 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Stereopsis: Meshes from multiple views using differentiable rendering
Oct 11, 2021
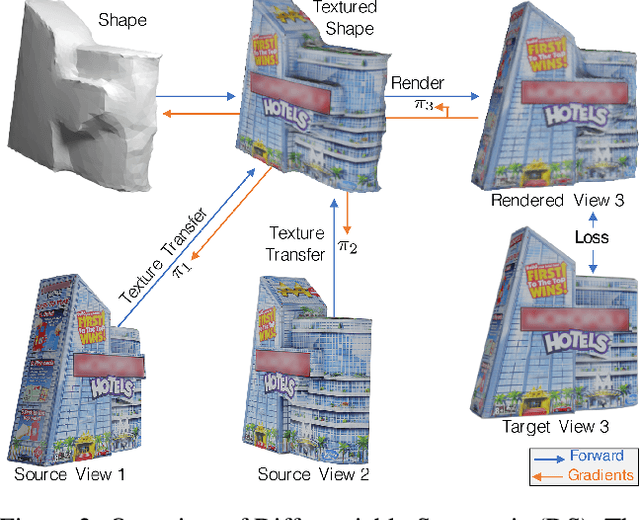
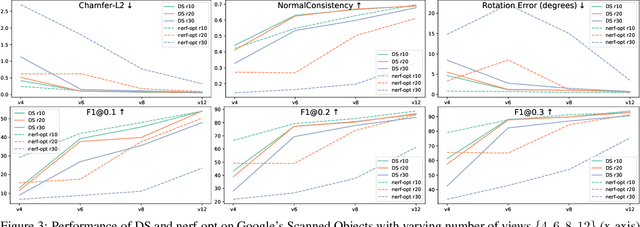

We propose Differentiable Stereopsis, a multi-view stereo approach that reconstructs shape and texture from few input views and noisy cameras. We pair traditional stereopsis and modern differentiable rendering to build an end-to-end model which predicts textured 3D meshes of objects with varying topologies and shape. We frame stereopsis as an optimization problem and simultaneously update shape and cameras via simple gradient descent. We run an extensive quantitative analysis and compare to traditional multi-view stereo techniques and state-of-the-art learning based methods. We show compelling reconstructions on challenging real-world scenes and for an abundance of object types with complex shape, topology and texture. Project webpage: https://shubham-goel.github.io/ds/
Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets from 3D Scans
Oct 11, 2021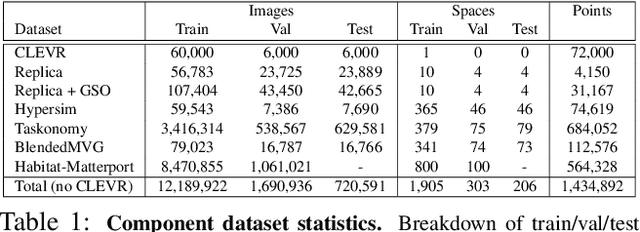
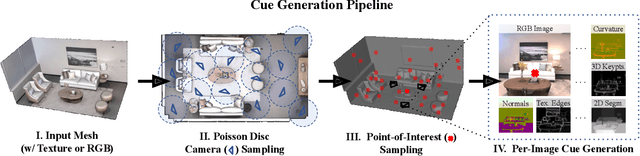
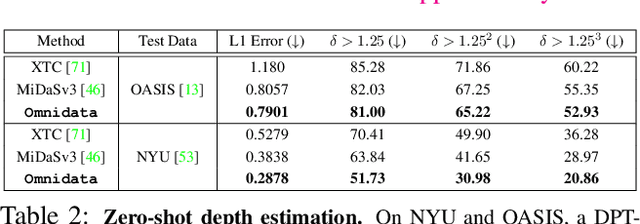
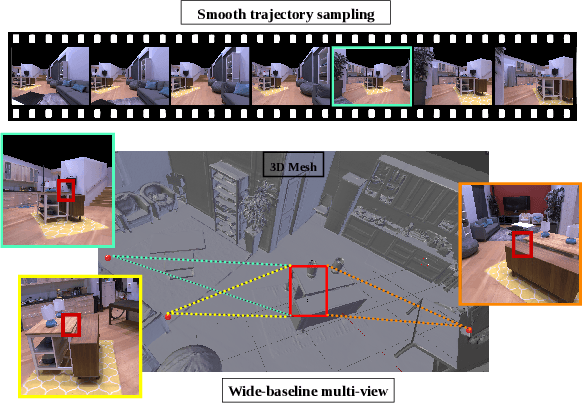
This paper introduces a pipeline to parametrically sample and render multi-task vision datasets from comprehensive 3D scans from the real world. Changing the sampling parameters allows one to "steer" the generated datasets to emphasize specific information. In addition to enabling interesting lines of research, we show the tooling and generated data suffice to train robust vision models. Common architectures trained on a generated starter dataset reached state-of-the-art performance on multiple common vision tasks and benchmarks, despite having seen no benchmark or non-pipeline data. The depth estimation network outperforms MiDaS and the surface normal estimation network is the first to achieve human-level performance for in-the-wild