 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDO-s3DCNNs: Partial Differential Operator Based Steerable 3D CNNs
Aug 07, 2022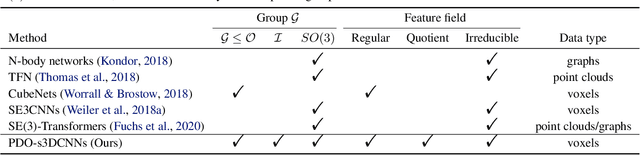
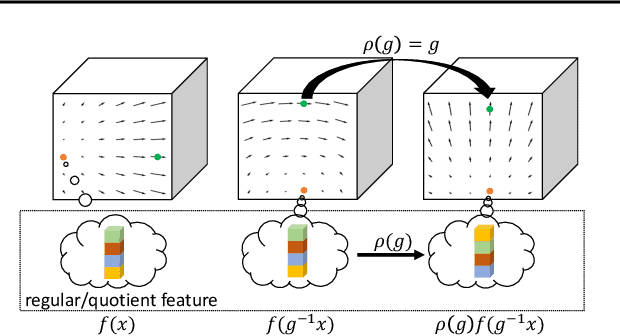

Steerable models can provide very general and flexible equivariance by formulating equivariance requirements in the language of representation theory and feature fields, which has been recognized to be effective for many vision tasks. However, deriving steerable models for 3D rotations is much more difficult than that in the 2D case, due to more complicated mathematics of 3D rotations. In this work, we employ partial differential operators (PDOs) to model 3D filters, and derive general steerable 3D CNNs, which are called PDO-s3DCNNs. We prove that the equivariant filters are subject to linear constraints, which can be solved efficiently under various conditions. As far as we know, PDO-s3DCNNs are the most general steerable CNNs for 3D rotations, in the sense that they cover all common subgroups of $SO(3)$ and their representations, while existing methods can only be applied to specific groups and representations. Extensive experiments show that our models can preserve equivariance well in the discrete domain, and outperform previous works on SHREC'17 retrieval and ISBI 2012 segmentation tasks with a low network complexity.
On Automatic Text Extractive Summarization Based on Graph and pre-trained Language Model Attention
Oct 10, 2021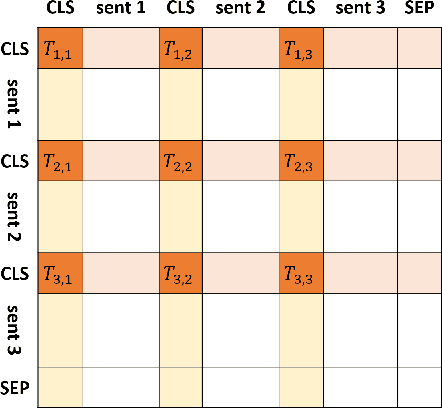
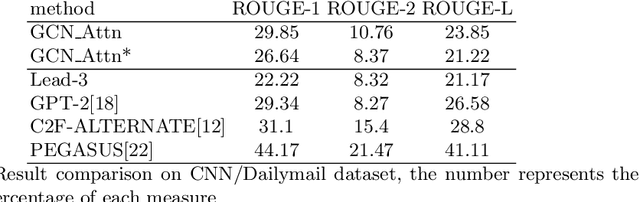
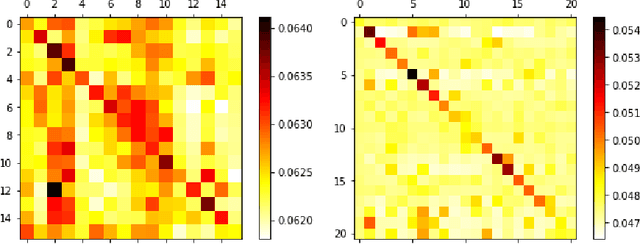
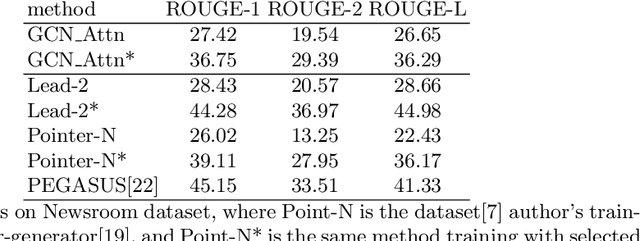
Representing text as graph to solve the summarization task has been discussed for more than 10 years. However, with the development of attention or Transformer, the connection between attention and graph remains poorly understood. We demonstrate that the text structure can be analyzed through the attention matrix, which represents the relation between sentences by the attention weights. In this work, we show that the attention matrix produced in pre-training language model can be used as the adjacent matrix of graph convolutional network model. Our model performs a competitive result on 2 different datasets based on the ROUGE index. Also, with fewer parameters, the model reduces the computation resource when training and inferring.
