 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Need for Medically Aware Video Compression in Gastroenterology
Nov 02, 2022



Compression is essential to storing and transmitting medical videos, but the effect of compression on downstream medical tasks is often ignored. Furthermore, systems in practice rely on standard video codecs, which naively allocate bits between medically relevant frames or parts of frames. In this work, we present an empirical study of some deficiencies of classical codecs on gastroenterology videos, and motivate our ongoing work to train a learned compression model for colonoscopy videos. We show that two of the most common classical codecs, H264 and HEVC, compress medically relevant frames statistically significantly worse than medically nonrelevant ones, and that polyp detector performance degrades rapidly as compression increases. We explain how a learned compressor could allocate bits to important regions and allow detection performance to degrade more gracefully. Many of our proposed techniques generalize to medical video domains beyond gastroenterology
LVAC: Learned Volumetric Attribute Compression for Point Clouds using Coordinate Based Networks
Nov 17, 2021
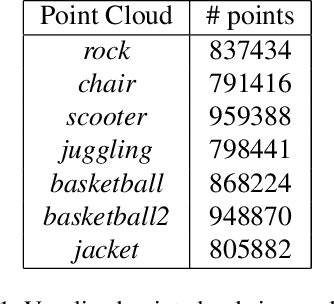
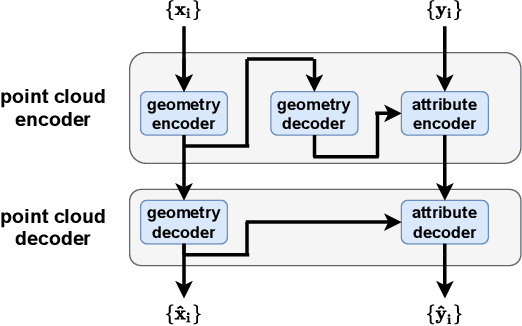
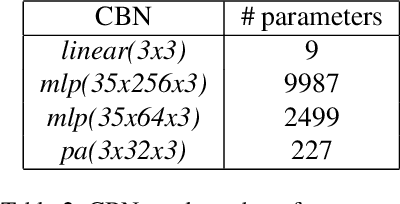
We consider the attributes of a point cloud as samples of a vector-valued volumetric function at discrete positions. To compress the attributes given the positions, we compress the parameters of the volumetric function. We model the volumetric function by tiling space into blocks, and representing the function over each block by shifts of a coordinate-based, or implicit, neural network. Inputs to the network include both spatial coordinates and a latent vector per block. We represent the latent vectors using coefficients of the region-adaptive hierarchical transform (RAHT) used in the MPEG geometry-based point cloud codec G-PCC. The coefficients, which are highly compressible, are rate-distortion optimized by back-propagation through a rate-distortion Lagrangian loss in an auto-decoder configuration. The result outperforms RAHT by 2--4 dB. This is the first work to compress volumetric functions represented by local coordinate-based neural networks. As such, we expect it to be applicable beyond point clouds, for example to compression of high-resolution neural radiance fields.