surface normal estimation -- at least according to one metric on the OASIS benchmark. The Dockerized pipeline with CLI, the (mostly python) code, PyTorch dataloaders for the generated data, the generated starter dataset, download scripts and other utilities are available through our project website, https://omnidata.vision.
Active 3D Shape Reconstruction from Vision and Touch
Jul 20, 2021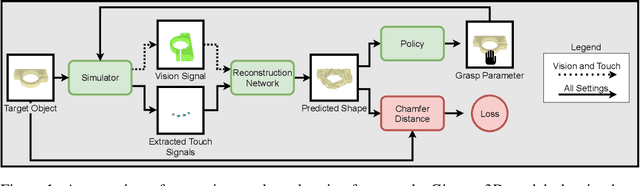
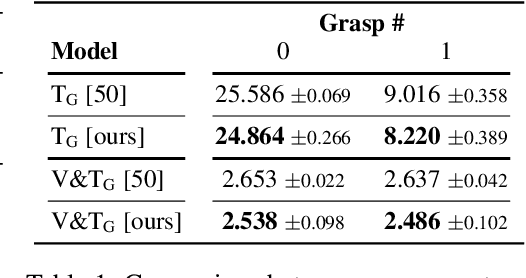
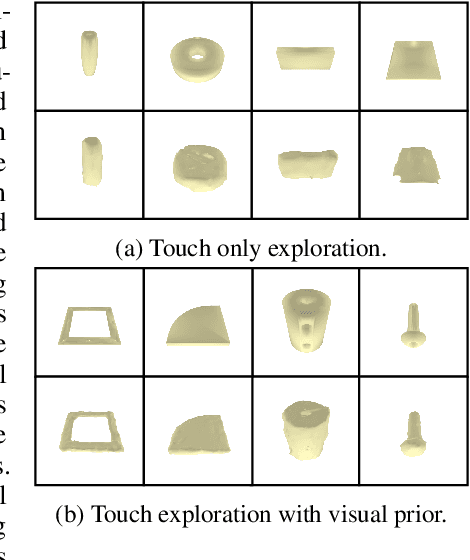
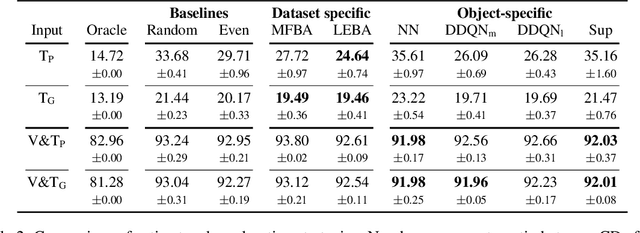
Humans build 3D understandings of the world through active object exploration, using jointly their senses of vision and touch. However, in 3D shape reconstruction, most recent progress has relied on static datasets of limited sensory data such as RGB images, depth maps or haptic readings, leaving the active exploration of the shape largely unexplored. In active touch sensing for 3D reconstruction, the goal is to actively select the tactile readings that maximize the improvement in shape reconstruction accuracy. However, the development of deep learning-based active touch models is largely limited by the lack of frameworks for shape exploration. In this paper, we focus on this problem and introduce a system composed of: 1) a haptic simulator leveraging high spatial resolution vision-based tactile sensors for active touching of 3D objects; 2) a mesh-based 3D shape reconstruction model that relies on tactile or visuotactile signals; and 3) a set of data-driven solutions with either tactile or visuotactile priors to guide the shape exploration. Our framework enables the development of the first fully data-driven solutions to active touch on top of learned models for object understanding. Our experiments show the benefits of such solutions in the task of 3D shape understanding where our models consistently outperform natural baselines. We provide our framework as a tool to foster future research in this direction.
