 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleGAN-Based Unpaired Speech Dereverberation
Mar 29, 2022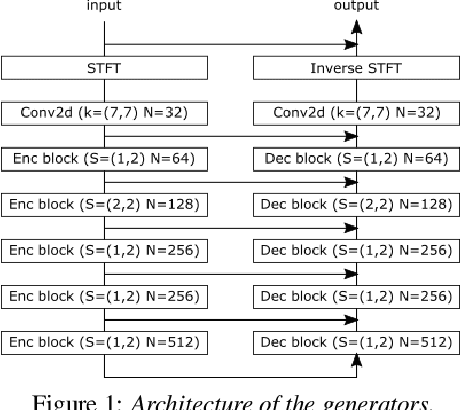

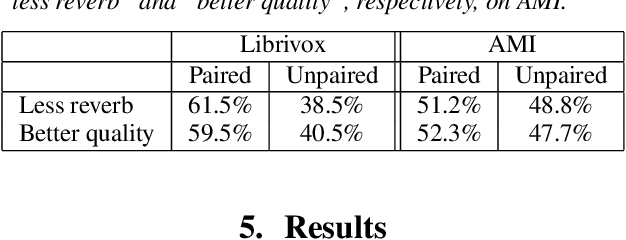
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.
Towards Learning a Universal Non-Semantic Representation of Speech
Mar 02, 2020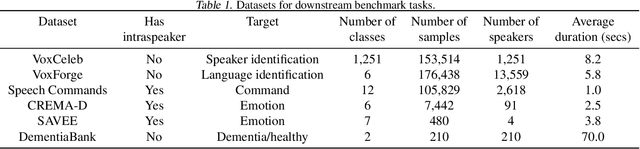
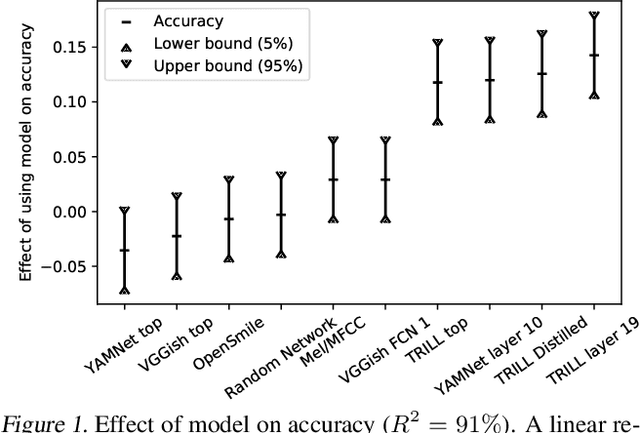
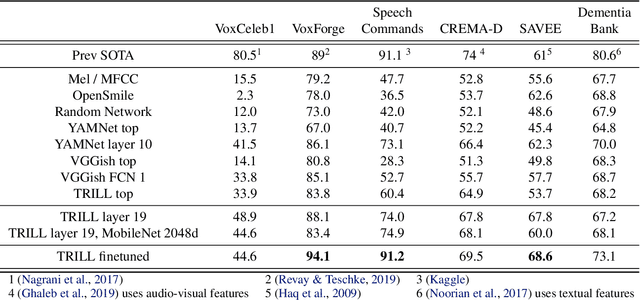
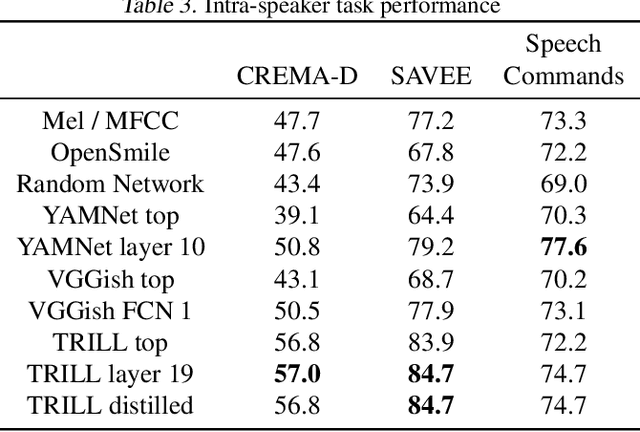
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.