 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Isometric Learning for Visual Recognition
Jun 30, 2020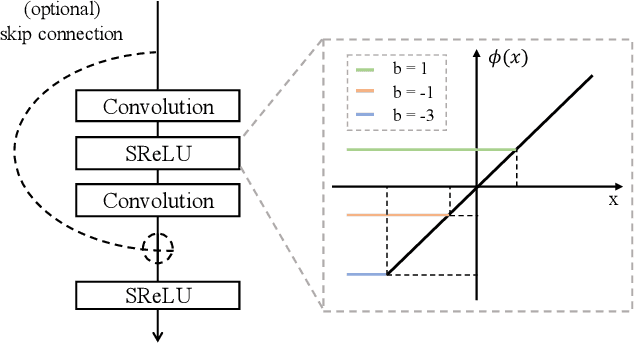
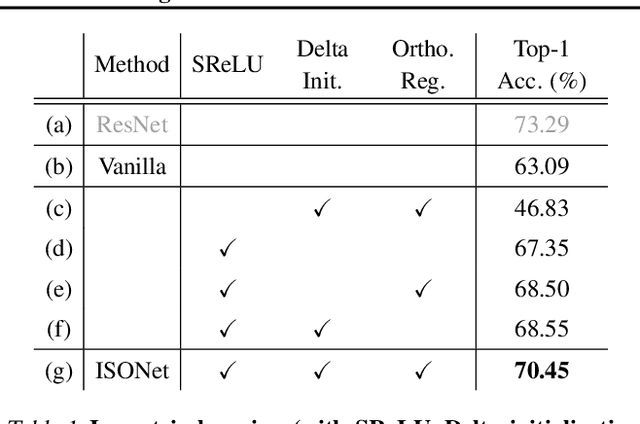
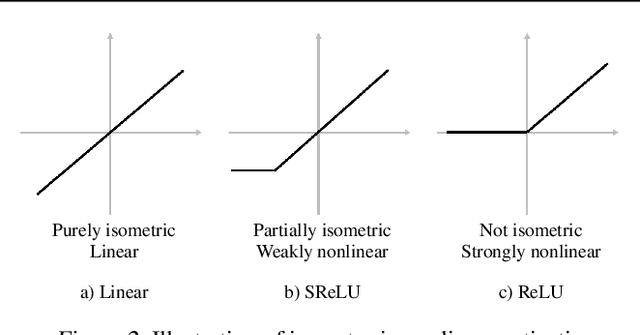
Initialization, normalization, and skip connections are believed to be three indispensable techniques for training very deep convolutional neural networks and obtaining state-of-the-art performance. This paper shows that deep vanilla ConvNets without normalization nor skip connections can also be trained to achieve surprisingly good performance on standard image recognition benchmarks. This is achieved by enforcing the convolution kernels to be near isometric during initialization and training, as well as by using a variant of ReLU that is shifted towards being isometric. Further experiments show that if combined with skip connections, such near isometric networks can achieve performances on par with (for ImageNet) and better than (for COCO) the standard ResNet, even without normalization at all. Our code is available at https://github.com/HaozhiQi/ISONet.
Robust Learning Through Cross-Task Consistency
Jun 07, 2020
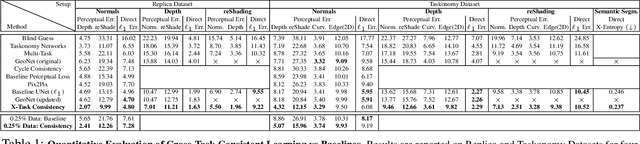
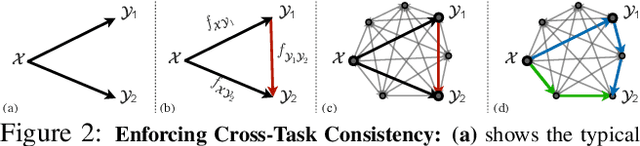
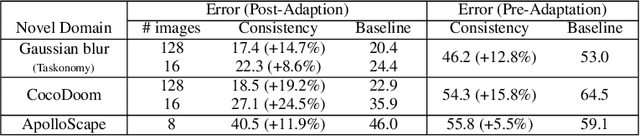
Visual perception entails solving a wide set of tasks, e.g., object detection, depth estimation, etc. The predictions made for multiple tasks from the same image are not independent, and therefore, are expected to be consistent. We propose a broadly applicable and fully computational method for augmenting learning with Cross-Task Consistency. The proposed formulation is based on inference-path invariance over a graph of arbitrary tasks. We observe that learning with cross-task consistency leads to more accurate predictions and better generalization to out-of-distribution inputs. This framework also leads to an informative unsupervised quantity, called Consistency Energy, based on measuring the intrinsic consistency of the system. Consistency Energy correlates well with the supervised error (r=0.67), thus it can be employed as an unsupervised confidence metric as well as for detection of out-of-distribution inputs (ROC-AUC=0.95). The evaluations are performed on multiple datasets, including Taskonomy, Replica, CocoDoom, and ApolloScape, and they benchmark cross-task consistency versus various baselines including conventional multi-task learning, cycle consistency, and analytical consistency.