Towards Generative Video Compression
Jul 26, 2021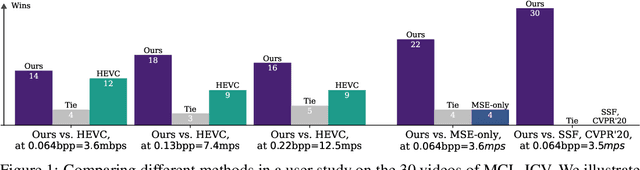
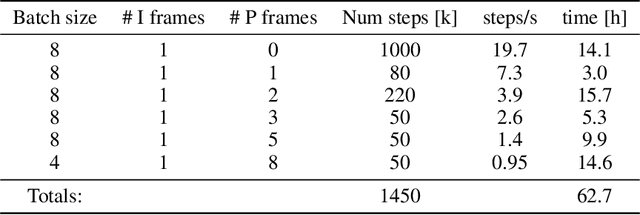
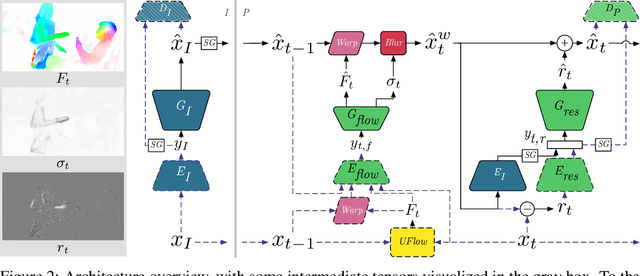
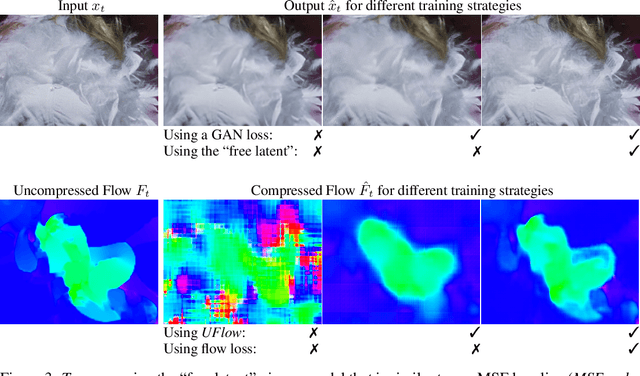
We present a neural video compression method based on generative adversarial networks (GANs) that outperforms previous neural video compression methods and is comparable to HEVC in a user study. We propose a technique to mitigate temporal error accumulation caused by recursive frame compression that uses randomized shifting and un-shifting, motivated by a spectral analysis. We present in detail the network design choices, their relative importance, and elaborate on the challenges of evaluating video compression methods in user studies.
End-to-end Learning of Compressible Features
Jul 23, 2020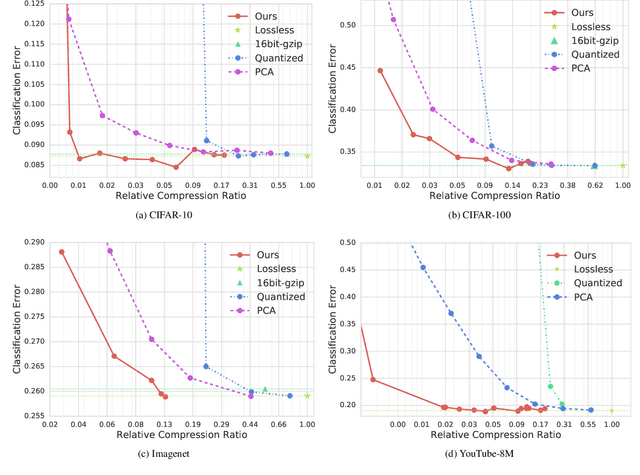
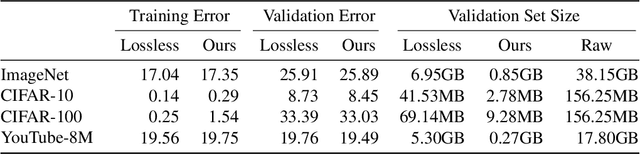
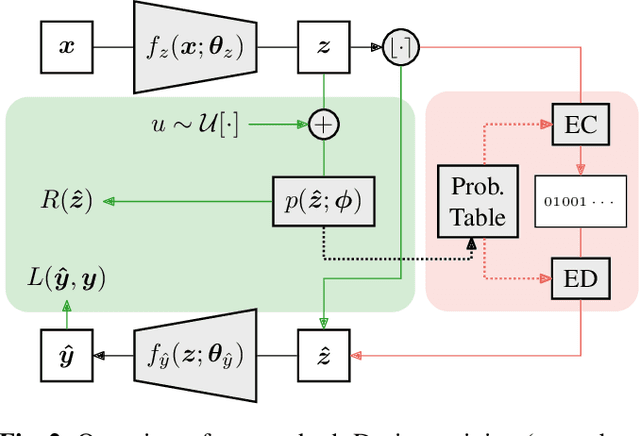
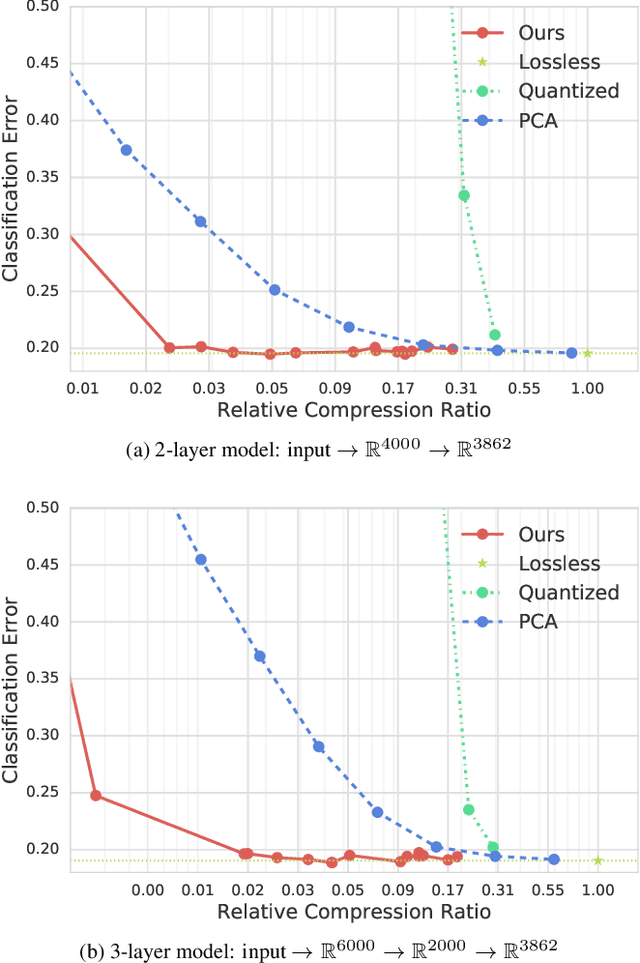
Pre-trained convolutional neural networks (CNNs) are powerful off-the-shelf feature generators and have been shown to perform very well on a variety of tasks. Unfortunately, the generated features are high dimensional and expensive to store: potentially hundreds of thousands of floats per example when processing videos. Traditional entropy based lossless compression methods are of little help as they do not yield desired level of compression, while general purpose lossy compression methods based on energy compaction (e.g. PCA followed by quantization and entropy coding) are sub-optimal, as they are not tuned to task specific objective. We propose a learned method that jointly optimizes for compressibility along with the task objective for learning the features. The plug-in nature of our method makes it straight-forward to integrate with any target objective and trade-off against compressibility. We present results on multiple benchmarks and demonstrate that our method produces features that are an order of magnitude more compressible, while having a regularization effect that leads to a consistent improvement in accuracy.
