 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-kNN-LSH: A Nearest-Neighbor Algorithm for Sequential Counterfactual Inference
Feb 02, 2026Estimating causal effects from longitudinal trajectories is central to understanding the progression of complex conditions and optimizing clinical decision-making, such as comorbidities and long COVID recovery. We introduce \emph{C-kNN--LSH}, a nearest-neighbor framework for sequential causal inference designed to handle such high-dimensional, confounded situations. By utilizing locality-sensitive hashing, we efficiently identify ``clinical twins'' with similar covariate histories, enabling local estimation of conditional treatment effects across evolving disease states. To mitigate bias from irregular sampling and shifting patient recovery profiles, we integrate neighborhood estimator with a doubly-robust correction. Theoretical analysis guarantees our estimator is consistent and second-order robust to nuisance error. Evaluated on a real-world Long COVID cohort with 13,511 participants, \emph{C-kNN-LSH} demonstrates superior performance in capturing recovery heterogeneity and estimating policy values compared to existing baselines.
Physics-Informed Chebyshev Polynomial Neural Operator for Parametric Partial Differential Equations
Feb 02, 2026Neural operators have emerged as powerful deep learning frameworks for approximating solution operators of parameterized partial differential equations (PDE). However, current methods predominantly rely on multilayer perceptrons (MLPs) for mapping inputs to solutions, which impairs training robustness in physics-informed settings due to inherent spectral biases and fixed activation functions. To overcome the architectural limitations, we introduce the Physics-Informed Chebyshev Polynomial Neural Operator (CPNO), a novel mesh-free framework that leverages a basis transformation to replace unstable monomial expansions with the numerically stable Chebyshev spectral basis. By integrating parameter dependent modulation mechanism to main net, CPNO constructs PDE solutions in a near-optimal functional space, decoupling the model from MLP-specific constraints and enhancing multi-scale representation. Theoretical analysis demonstrates the Chebyshev basis's near-minimax uniform approximation properties and superior conditioning, with Lebesgue constants growing logarithmically with degree, thereby mitigating spectral bias and ensuring stable gradient flow during optimization. Numerical experiments on benchmark parameterized PDEs show that CPNO achieves superior accuracy, faster convergence, and enhanced robustness to hyperparameters. The experiment of transonic airfoil flow has demonstrated the capability of CPNO in characterizing complex geometric problems.
Optimal Budgeted Adaptation of Large Language Models
Feb 01, 2026The trade-off between labeled data availability and downstream accuracy remains a central challenge in fine-tuning large language models (LLMs). We propose a principled framework for \emph{budget-aware supervised fine-tuning} by casting LLM adaptation as a contextual Stackelberg game. In our formulation, the learner (leader) commits to a scoring policy and a label-querying strategy, while an adaptive environment (follower) selects challenging supervised alternatives in response. To explicitly address label efficiency, we incorporate a finite supervision budget directly into the learning objective. Our algorithm operates in the full-feedback regime and achieves $\tilde{O}(d\sqrt{T})$ regret under standard linear contextual assumptions. We extend the framework with a Largest-Latency-First (LLF) confidence gate that selectively queries labels, achieving a budget-aware regret bound of $\tilde{O}(\sqrt{dB} + c\sqrt{B})$ with $B=βT$.
DiffStyle3D: Consistent 3D Gaussian Stylization via Attention Optimization
Jan 27, 20263D style transfer enables the creation of visually expressive 3D content, enriching the visual appearance of 3D scenes and objects. However, existing VGG- and CLIP-based methods struggle to model multi-view consistency within the model itself, while diffusion-based approaches can capture such consistency but rely on denoising directions, leading to unstable training. To address these limitations, we propose DiffStyle3D, a novel diffusion-based paradigm for 3DGS style transfer that directly optimizes in the latent space. Specifically, we introduce an Attention-Aware Loss that performs style transfer by aligning style features in the self-attention space, while preserving original content through content feature alignment. Inspired by the geometric invariance of 3D stylization, we propose a Geometry-Guided Multi-View Consistency method that integrates geometric information into self-attention to enable cross-view correspondence modeling. Based on geometric information, we additionally construct a geometry-aware mask to prevent redundant optimization in overlapping regions across views, which further improves multi-view consistency. Extensive experiments show that DiffStyle3D outperforms state-of-the-art methods, achieving higher stylization quality and visual realism.