Inclusive GAN: Improving Data and Minority Coverage in Generative Models
Apr 12, 2020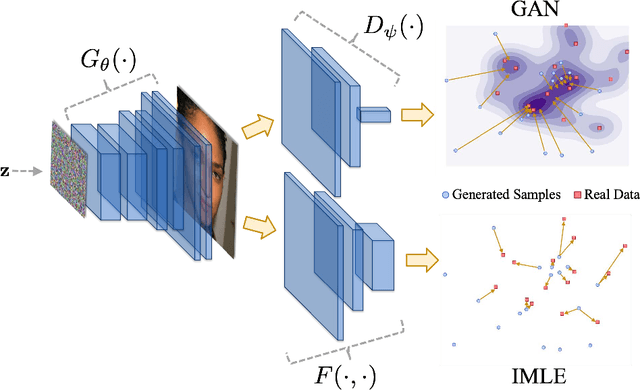

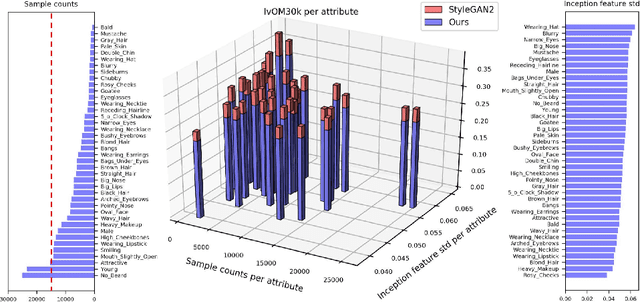
Generative Adversarial Networks (GANs) have brought about rapid progress towards generating photorealistic images. Yet the equitable allocation of their modeling capacity among subgroups has received less attention, which could lead to potential biases against underrepresented minorities if left uncontrolled. In this work, we first formalize the problem of minority inclusion as one of data coverage, and then propose to improve data coverage by harmonizing adversarial training with reconstructive generation. The experiments show that our method outperforms the existing state-of-the-art methods in terms of data coverage on both seen and unseen data. We develop an extension that allows explicit control over the minority subgroups that the model should ensure to include, and validate its effectiveness at little compromise from the overall performance on the entire dataset. Code, models, and supplemental videos are available at GitHub.
State-Only Imitation Learning for Dexterous Manipulation
Apr 07, 2020
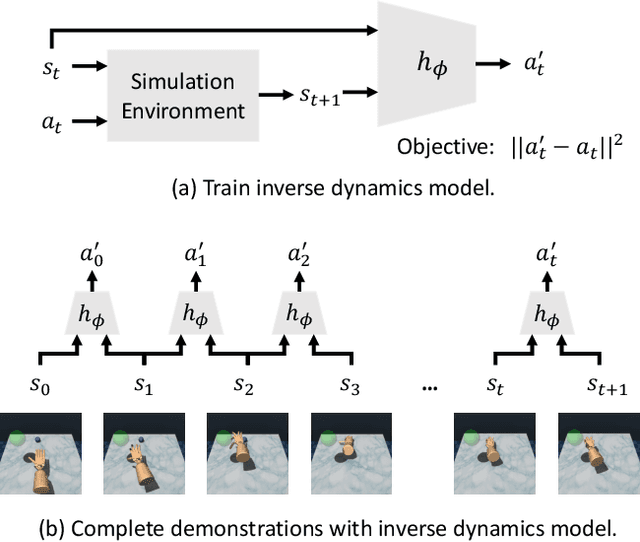

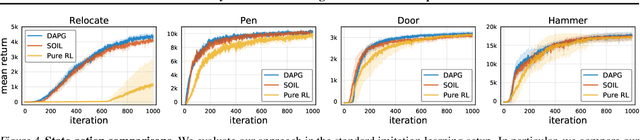
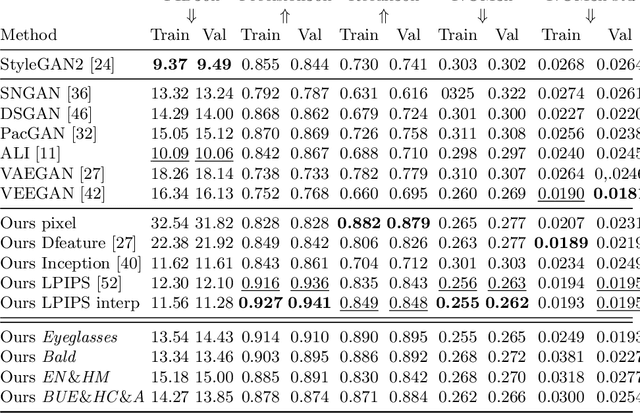
Dexterous manipulation has been a long-standing challenge in robotics. Recently, modern model-free RL has demonstrated impressive results on a number of problems. However, complex domains like dexterous manipulation remain a challenge for RL due to the poor sample complexity. To address this, current approaches employ expert demonstrations in the form of state-action pairs, which are difficult to obtain for real-world settings such as learning from videos. In this work, we move toward a more realistic setting and explore state-only imitation learning. To tackle this setting, we train an inverse dynamics model and use it to predict actions for state-only demonstrations. The inverse dynamics model and the policy are trained jointly. Our method performs on par with state-action approaches and considerably outperforms RL alone. By not relying on expert actions, we are able to learn from demonstrations with different dynamics, morphologies, and objects.