Computationally Efficient Neural Image Compression
Dec 18, 2019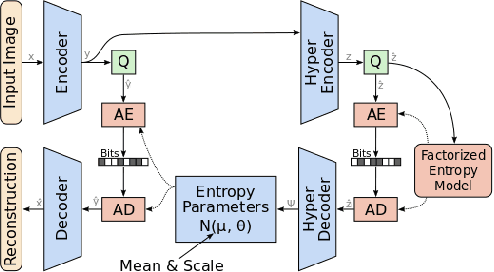


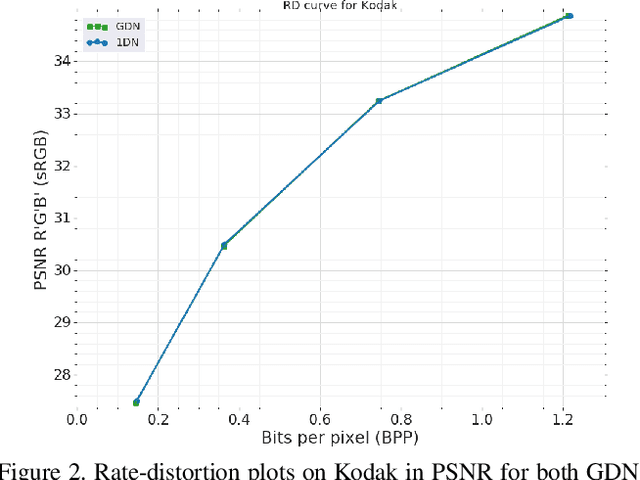
Image compression using neural networks have reached or exceeded non-neural methods (such as JPEG, WebP, BPG). While these networks are state of the art in ratedistortion performance, computational feasibility of these models remains a challenge. We apply automatic network optimization techniques to reduce the computational complexity of a popular architecture used in neural image compression, analyze the decoder complexity in execution runtime and explore the trade-offs between two distortion metrics, rate-distortion performance and run-time performance to design and research more computationally efficient neural image compression. We find that our method decreases the decoder run-time requirements by over 50% for a stateof-the-art neural architecture.
Table-Based Neural Units: Fully Quantizing Networks for Multiply-Free Inference
Jun 11, 2019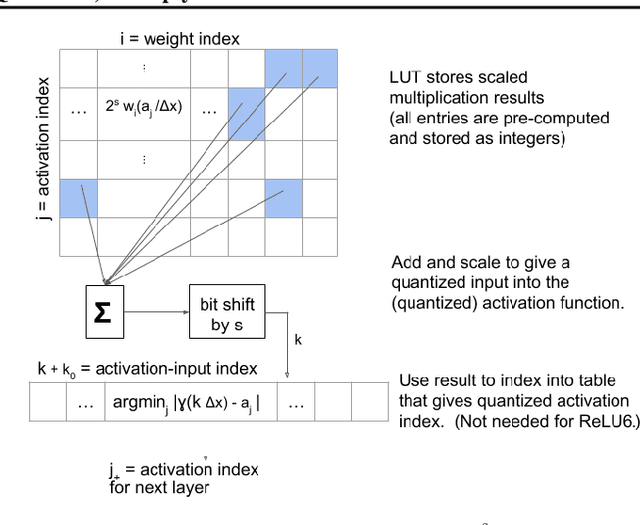
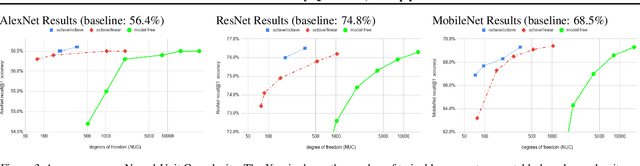
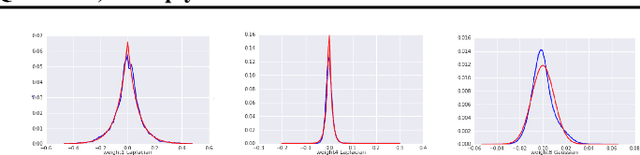
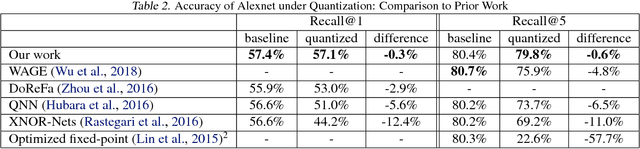
In this work, we propose to quantize all parts of standard classification networks and replace the activation-weight--multiply step with a simple table-based lookup. This approach results in networks that are free of floating-point operations and free of multiplications, suitable for direct FPGA and ASIC implementations. It also provides us with two simple measures of per-layer and network-wide compactness as well as insight into the distribution characteristics of activationoutput and weight values. We run controlled studies across different quantization schemes, both fixed and adaptive and, within the set of adaptive approaches, both parametric and model-free. We implement our approach to quantization with minimal, localized changes to the training process, allowing us to benefit from advances in training continuous-valued network architectures. We apply our approach successfully to AlexNet, ResNet, and MobileNet. We show results that are within 1.6% of the reported, non-quantized performance on MobileNet using only 40 entries in our table. This performance gap narrows to zero when we allow tables with 320 entries. Our results give the best accuracies among multiply-free networks.
