 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffStyle3D: Consistent 3D Gaussian Stylization via Attention Optimization
Jan 27, 20263D style transfer enables the creation of visually expressive 3D content, enriching the visual appearance of 3D scenes and objects. However, existing VGG- and CLIP-based methods struggle to model multi-view consistency within the model itself, while diffusion-based approaches can capture such consistency but rely on denoising directions, leading to unstable training. To address these limitations, we propose DiffStyle3D, a novel diffusion-based paradigm for 3DGS style transfer that directly optimizes in the latent space. Specifically, we introduce an Attention-Aware Loss that performs style transfer by aligning style features in the self-attention space, while preserving original content through content feature alignment. Inspired by the geometric invariance of 3D stylization, we propose a Geometry-Guided Multi-View Consistency method that integrates geometric information into self-attention to enable cross-view correspondence modeling. Based on geometric information, we additionally construct a geometry-aware mask to prevent redundant optimization in overlapping regions across views, which further improves multi-view consistency. Extensive experiments show that DiffStyle3D outperforms state-of-the-art methods, achieving higher stylization quality and visual realism.
SplitFlux: Learning to Decouple Content and Style from a Single Image
Nov 19, 2025



Disentangling image content and style is essential for customized image generation. Existing SDXL-based methods struggle to achieve high-quality results, while the recently proposed Flux model fails to achieve effective content-style separation due to its underexplored characteristics. To address these challenges, we conduct a systematic analysis of Flux and make two key observations: (1) Single Dream Blocks are essential for image generation; and (2) Early single stream blocks mainly control content, whereas later blocks govern style. Based on these insights, we propose SplitFlux, which disentangles content and style by fine-tuning the single dream blocks via LoRA, enabling the disentangled content to be re-embedded into new contexts. It includes two key components: (1) Rank-Constrained Adaptation. To preserve content identity and structure, we compress the rank and amplify the magnitude of updates within specific blocks, preventing content leakage into style blocks. (2) Visual-Gated LoRA. We split the content LoRA into two branches with different ranks, guided by image saliency. The high-rank branch preserves primary subject information, while the low-rank branch encodes residual details, mitigating content overfitting and enabling seamless re-embedding. Extensive experiments demonstrate that SplitFlux consistently outperforms state-of-the-art methods, achieving superior content preservation and stylization quality across diverse scenarios.
Gaussian Combined Distance: A Generic Metric for Object Detection
Oct 31, 2025In object detection, a well-defined similarity metric can significantly enhance model performance. Currently, the IoU-based similarity metric is the most commonly preferred choice for detectors. However, detectors using IoU as a similarity metric often perform poorly when detecting small objects because of their sensitivity to minor positional deviations. To address this issue, recent studies have proposed the Wasserstein Distance as an alternative to IoU for measuring the similarity of Gaussian-distributed bounding boxes. However, we have observed that the Wasserstein Distance lacks scale invariance, which negatively impacts the model's generalization capability. Additionally, when used as a loss function, its independent optimization of the center attributes leads to slow model convergence and unsatisfactory detection precision. To address these challenges, we introduce the Gaussian Combined Distance (GCD). Through analytical examination of GCD and its gradient, we demonstrate that GCD not only possesses scale invariance but also facilitates joint optimization, which enhances model localization performance. Extensive experiments on the AI-TOD-v2 dataset for tiny object detection show that GCD, as a bounding box regression loss function and label assignment metric, achieves state-of-the-art performance across various detectors. We further validated the generalizability of GCD on the MS-COCO-2017 and Visdrone-2019 datasets, where it outperforms the Wasserstein Distance across diverse scales of datasets. Code is available at https://github.com/MArKkwanGuan/mmdet-GCD.
FantasyStyle: Controllable Stylized Distillation for 3D Gaussian Splatting
Aug 11, 2025The success of 3DGS in generative and editing applications has sparked growing interest in 3DGS-based style transfer. However, current methods still face two major challenges: (1) multi-view inconsistency often leads to style conflicts, resulting in appearance smoothing and distortion; and (2) heavy reliance on VGG features, which struggle to disentangle style and content from style images, often causing content leakage and excessive stylization. To tackle these issues, we introduce \textbf{FantasyStyle}, a 3DGS-based style transfer framework, and the first to rely entirely on diffusion model distillation. It comprises two key components: (1) \textbf{Multi-View Frequency Consistency}. We enhance cross-view consistency by applying a 3D filter to multi-view noisy latent, selectively reducing low-frequency components to mitigate stylized prior conflicts. (2) \textbf{Controllable Stylized Distillation}. To suppress content leakage from style images, we introduce negative guidance to exclude undesired content. In addition, we identify the limitations of Score Distillation Sampling and Delta Denoising Score in 3D style transfer and remove the reconstruction term accordingly. Building on these insights, we propose a controllable stylized distillation that leverages negative guidance to more effectively optimize the 3D Gaussians. Extensive experiments demonstrate that our method consistently outperforms state-of-the-art approaches, achieving higher stylization quality and visual realism across various scenes and styles.
Prompt-Softbox-Prompt: A free-text Embedding Control for Image Editing
Aug 27, 2024Text-driven diffusion models have achieved remarkable success in image editing, but a crucial component in these models-text embeddings-has not been fully explored. The entanglement and opacity of text embeddings present significant challenges to achieving precise image editing. In this paper, we provide a comprehensive and in-depth analysis of text embeddings in Stable Diffusion XL, offering three key insights. First, while the 'aug_embedding' captures the full semantic content of the text, its contribution to the final image generation is relatively minor. Second, 'BOS' and 'Padding_embedding' do not contain any semantic information. Lastly, the 'EOS' holds the semantic information of all words and contains the most style features. Each word embedding plays a unique role without interfering with one another. Based on these insights, we propose a novel approach for controllable image editing using a free-text embedding control method called PSP (Prompt-Softbox-Prompt). PSP enables precise image editing by inserting or adding text embeddings within the cross-attention layers and using Softbox to define and control the specific area for semantic injection. This technique allows for obejct additions and replacements while preserving other areas of the image. Additionally, PSP can achieve style transfer by simply replacing text embeddings. Extensive experimental results show that PSP achieves significant results in tasks such as object replacement, object addition, and style transfer.
Doing Good or Doing Right? Exploring the Weakness of Commonsense Causal Reasoning Models
Jul 05, 2021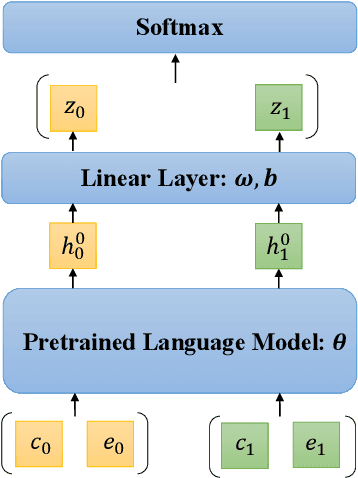



Pretrained language models (PLM) achieve surprising performance on the Choice of Plausible Alternatives (COPA) task. However, whether PLMs have truly acquired the ability of causal reasoning remains a question. In this paper, we investigate the problem of semantic similarity bias and reveal the vulnerability of current COPA models by certain attacks. Previous solutions that tackle the superficial cues of unbalanced token distribution still encounter the same problem of semantic bias, even more seriously due to the utilization of more training data. We mitigate this problem by simply adding a regularization loss and experimental results show that this solution not only improves the model's generalization ability, but also assists the models to perform more robustly on a challenging dataset, BCOPA-CE, which has unbiased token distribution and is more difficult for models to distinguish cause and effect.