ARGO: Modeling Heterogeneity in E-commerce Recommendation
Sep 14, 2021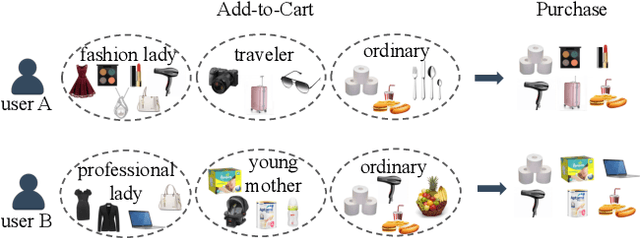
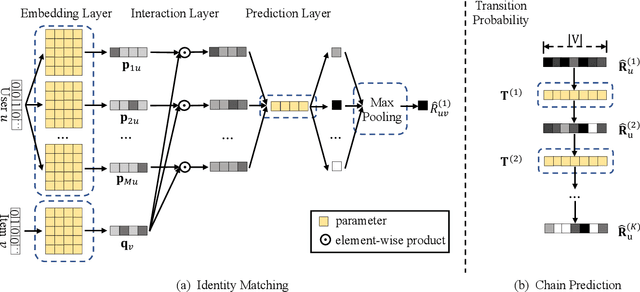
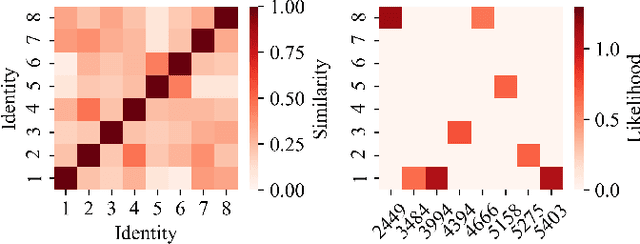
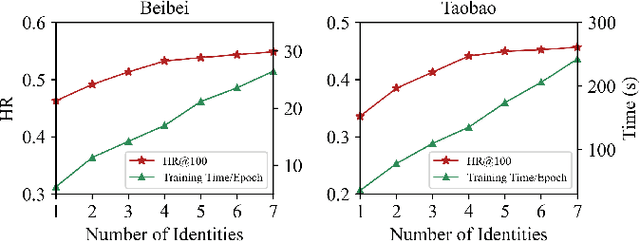
Nowadays, E-commerce is increasingly integrated into our daily lives. Meanwhile, shopping process has also changed incrementally from one behavior (purchase) to multiple behaviors (such as view, carting and purchase). Therefore, utilizing interaction data of auxiliary behavior data draws a lot of attention in the E-commerce recommender systems. However, all existing models ignore two kinds of intrinsic heterogeneity which are helpful to capture the difference of user preferences and the difference of item attributes. First (intra-heterogeneity), each user has multiple social identities with otherness, and these different identities can result in quite different interaction preferences. Second (inter-heterogeneity), each item can transfer an item-specific percentage of score from low-level behavior to high-level behavior for the gradual relationship among multiple behaviors. Thus, the lack of consideration of these heterogeneities damages recommendation rank performance. To model the above heterogeneities, we propose a novel method named intra- and inter-heterogeneity recommendation model (ARGO). Specifically, we embed each user into multiple vectors representing the user's identities, and the maximum of identity scores indicates the interaction preference. Besides, we regard the item-specific transition percentage as trainable transition probability between different behaviors. Extensive experiments on two real-world datasets show that ARGO performs much better than the state-of-the-art in multi-behavior scenarios.