Self-Supervised Weight Templates for Scalable Vision Model Initialization
Jan 27, 2026The increasing scale and complexity of modern model parameters underscore the importance of pre-trained models. However, deployment often demands architectures of varying sizes, exposing limitations of conventional pre-training and fine-tuning. To address this, we propose SWEET, a self-supervised framework that performs constraint-based pre-training to enable scalable initialization in vision tasks. Instead of pre-training a fixed-size model, we learn a shared weight template and size-specific weight scalers under Tucker-based factorization, which promotes modularity and supports flexible adaptation to architectures with varying depths and widths. Target models are subsequently initialized by composing and reweighting the template through lightweight weight scalers, whose parameters can be efficiently learned from minimal training data. To further enhance flexibility in width expansion, we introduce width-wise stochastic scaling, which regularizes the template along width-related dimensions and encourages robust, width-invariant representations for improved cross-width generalization. Extensive experiments on \textsc{classification}, \textsc{detection}, \textsc{segmentation} and \textsc{generation} tasks demonstrate the state-of-the-art performance of SWEET for initializing variable-sized vision models.
Omni-directional attention mechanism based on Mamba for speech separation
Jan 23, 2026Mamba, a selective state-space model (SSM), has emerged as an efficient alternative to Transformers for speech modeling, enabling long-sequence processing with linear complexity. While effective in speech separation, existing approaches, whether in the time or time-frequency domain, typically decompose the input along a single dimension into short one-dimensional sequences before processing them with Mamba, which restricts it to local 1D modeling and limits its ability to capture global dependencies across the 2D spectrogram. In this work, we propose an efficient omni-directional attention (OA) mechanism built upon unidirectional Mamba, which models global dependencies from ten different directions on the spectrogram. We expand the proposed mechanism into two baseline separation models and evaluate on three public datasets. Experimental results show that our approach consistently achieves significant performance gains over the baselines while preserving linear complexity, outperforming existing state-of-the-art (SOTA) systems.
Taxon: Hierarchical Tax Code Prediction with Semantically Aligned LLM Expert Guidance
Jan 13, 2026Tax code prediction is a crucial yet underexplored task in automating invoicing and compliance management for large-scale e-commerce platforms. Each product must be accurately mapped to a node within a multi-level taxonomic hierarchy defined by national standards, where errors lead to financial inconsistencies and regulatory risks. This paper presents Taxon, a semantically aligned and expert-guided framework for hierarchical tax code prediction. Taxon integrates (i) a feature-gating mixture-of-experts architecture that adaptively routes multi-modal features across taxonomy levels, and (ii) a semantic consistency model distilled from large language models acting as domain experts to verify alignment between product titles and official tax definitions. To address noisy supervision in real business records, we design a multi-source training pipeline that combines curated tax databases, invoice validation logs, and merchant registration data to provide both structural and semantic supervision. Extensive experiments on the proprietary TaxCode dataset and public benchmarks demonstrate that Taxon achieves state-of-the-art performance, outperforming strong baselines. Further, an additional full hierarchical paths reconstruction procedure significantly improves structural consistency, yielding the highest overall F1 scores. Taxon has been deployed in production within Alibaba's tax service system, handling an average of over 500,000 tax code queries per day and reaching peak volumes above five million requests during business event with improved accuracy, interpretability, and robustness.
AstroReview: An LLM-driven Multi-Agent Framework for Telescope Proposal Peer Review and Refinement
Dec 31, 2025Competitive access to modern observatories has intensified as proposal volumes outpace available telescope time, making timely, consistent, and transparent peer review a critical bottleneck for the advancement of astronomy. Automating parts of this process is therefore both scientifically significant and operationally necessary to ensure fair allocation and reproducible decisions at scale. We present AstroReview, an open-source, agent-based framework that automates proposal review in three stages: (i) novelty and scientific merit, (ii) feasibility and expected yield, and (iii) meta-review and reliability verification. Task isolation and explicit reasoning traces curb hallucinations and improve transparency. Without any domain specific fine tuning, AstroReview used in our experiments only for the last stage, correctly identifies genuinely accepted proposals with an accuracy of 87%. The AstroReview in Action module replicates the review and refinement loop; with its integrated Proposal Authoring Agent, the acceptance rate of revised drafts increases by 66% after two iterations, showing that iterative feedback combined with automated meta-review and reliability verification delivers measurable quality gains. Together, these results point to a practical path toward scalable, auditable, and higher throughput proposal review for resource limited facilities.