RMA: Rapid Motor Adaptation for Legged Robots
Jul 08, 2021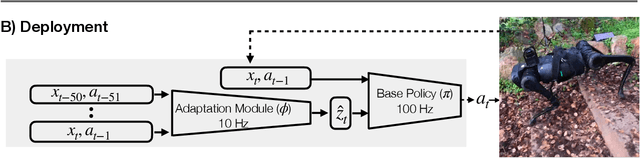
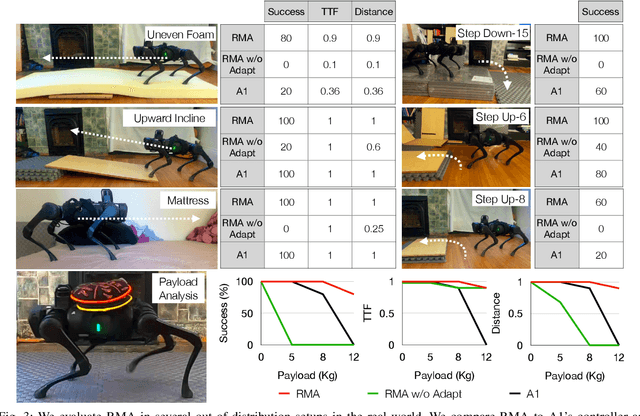
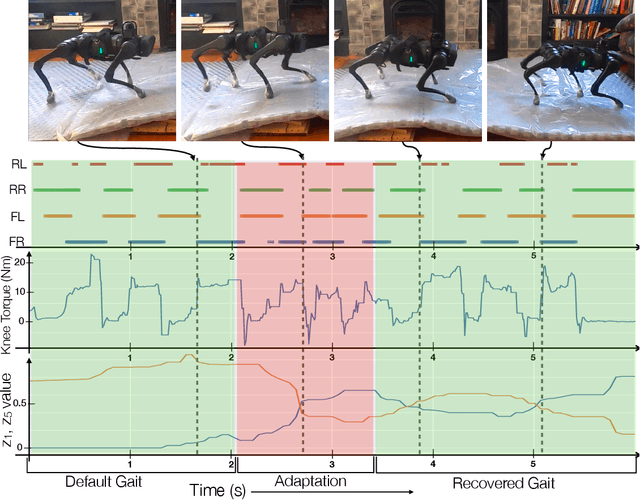
Successful real-world deployment of legged robots would require them to adapt in real-time to unseen scenarios like changing terrains, changing payloads, wear and tear. This paper presents Rapid Motor Adaptation (RMA) algorithm to solve this problem of real-time online adaptation in quadruped robots. RMA consists of two components: a base policy and an adaptation module. The combination of these components enables the robot to adapt to novel situations in fractions of a second. RMA is trained completely in simulation without using any domain knowledge like reference trajectories or predefined foot trajectory generators and is deployed on the A1 robot without any fine-tuning. We train RMA on a varied terrain generator using bioenergetics-inspired rewards and deploy it on a variety of difficult terrains including rocky, slippery, deformable surfaces in environments with grass, long vegetation, concrete, pebbles, stairs, sand, etc. RMA shows state-of-the-art performance across diverse real-world as well as simulation experiments. Video results at https://ashish-kmr.github.io/rma-legged-robots/
Habitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


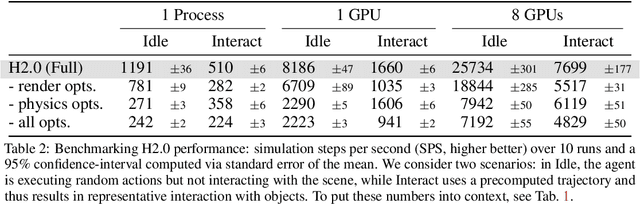
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.