Criterion-based Heterogeneous Collaborative Filtering for Multi-behavior Implicit Recommendation
May 28, 2021

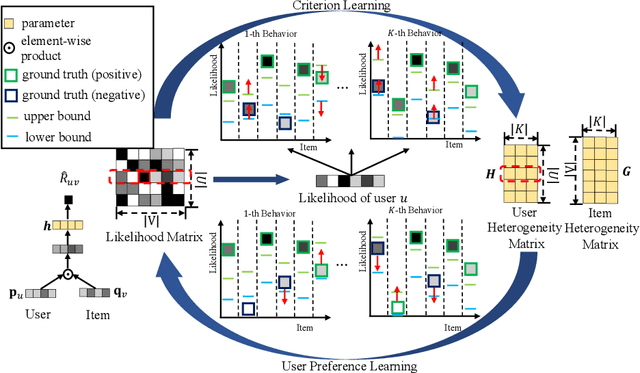

With the increasing scale and diversification of interaction behaviors in E-commerce, more and more researchers pay attention to multi-behavior recommender systems that utilize interaction data of other auxiliary behaviors such as view and cart. To address these challenges in heterogeneous scenarios, non-sampling methods have shown superiority over negative sampling methods. However, two observations are usually ignored in existing state-of-the-art non-sampling methods based on binary regression: (1) users have different preference strengths for different items, so they cannot be measured simply by binary implicit data; (2) the dependency across multiple behaviors varies for different users and items. To tackle the above issue, we propose a novel non-sampling learning framework named \underline{C}riterion-guided \underline{H}eterogeneous \underline{C}ollaborative \underline{F}iltering (CHCF). CHCF introduces both upper and lower bounds to indicate selection criteria, which will guide user preference learning. Besides, CHCF integrates criterion learning and user preference learning into a unified framework, which can be trained jointly for the interaction prediction on target behavior. We further theoretically demonstrate that the optimization of Collaborative Metric Learning can be approximately achieved by CHCF learning framework in a non-sampling form effectively. Extensive experiments on two real-world datasets show that CHCF outperforms the state-of-the-art methods in heterogeneous scenarios.
Deep Unsupervised Hashing by Distilled Smooth Guidance
May 13, 2021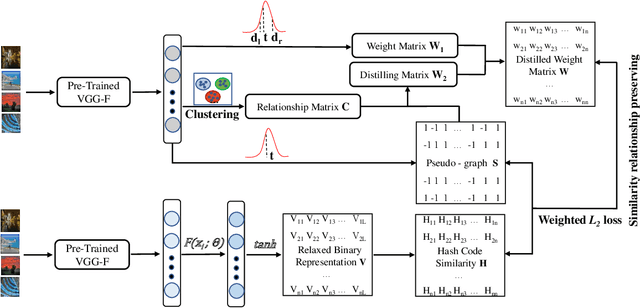
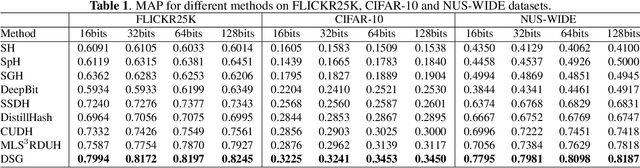

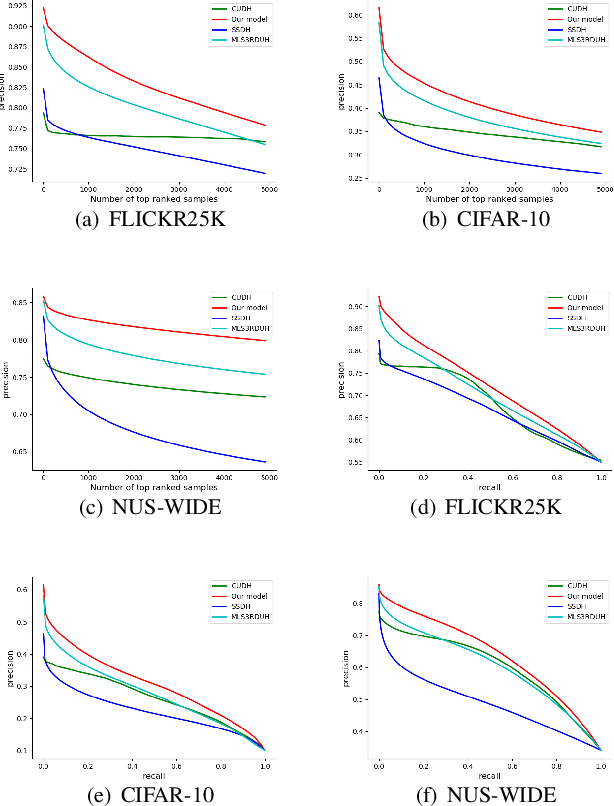