Multimodal Image Synthesis with Conditional Implicit Maximum Likelihood Estimation
Apr 07, 2020



Many tasks in computer vision and graphics fall within the framework of conditional image synthesis. In recent years, generative adversarial nets (GANs) have delivered impressive advances in quality of synthesized images. However, it remains a challenge to generate both diverse and plausible images for the same input, due to the problem of mode collapse. In this paper, we develop a new generic multimodal conditional image synthesis method based on Implicit Maximum Likelihood Estimation (IMLE) and demonstrate improved multimodal image synthesis performance on two tasks, single image super-resolution and image synthesis from scene layouts. We make our implementation publicly available.
It Is Not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction
Apr 04, 2020

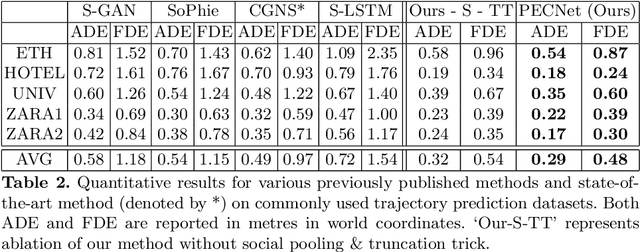
Human trajectory forecasting with multiple socially interacting agents is of critical importance for autonomous navigation in human environments, e.g., for self-driving cars and social robots. In this work, we present Predicted Endpoint Conditioned Network (PECNet) for flexible human trajectory prediction. PECNet infers distant trajectory endpoints to assist in long-range multi-modal trajectory prediction. A novel non-local social pooling layer enables PECNet to infer diverse yet socially compliant trajectories. Additionally, we present a simple "truncation-trick" for improving few-shot multi-modal trajectory prediction performance. We show that PECNet improves state-of-the-art performance on the Stanford Drone trajectory prediction benchmark by ~19.5% and on the ETH/UCY benchmark by ~40.8%.