Neural Image Decompression: Learning to Render Better Image Previews
Dec 06, 2018
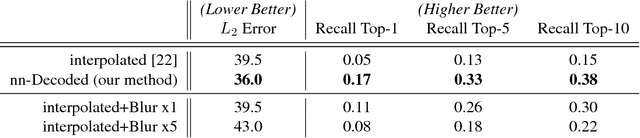


A rapidly increasing portion of Internet traffic is dominated by requests from mobile devices with limited- and metered-bandwidth constraints. To satisfy these requests, it has become standard practice for websites to transmit small and extremely compressed image previews as part of the initial page-load process. Recent work, based on an adaptive triangulation of the target image, has shown the ability to generate thumbnails of full images at extreme compression rates: 200 bytes or less with impressive gains (in terms of PSNR and SSIM) over both JPEG and WebP standards. However, qualitative assessments and preservation of semantic content can be less favorable. We present a novel method to significantly improve the reconstruction quality of the original image with no changes to the encoded information. Our neural-based decoding not only achieves higher PSNR and SSIM scores than the original methods, but also yields a substantial increase in semantic-level content preservation. In addition, by keeping the same encoding stream, our solution is completely inter-operable with the original decoder. The end result is suitable for a range of small-device deployments, as it involves only a single forward-pass through a small, scalable network.
No Multiplication? No Floating Point? No Problem! Training Networks for Efficient Inference
Sep 28, 2018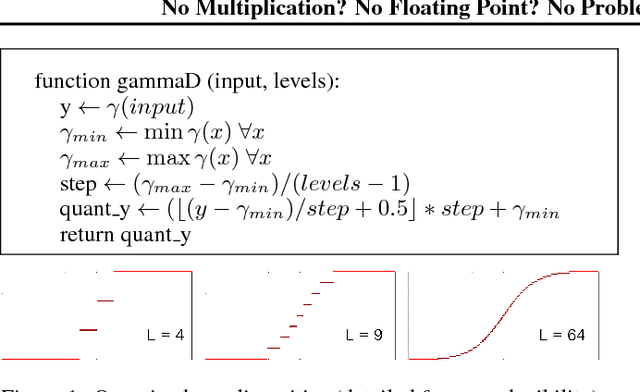
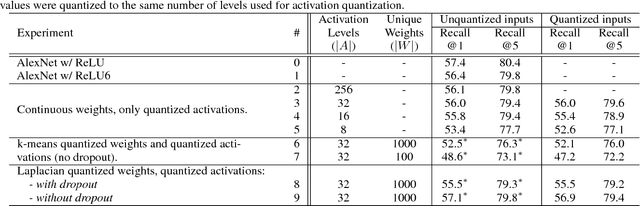
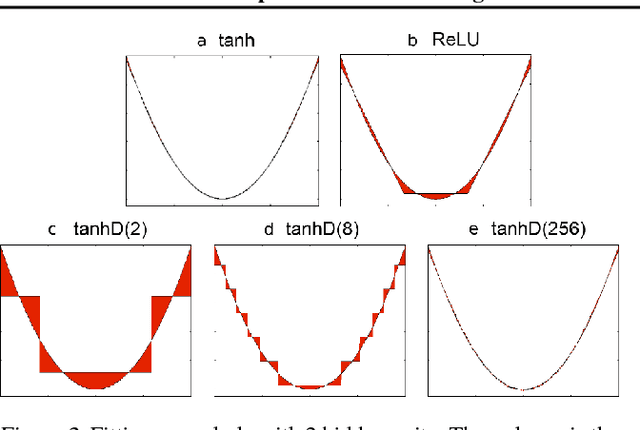
For successful deployment of deep neural networks on highly--resource-constrained devices (hearing aids, earbuds, wearables), we must simplify the types of operations and the memory/power resources used during inference. Completely avoiding inference-time floating-point operations is one of the simplest ways to design networks for these highly-constrained environments. By discretizing both our in-network non-linearities and our network weights, we can move to simple, compact networks without floating point operations, without multiplications, and avoid all non-linear function computations. Our approach allows us to explore the spectrum of possible networks, ranging from fully continuous versions down to networks with bi-level weights and activations. Our results show that discretization can be done without loss of performance and that we can train a network that will successfully operate without floating-point, without multiplication, and with less RAM on both regression tasks (auto encoding) and multi-class classification tasks (ImageNet). The memory needed to deploy our discretized networks is less than one third of the equivalent architecture that does use floating-point operations.