Hashing has been widely used in approximate nearest neighbor search for its storage and computational efficiency. Deep supervised hashing methods are not widely used because of the lack of labeled data, especially when the domain is transferred. Meanwhile, unsupervised deep hashing models can hardly achieve satisfactory performance due to the lack of reliable similarity signals. To tackle this problem, we propose a novel deep unsupervised hashing method, namely Distilled Smooth Guidance (DSG), which can learn a distilled dataset consisting of similarity signals as well as smooth confidence signals. To be specific, we obtain the similarity confidence weights based on the initial noisy similarity signals learned from local structures and construct a priority loss function for smooth similarity-preserving learning. Besides, global information based on clustering is utilized to distill the image pairs by removing contradictory similarity signals. Extensive experiments on three widely used benchmark datasets show that the proposed DSG consistently outperforms the state-of-the-art search methods.
* 7 pages, 3 figures
PDO-e$\text{S}^\text{2}$CNNs: Partial Differential Operator Based Equivariant Spherical CNNs
Apr 08, 2021
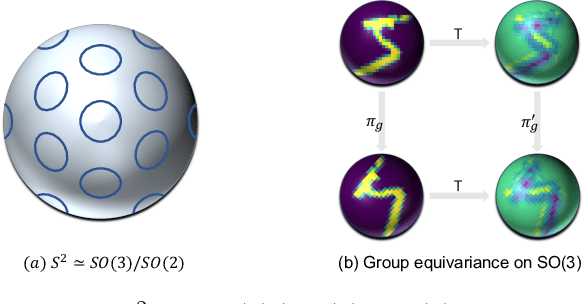
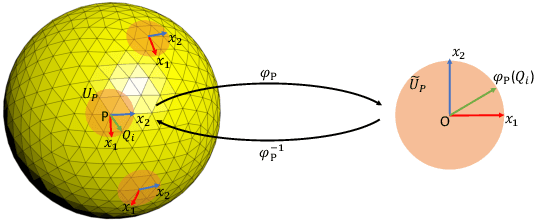
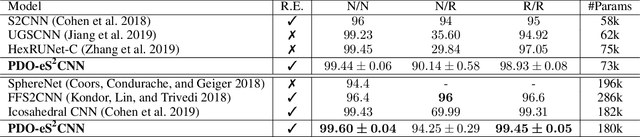
Spherical signals exist in many applications, e.g., planetary data, LiDAR scans and digitalization of 3D objects, calling for models that can process spherical data effectively. It does not perform well when simply projecting spherical data into the 2D plane and then using planar convolution neural networks (CNNs), because of the distortion from projection and ineffective translation equivariance. Actually, good principles of designing spherical CNNs are avoiding distortions and converting the shift equivariance property in planar CNNs to rotation equivariance in the spherical domain. In this work, we use partial differential operators (PDOs) to design a spherical equivariant CNN, PDO-e$\text{S}^\text{2}$CNN, which is exactly rotation equivariant in the continuous domain. We then discretize PDO-e$\text{S}^\text{2}$CNNs, and analyze the equivariance error resulted from discretization. This is the first time that the equivariance error is theoretically analyzed in the spherical domain. In experiments, PDO-e$\text{S}^\text{2}$CNNs show greater parameter efficiency and outperform other spherical CNNs significantly on several tasks.
