with no explicit labels, yet learn to model a large range of acoustic expressiveness. GSTs lead to a rich set of significant results. The soft interpretable "labels" they generate can be used to control synthesis in novel ways, such as varying speed and speaking style - independently of the text content. They can also be used for style transfer, replicating the speaking style of a single audio clip across an entire long-form text corpus. When trained on noisy, unlabeled found data, GSTs learn to factorize noise and speaker identity, providing a path towards highly scalable but robust speech synthesis.
Spatially adaptive image compression using a tiled deep network
Feb 07, 2018
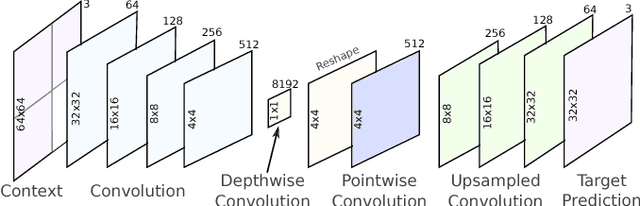

Deep neural networks represent a powerful class of function approximators that can learn to compress and reconstruct images. Existing image compression algorithms based on neural networks learn quantized representations with a constant spatial bit rate across each image. While entropy coding introduces some spatial variation, traditional codecs have benefited significantly by explicitly adapting the bit rate based on local image complexity and visual saliency. This paper introduces an algorithm that combines deep neural networks with quality-sensitive bit rate adaptation using a tiled network. We demonstrate the importance of spatial context prediction and show improved quantitative (PSNR) and qualitative (subjective rater assessment) results compared to a non-adaptive baseline and a recently published image compression model based on fully-convolutional neural networks.
Uncovering Latent Style Factors for Expressive Speech Synthesis
Nov 01, 2017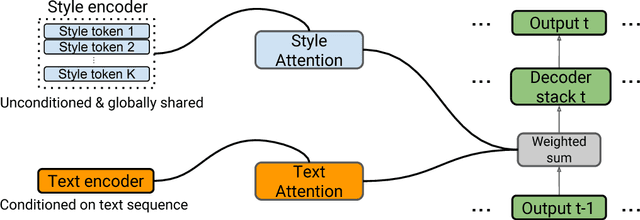
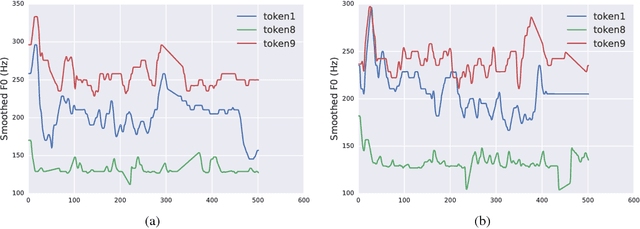
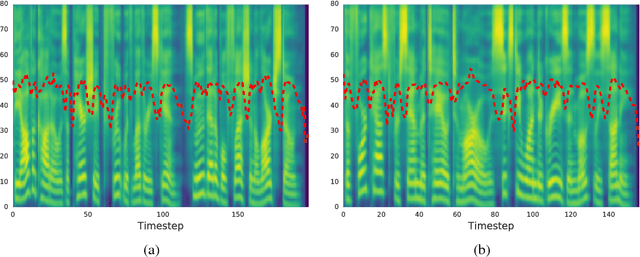
Prosodic modeling is a core problem in speech synthesis. The key challenge is producing desirable prosody from textual input containing only phonetic information. In this preliminary study, we introduce the concept of "style tokens" in Tacotron, a recently proposed end-to-end neural speech synthesis model. Using style tokens, we aim to extract independent prosodic styles from training data. We show that without annotation data or an explicit supervision signal, our approach can automatically learn a variety of prosodic variations in a purely data-driven way. Importantly, each style token corresponds to a fixed style factor regardless of the given text sequence. As a result, we can control the prosodic style of synthetic speech in a somewhat predictable and globally consistent way.