Audiovisual SlowFast Networks for Video Recognition
Jan 23, 2020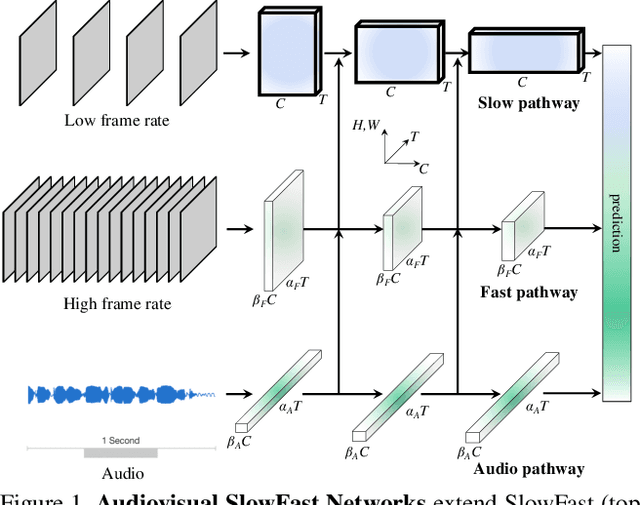
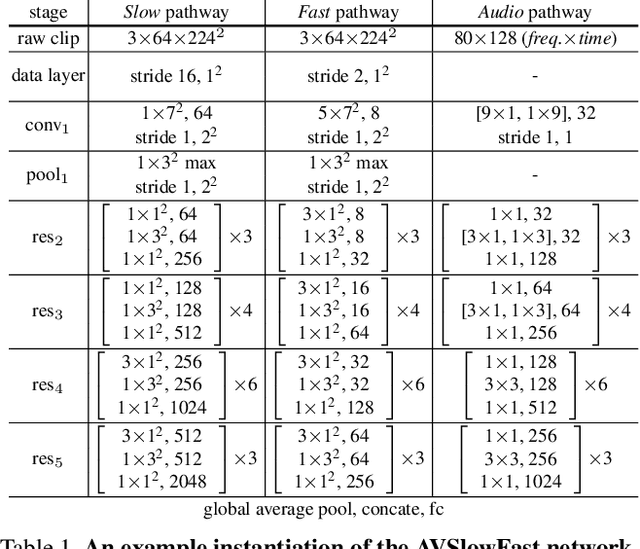
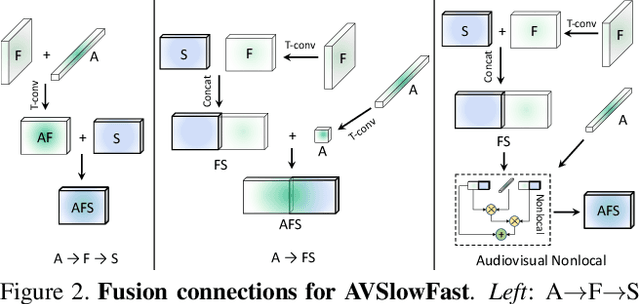
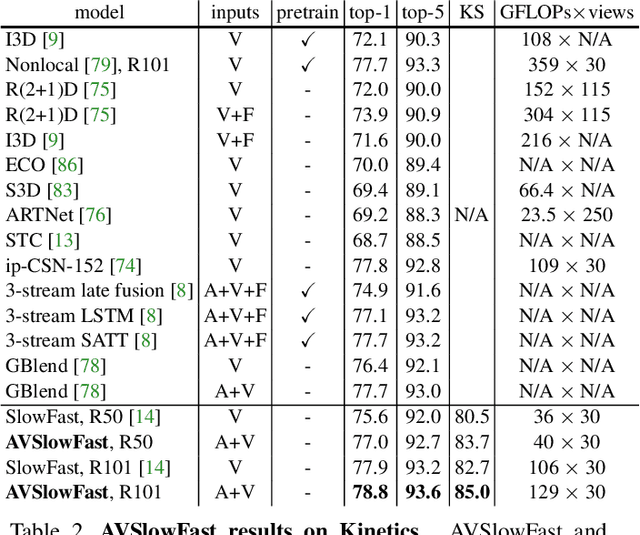
We present Audiovisual SlowFast Networks, an architecture for integrated audiovisual perception. AVSlowFast extends SlowFast Networks with a Faster Audio pathway that is deeply integrated with its visual counterparts. We fuse audio and visual features at multiple layers, enabling audio to contribute to the formation of hierarchical audiovisual concepts. To overcome training difficulties that arise from different learning dynamics for audio and visual modalities, we employ DropPathway that randomly drops the Audio pathway during training as a simple and effective regularization technique. Inspired by prior studies in neuroscience, we perform hierarchical audiovisual synchronization and show that it leads to better audiovisual features. We report state-of-the-art results on four video action classification and detection datasets, perform detailed ablation studies, and show the generalization of AVSlowFast to self-supervised tasks, where it improves over prior work. Code will be made available at: https://github.com/facebookresearch/SlowFast.