PDO-eConvs: Partial Differential Operator Based Equivariant Convolutions
Aug 11, 2020
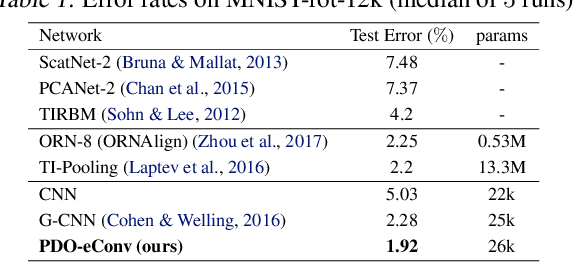

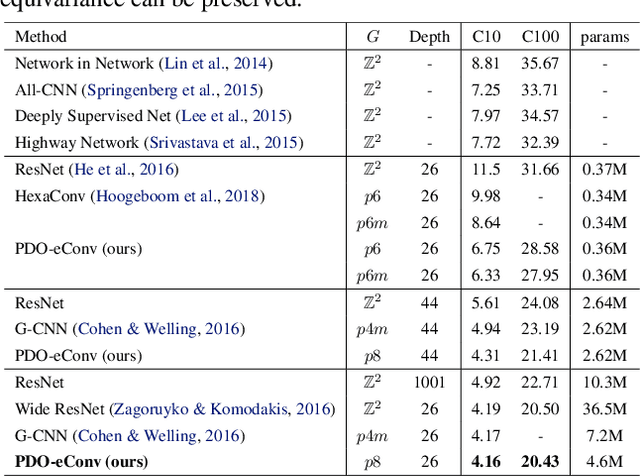
Recent research has shown that incorporating equivariance into neural network architectures is very helpful, and there have been some works investigating the equivariance of networks under group actions. However, as digital images and feature maps are on the discrete meshgrid, corresponding equivariance-preserving transformation groups are very limited. In this work, we deal with this issue from the connection between convolutions and partial differential operators (PDOs). In theory, assuming inputs to be smooth, we transform PDOs and propose a system which is equivariant to a much more general continuous group, the $n$-dimension Euclidean group. In implementation, we discretize the system using the numerical schemes of PDOs, deriving approximately equivariant convolutions (PDO-eConvs). Theoretically, the approximation error of PDO-eConvs is of the quadratic order. It is the first time that the error analysis is provided when the equivariance is approximate. Extensive experiments on rotated MNIST and natural image classification show that PDO-eConvs perform competitively yet use parameters much more efficiently. Particularly, compared with Wide ResNets, our methods result in better results using only 12.6% parameters.
Real-time Universal Style Transfer on High-resolution Images via Zero-channel Pruning
Jun 23, 2020
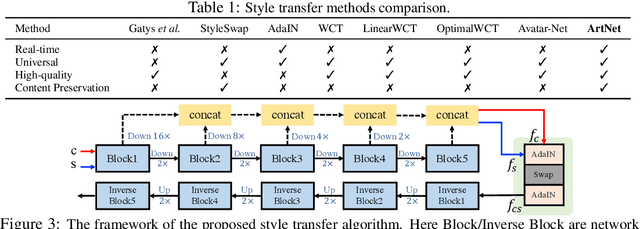


Extracting effective deep features to represent content and style information is the key to universal style transfer. Most existing algorithms use VGG19 as the feature extractor, which incurs a high computational cost and impedes real-time style transfer on high-resolution images. In this work, we propose a lightweight alternative architecture - ArtNet, which is based on GoogLeNet, and later pruned by a novel channel pruning method named Zero-channel Pruning specially designed for style transfer approaches. Besides, we propose a theoretically sound sandwich swap transform (S2) module to transfer deep features, which can create a pleasing holistic appearance and good local textures with an improved content preservation ability. By using ArtNet and S2, our method is 2.3 to 107.4 times faster than state-of-the-art approaches. The comprehensive experiments demonstrate that ArtNet can achieve universal, real-time, and high-quality style transfer on high-resolution images simultaneously, (68.03 FPS on 512 times 512 images).