Towards a Semantic Perceptual Image Metric
Aug 01, 2018
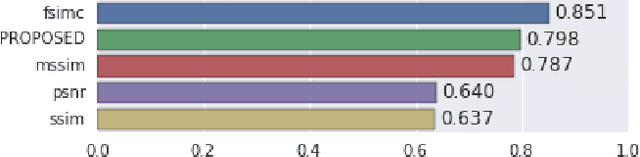
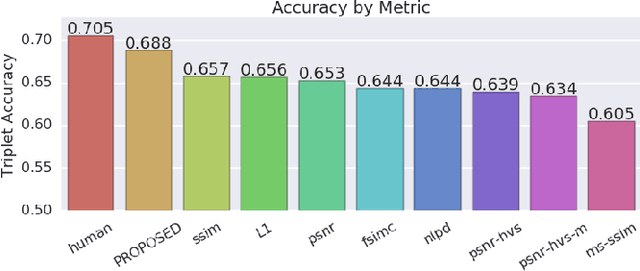

We present a full reference, perceptual image metric based on VGG-16, an artificial neural network trained on object classification. We fit the metric to a new database based on 140k unique images annotated with ground truth by human raters who received minimal instruction. The resulting metric shows competitive performance on TID 2013, a database widely used to assess image quality assessments methods. More interestingly, it shows strong responses to objects potentially carrying semantic relevance such as faces and text, which we demonstrate using a visualization technique and ablation experiments. In effect, the metric appears to model a higher influence of semantic context on judgments, which we observe particularly in untrained raters. As the vast majority of users of image processing systems are unfamiliar with Image Quality Assessment (IQA) tasks, these findings may have significant impact on real-world applications of perceptual metrics.
Spatially adaptive image compression using a tiled deep network
Feb 07, 2018
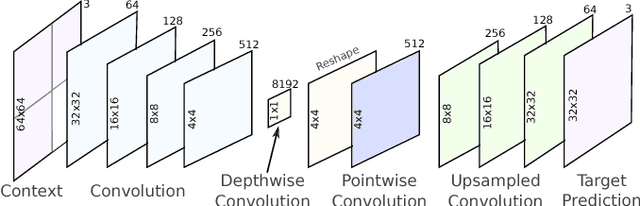

Deep neural networks represent a powerful class of function approximators that can learn to compress and reconstruct images. Existing image compression algorithms based on neural networks learn quantized representations with a constant spatial bit rate across each image. While entropy coding introduces some spatial variation, traditional codecs have benefited significantly by explicitly adapting the bit rate based on local image complexity and visual saliency. This paper introduces an algorithm that combines deep neural networks with quality-sensitive bit rate adaptation using a tiled network. We demonstrate the importance of spatial context prediction and show improved quantitative (PSNR) and qualitative (subjective rater assessment) results compared to a non-adaptive baseline and a recently published image compression model based on fully-convolutional neural networks.