Side-Tuning: Network Adaptation via Additive Side Networks
Dec 31, 2019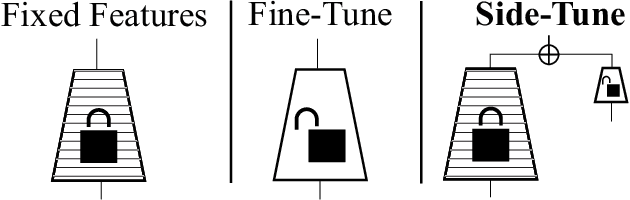

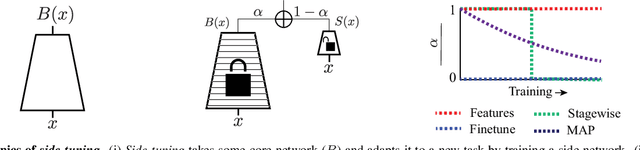
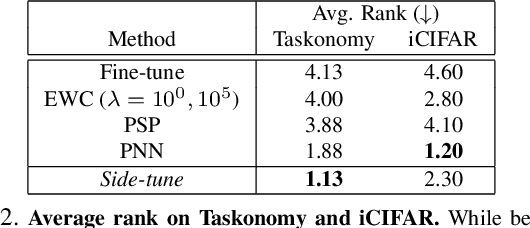
When training a neural network for a desired task, one may prefer to adapt a pre-trained network rather than start with a randomly initialized one -- due to lacking enough training data, performing lifelong learning where the system has to learn a new task while being previously trained for other tasks, or wishing to encode priors in the network via preset weights. The most commonly employed approaches for network adaptation are fine-tuning and using the pre-trained network as a fixed feature extractor, among others. In this paper, we propose a straightforward alternative: Side-Tuning. Side-tuning adapts a pre-trained network by training a lightweight "side" network that is fused with the (unchanged) pre-trained network using summation. This simple method works as well as or better than existing solutions while it resolves some of the basic issues with fine-tuning, fixed features, and several other common baselines. In particular, side-tuning is less prone to overfitting when little training data is available, yields better results than using a fixed feature extractor, and does not suffer from catastrophic forgetting in lifelong learning. We demonstrate the performance of side-tuning under a diverse set of scenarios, including lifelong learning (iCIFAR, Taskonomy), reinforcement learning, imitation learning (visual navigation in Habitat), NLP question-answering (SQuAD v2), and single-task transfer learning (Taskonomy), with consistently promising results.
Learning to Navigate Using Mid-Level Visual Priors
Dec 23, 2019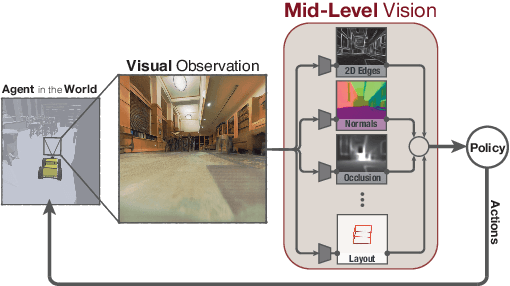
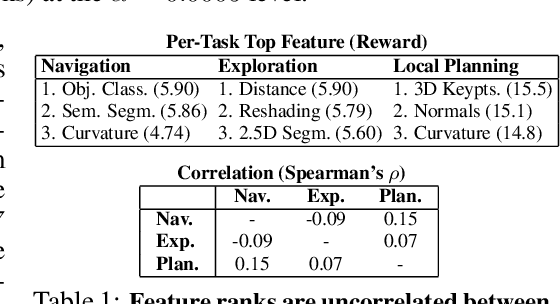
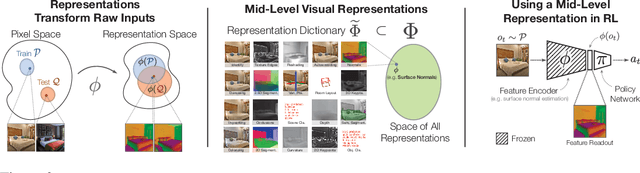

How much does having visual priors about the world (e.g. the fact that the world is 3D) assist in learning to perform downstream motor tasks (e.g. navigating a complex environment)? What are the consequences of not utilizing such visual priors in learning? We study these questions by integrating a generic perceptual skill set (a distance estimator, an edge detector, etc.) within a reinforcement learning framework (see Fig. 1). This skill set ("mid-level vision") provides the policy with a more processed state of the world compared to raw images. Our large-scale study demonstrates that using mid-level vision results in policies that learn faster, generalize better, and achieve higher final performance, when compared to learning from scratch and/or using state-of-the-art visual and non-visual representation learning methods. We show that conventional computer vision objectives are particularly effective in this regard and can be conveniently integrated into reinforcement learning frameworks. Finally, we found that no single visual representation was universally useful for all downstream tasks, hence we computationally derive a task-agnostic set of representations optimized to support arbitrary downstream tasks.