Multiscale Vision Transformers
Apr 22, 2021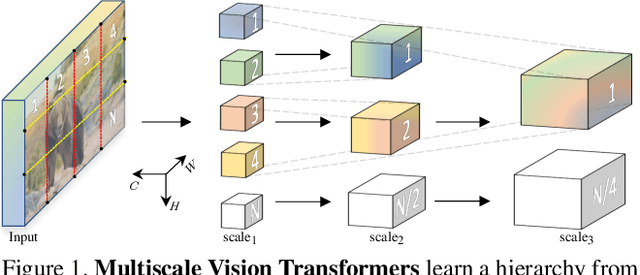

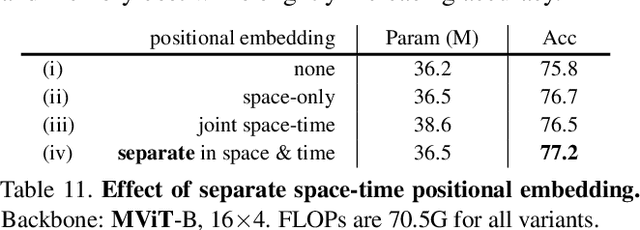
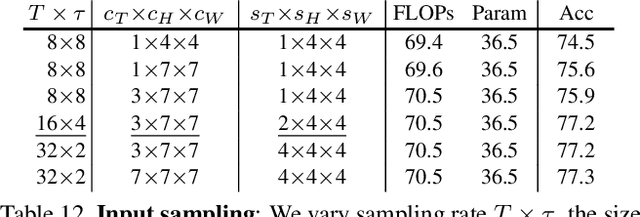
We present Multiscale Vision Transformers (MViT) for video and image recognition, by connecting the seminal idea of multiscale feature hierarchies with transformer models. Multiscale Transformers have several channel-resolution scale stages. Starting from the input resolution and a small channel dimension, the stages hierarchically expand the channel capacity while reducing the spatial resolution. This creates a multiscale pyramid of features with early layers operating at high spatial resolution to model simple low-level visual information, and deeper layers at spatially coarse, but complex, high-dimensional features. We evaluate this fundamental architectural prior for modeling the dense nature of visual signals for a variety of video recognition tasks where it outperforms concurrent vision transformers that rely on large scale external pre-training and are 5-10x more costly in computation and parameters. We further remove the temporal dimension and apply our model for image classification where it outperforms prior work on vision transformers. Code is available at: https://github.com/facebookresearch/SlowFast
Distribution-Free, Risk-Controlling Prediction Sets
Jan 30, 2021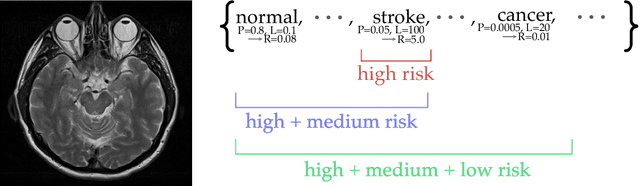
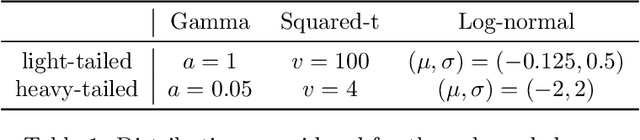
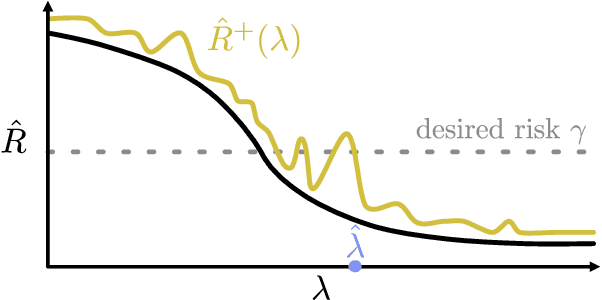
While improving prediction accuracy has been the focus of machine learning in recent years, this alone does not suffice for reliable decision-making. Deploying learning systems in consequential settings also requires calibrating and communicating the uncertainty of predictions. To convey instance-wise uncertainty for prediction tasks, we show how to generate set-valued predictions from a black-box predictor that control the expected loss on future test points at a user-specified