Full Resolution Image Compression with Recurrent Neural Networks
Jul 07, 2017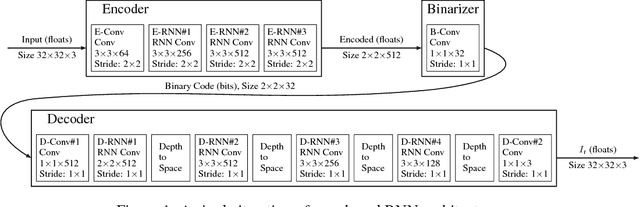
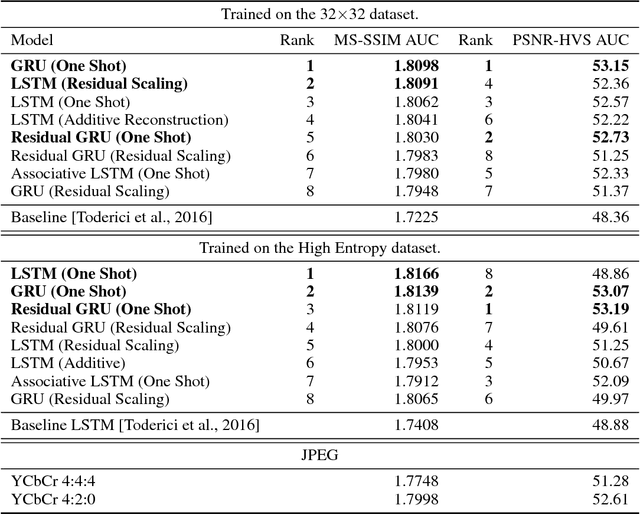
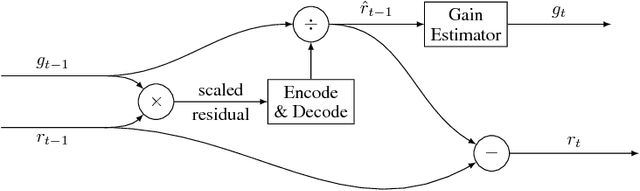
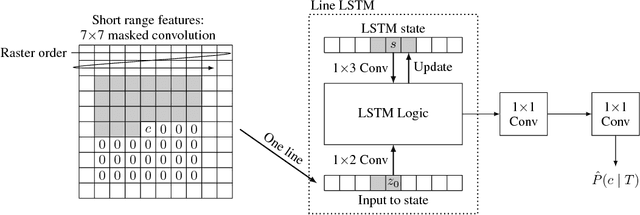
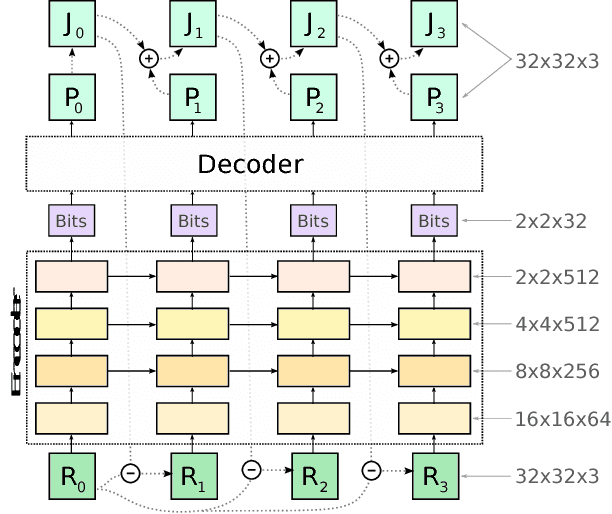
This paper presents a set of full-resolution lossy image compression methods based on neural networks. Each of the architectures we describe can provide variable compression rates during deployment without requiring retraining of the network: each network need only be trained once. All of our architectures consist of a recurrent neural network (RNN)-based encoder and decoder, a binarizer, and a neural network for entropy coding. We compare RNN types (LSTM, associative LSTM) and introduce a new hybrid of GRU and ResNet. We also study "one-shot" versus additive reconstruction architectures and introduce a new scaled-additive framework. We compare to previous work, showing improvements of 4.3%-8.8% AUC (area under the rate-distortion curve), depending on the perceptual metric used. As far as we know, this is the first neural network architecture that is able to outperform JPEG at image compression across most bitrates on the rate-distortion curve on the Kodak dataset images, with and without the aid of entropy coding.