DefenseVGAE: Defending against Adversarial Attacks on Graph Data via a Variational Graph Autoencoder
Jun 16, 2020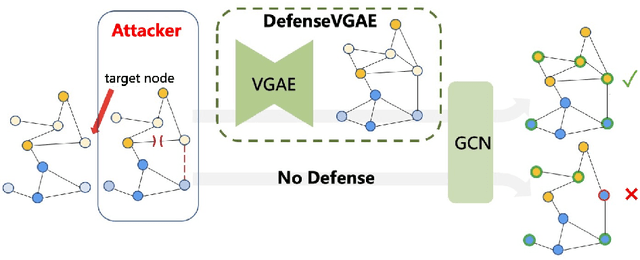
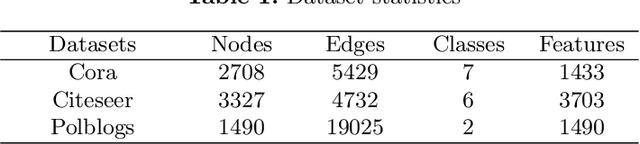
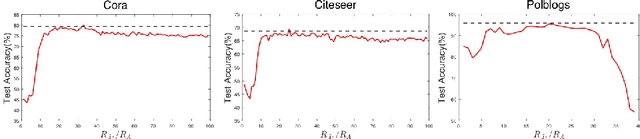
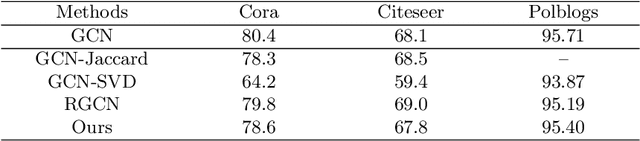
Graph neural networks (GNNs) achieve remarkable performance for tasks on graph data. However, recent works show they are extremely vulnerable to adversarial structural perturbations, making their outcomes unreliable. In this paper, we propose DefenseVGAE, a novel framework leveraging variational graph autoencoders(VGAEs) to defend GNNs against such attacks. DefenseVGAE is trained to reconstruct graph structure. The reconstructed adjacency matrix can reduce the effects of adversarial perturbations and boost the performance of GCNs when facing adversarial attacks. Our experiments on a number of datasets show the effectiveness of the proposed method under various threat models. Under some settings it outperforms existing defense strategies. Our code has been made publicly available at https://github.com/zhangao520/defense-vgae.
Multi-Label Classification with Label Graph Superimposing
Nov 21, 2019
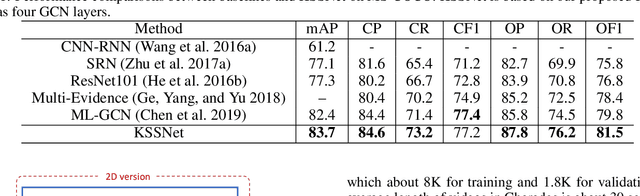
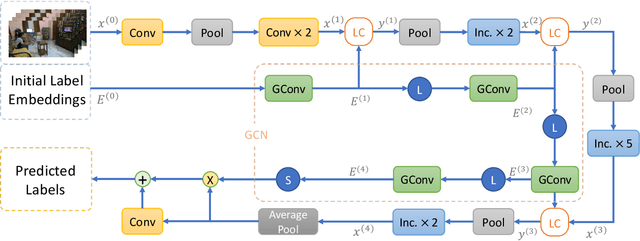

Images or videos always contain multiple objects or actions. Multi-label recognition has been witnessed to achieve pretty performance attribute to the rapid development of deep learning technologies. Recently, graph convolution network (GCN) is leveraged to boost the performance of multi-label recognition. However, what is the best way for label correlation modeling and how feature learning can be improved with label system awareness are still unclear. In this paper, we propose a label graph superimposing framework to improve the conventional GCN+CNN framework developed for multi-label recognition in the following two aspects. Firstly, we model the label correlations by superimposing label graph built from statistical co-occurrence information into the graph constructed from knowledge priors of labels, and then multi-layer graph convolutions are applied on the final superimposed graph for label embedding abstraction. Secondly, we propose to leverage embedding of the whole label system for better representation learning. In detail, lateral connections between GCN and CNN are added at shallow, middle and deep layers to inject information of label system into backbone CNN for label-awareness in the feature learning process. Extensive experiments are carried out on MS-COCO and Charades datasets, showing that our proposed solution can greatly improve the recognition performance and achieves new state-of-the-art recognition performance.