 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning LLMs with Graph Neural Solvers for Combinatorial Optimization
Mar 28, 2026Recent research has demonstrated the effectiveness of large language models (LLMs) in solving combinatorial optimization problems (COPs) by representing tasks and instances in natural language. However, purely language-based approaches struggle to accurately capture complex relational structures inherent in many COPs, rendering them less effective at addressing medium-sized or larger instances. To address these limitations, we propose AlignOPT, a novel approach that aligns LLMs with graph neural solvers to learn a more generalizable neural COP heuristic. Specifically, AlignOPT leverages the semantic understanding capabilities of LLMs to encode textual descriptions of COPs and their instances, while concurrently exploiting graph neural solvers to explicitly model the underlying graph structures of COP instances. Our approach facilitates a robust integration and alignment between linguistic semantics and structural representations, enabling more accurate and scalable COP solutions. Experimental results demonstrate that AlignOPT achieves state-of-the-art results across diverse COPs, underscoring its effectiveness in aligning semantic and structural representations. In particular, AlignOPT demonstrates strong generalization, effectively extending to previously unseen COP instances.
Do Reviews Matter for Recommendations in the Era of Large Language Models?
Dec 15, 2025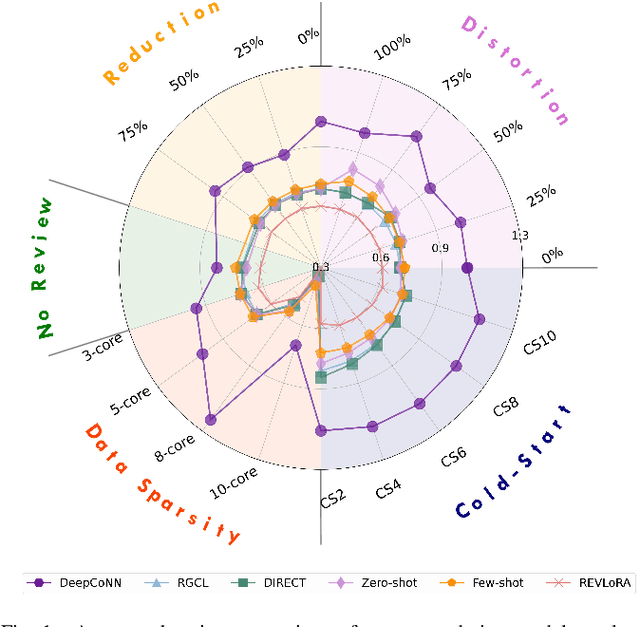
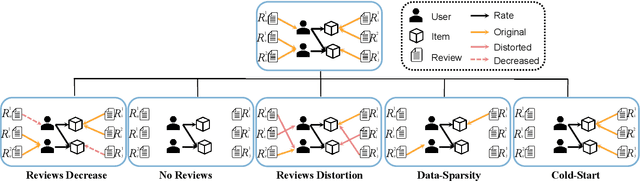
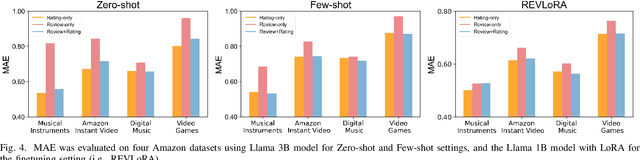
With the advent of large language models (LLMs), the landscape of recommender systems is undergoing a significant transformation. Traditionally, user reviews have served as a critical source of rich, contextual information for enhancing recommendation quality. However, as LLMs demonstrate an unprecedented ability to understand and generate human-like text, this raises the question of whether explicit user reviews remain essential in the era of LLMs. In this paper, we provide a systematic investigation of the evolving role of text reviews in recommendation by comparing deep learning methods and LLM approaches. Particularly, we conduct extensive experiments on eight public datasets with LLMs and evaluate their performance in zero-shot, few-shot, and fine-tuning scenarios. We further introduce a benchmarking evaluation framework for review-aware recommender systems, RAREval, to comprehensively assess the contribution of textual reviews to the recommendation performance of review-aware recommender systems. Our framework examines various scenarios, including the removal of some or all textual reviews, random distortion, as well as recommendation performance in data sparsity and cold-start user settings. Our findings demonstrate that LLMs are capable of functioning as effective review-aware recommendation engines, generally outperforming traditional deep learning approaches, particularly in scenarios characterized by data sparsity and cold-start conditions. In addition, the removal of some or all textual reviews and random distortion does not necessarily lead to declines in recommendation accuracy. These findings motivate a rethinking of how user preference from text reviews can be more effectively leveraged. All code and supplementary materials are available at: https://github.com/zhytk/RAREval-data-processing.