level. Our approach provides explicit finite-sample guarantees for any dataset by using a holdout set to calibrate the size of the prediction sets. This framework enables simple, distribution-free, rigorous error control for many tasks, and we demonstrate it in five large-scale machine learning problems: (1) classification problems where some mistakes are more costly than others; (2) multi-label classification, where each observation has multiple associated labels; (3) classification problems where the labels have a hierarchical structure; (4) image segmentation, where we wish to predict a set of pixels containing an object of interest; and (5) protein structure prediction. Lastly, we discuss extensions to uncertainty quantification for ranking, metric learning and distributionally robust learning.
Reconstructing Hand-Object Interactions in the Wild
Dec 17, 2020

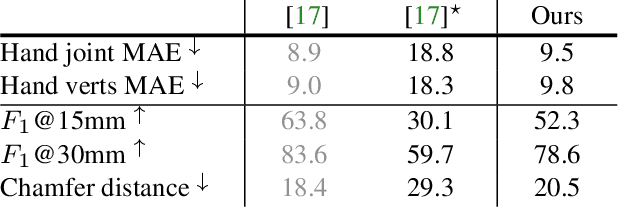
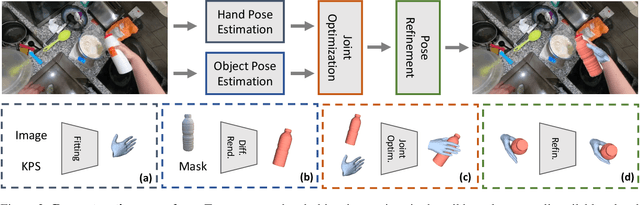
In this work we explore reconstructing hand-object interactions in the wild. The core challenge of this problem is the lack of appropriate 3D labeled data. To overcome this issue, we propose an optimization-based procedure which does not require direct 3D supervision. The general strategy we adopt is to exploit all available related data (2D bounding boxes, 2D hand keypoints, 2D instance masks, 3D object models, 3D in-the-lab MoCap) to provide constraints for the 3D reconstruction. Rather than optimizing the hand and object individually, we optimize them jointly which allows us to impose additional constraints based on hand-object contact, collision, and occlusion. Our method produces compelling reconstructions on the challenging in-the-wild data from the EPIC Kitchens and the 100 Days of Hands datasets, across a range of object categories. Quantitatively, we demonstrate that our approach compares favorably to existing approaches in the lab settings where ground truth 3D annotations are available.