3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera
Oct 06, 2019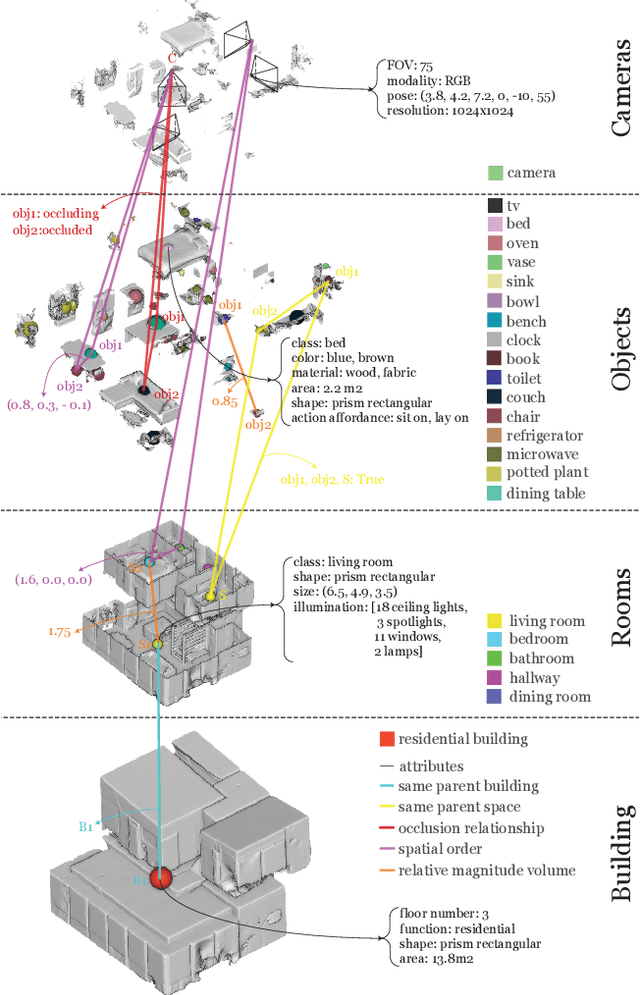

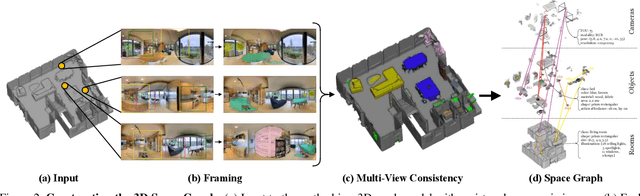
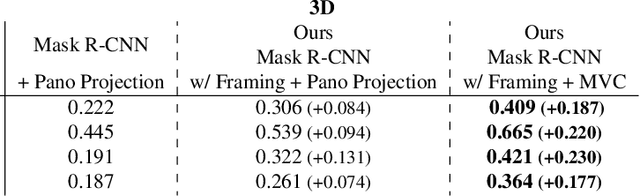
A comprehensive semantic understanding of a scene is important for many applications - but in what space should diverse semantic information (e.g., objects, scene categories, material types, texture, etc.) be grounded and what should be its structure? Aspiring to have one unified structure that hosts diverse types of semantics, we follow the Scene Graph paradigm in 3D, generating a 3D Scene Graph. Given a 3D mesh and registered panoramic images, we construct a graph that spans the entire building and includes semantics on objects (e.g., class, material, and other attributes), rooms (e.g., scene category, volume, etc.) and cameras (e.g., location, etc.), as well as the relationships among these entities. However, this process is prohibitively labor heavy if done manually. To alleviate this we devise a semi-automatic framework that employs existing detection methods and enhances them using two main constraints: I. framing of query images sampled on panoramas to maximize the performance of 2D detectors, and II. multi-view consistency enforcement across 2D detections that originate in different camera locations.