DiverseGRPO: Mitigating Mode Collapse in Image Generation via Diversity-Aware GRPO
Dec 25, 2025



Reinforcement learning (RL), particularly GRPO, improves image generation quality significantly by comparing the relative performance of images generated within the same group. However, in the later stages of training, the model tends to produce homogenized outputs, lacking creativity and visual diversity, which restricts its application scenarios. This issue can be analyzed from both reward modeling and generation dynamics perspectives. First, traditional GRPO relies on single-sample quality as the reward signal, driving the model to converge toward a few high-reward generation modes while neglecting distribution-level diversity. Second, conventional GRPO regularization neglects the dominant role of early-stage denoising in preserving diversity, causing a misaligned regularization budget that limits the achievable quality--diversity trade-off. Motivated by these insights, we revisit the diversity degradation problem from both reward modeling and generation dynamics. At the reward level, we propose a distributional creativity bonus based on semantic grouping. Specifically, we construct a distribution-level representation via spectral clustering over samples generated from the same caption, and adaptively allocate exploratory rewards according to group sizes to encourage the discovery of novel visual modes. At the generation level, we introduce a structure-aware regularization, which enforces stronger early-stage constraints to preserve diversity without compromising reward optimization efficiency. Experiments demonstrate that our method achieves a 13\%--18\% improvement in semantic diversity under matched quality scores, establishing a new Pareto frontier between image quality and diversity for GRPO-based image generation.
Do Reviews Matter for Recommendations in the Era of Large Language Models?
Dec 15, 2025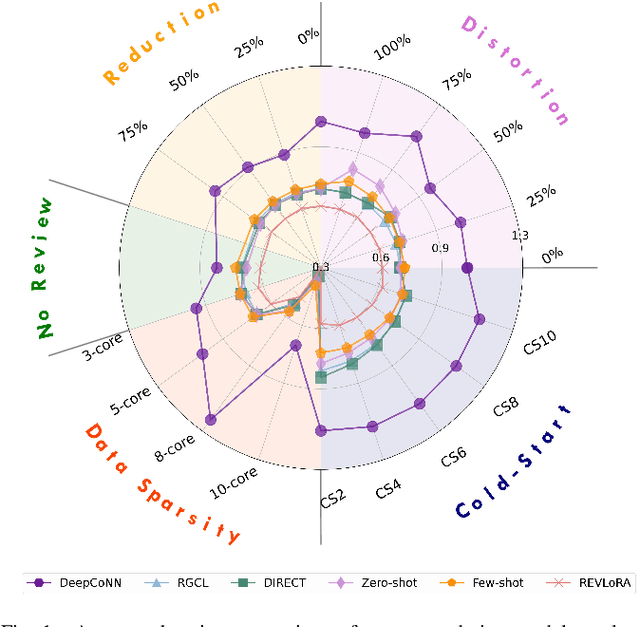
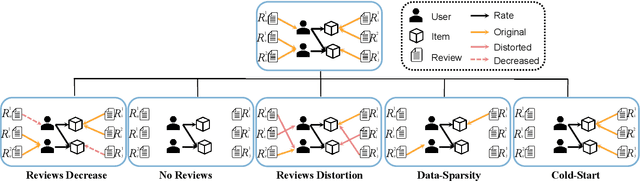
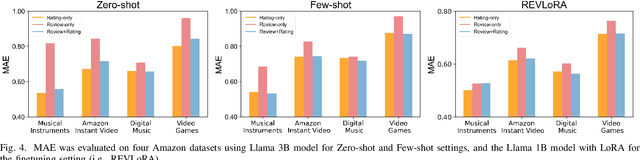
With the advent of large language models (LLMs), the landscape of recommender systems is undergoing a significant transformation. Traditionally, user reviews have served as a critical source of rich, contextual information for enhancing recommendation quality. However, as LLMs demonstrate an unprecedented ability to understand and generate human-like text, this raises the question of whether explicit user reviews remain essential in the era of LLMs. In this paper, we provide a systematic investigation of the evolving role of text reviews in recommendation by comparing deep learning methods and LLM approaches. Particularly, we conduct extensive experiments on eight public datasets with LLMs and evaluate their performance in zero-shot, few-shot, and fine-tuning scenarios. We further introduce a benchmarking evaluation framework for review-aware recommender systems, RAREval, to comprehensively assess the contribution of textual reviews to the recommendation performance of review-aware recommender systems. Our framework examines various scenarios, including the removal of some or all textual reviews, random distortion, as well as recommendation performance in data sparsity and cold-start user settings. Our findings demonstrate that LLMs are capable of functioning as effective review-aware recommendation engines, generally outperforming traditional deep learning approaches, particularly in scenarios characterized by data sparsity and cold-start conditions. In addition, the removal of some or all textual reviews and random distortion does not necessarily lead to declines in recommendation accuracy. These findings motivate a rethinking of how user preference from text reviews can be more effectively leveraged. All code and supplementary materials are available at: https://github.com/zhytk/RAREval-data-processing.