Human Mesh Recovery from Multiple Shots
Dec 17, 2020

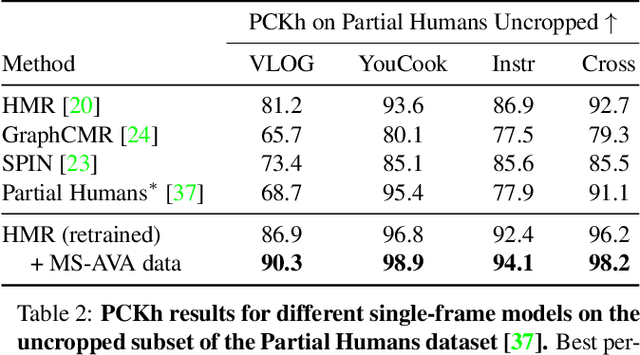

Videos from edited media like movies are a useful, yet under-explored source of information. The rich variety of appearance and interactions between humans depicted over a large temporal context in these films could be a valuable source of data. However, the richness of data comes at the expense of fundamental challenges such as abrupt shot changes and close up shots of actors with heavy truncation, which limits the applicability of existing human 3D understanding methods. In this paper, we address these limitations with an insight that while shot changes of the same scene incur a discontinuity between frames, the 3D structure of the scene still changes smoothly. This allows us to handle frames before and after the shot change as multi-view signal that provide strong cues to recover the 3D state of the actors. We propose a multi-shot optimization framework, which leads to improved 3D reconstruction and mining of long sequences with pseudo ground truth 3D human mesh. We show that the resulting data is beneficial in the training of various human mesh recovery models: for single image, we achieve improved robustness; for video we propose a pure transformer-based temporal encoder, which can naturally handle missing observations due to shot changes in the input frames. We demonstrate the importance of the insight and proposed models through extensive experiments. The tools we develop open the door to processing and analyzing in 3D content from a large library of edited media, which could be helpful for many downstream applications. Project page: https://geopavlakos.github.io/multishot
From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting
Dec 02, 2020
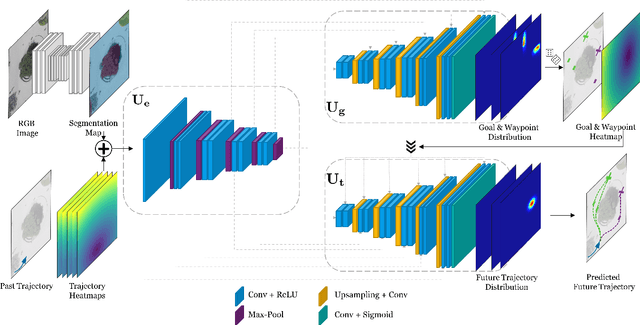
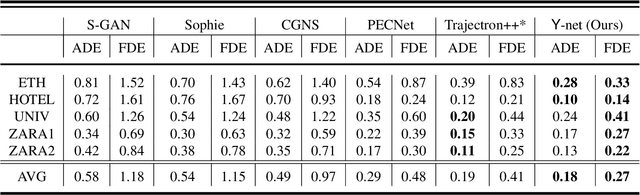
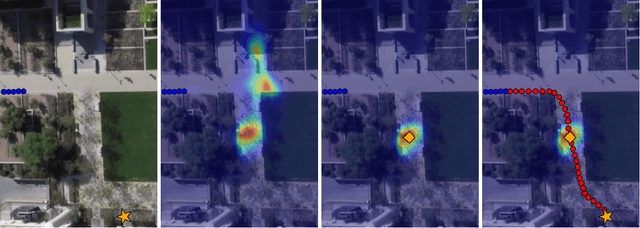
Human trajectory forecasting is an inherently multi-modal problem. Uncertainty in future trajectories stems from two sources: (a) sources that are known to the agent but unknown to the model, such as long term goals and (b)sources that are unknown to both the agent & the model, such as intent of other agents & irreducible randomness indecisions. We propose to factorize this uncertainty into its epistemic & aleatoric sources. We model the epistemic un-certainty through multimodality in long term goals and the aleatoric uncertainty through multimodality in waypoints& paths. To exemplify this dichotomy, we also propose a novel long term trajectory forecasting setting, with prediction horizons upto a minute, an order of magnitude longer than prior works. Finally, we presentY-net, a scene com-pliant trajectory forecasting network that exploits the pro-posed epistemic & aleatoric structure for diverse trajectory predictions across long prediction horizons.Y-net significantly improves previous state-of-the-art performance on both (a) The well studied short prediction horizon settings on the Stanford Drone & ETH/UCY datasets and (b) The proposed long prediction horizon setting on the re-purposed Stanford Drone & Intersection Drone datasets.