Target-Quality Image Compression with Recurrent, Convolutional Neural Networks
May 18, 2017
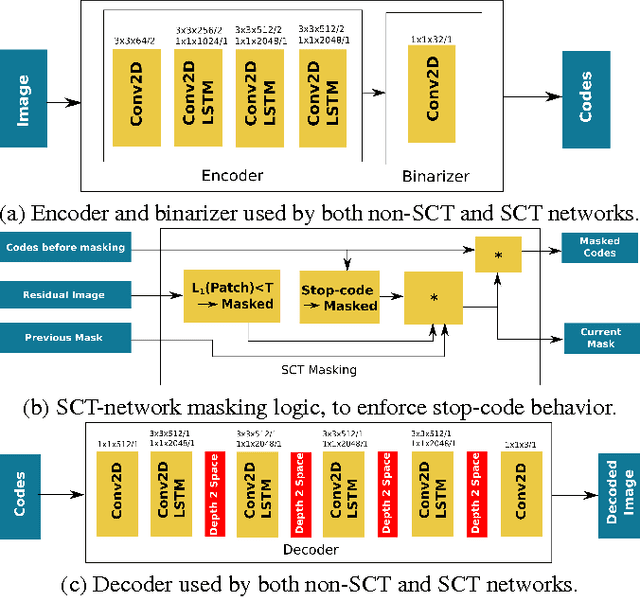
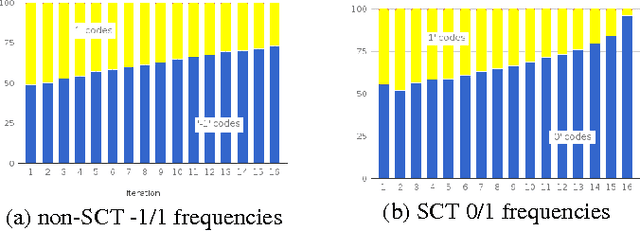

We introduce a stop-code tolerant (SCT) approach to training recurrent convolutional neural networks for lossy image compression. Our methods introduce a multi-pass training method to combine the training goals of high-quality reconstructions in areas around stop-code masking as well as in highly-detailed areas. These methods lead to lower true bitrates for a given recursion count, both pre- and post-entropy coding, even using unstructured LZ77 code compression. The pre-LZ77 gains are achieved by trimming stop codes. The post-LZ77 gains are due to the highly unequal distributions of 0/1 codes from the SCT architectures. With these code compressions, the SCT architecture maintains or exceeds the image quality at all compression rates compared to JPEG and to RNN auto-encoders across the Kodak dataset. In addition, the SCT coding results in lower variance in image quality across the extent of the image, a characteristic that has been shown to be important in human ratings of image quality
Improved Lossy Image Compression with Priming and Spatially Adaptive Bit Rates for Recurrent Networks
Mar 29, 2017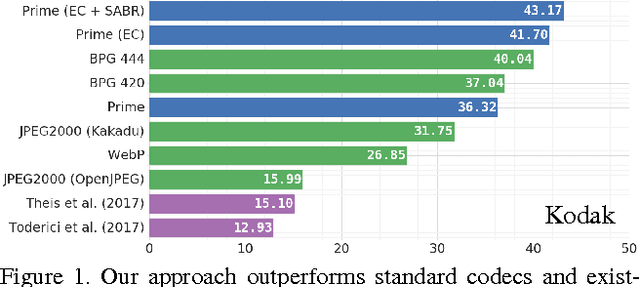

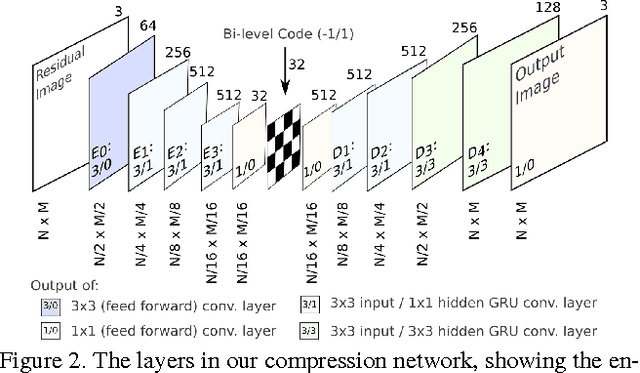
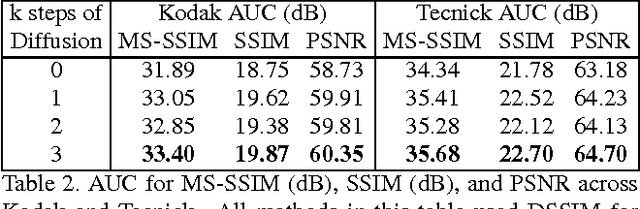
We propose a method for lossy image compression based on recurrent, convolutional neural networks that outperforms BPG (4:2:0 ), WebP, JPEG2000, and JPEG as measured by MS-SSIM. We introduce three improvements over previous research that lead to this state-of-the-art result. First, we show that training with a pixel-wise loss weighted by SSIM increases reconstruction quality according to several metrics. Second, we modify the recurrent architecture to improve spatial diffusion, which allows the network to more effectively capture and propagate image information through the network's hidden state. Finally, in addition to lossless entropy coding, we use a spatially adaptive bit allocation algorithm to more efficiently use the limited number of bits to encode visually complex image regions. We evaluate our method on the Kodak and Tecnick image sets and compare against standard codecs as well recently published methods based on deep neural networks.