 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond NL2Code: A Structured Survey of Multimodal Code Intelligence
Jun 16, 2026While Large Language Models (LLMs) have substantially advanced text-to-code synthesis, many real programming tasks specify intent through visual artifacts such as screenshots, charts, vector drawings, videos, and interactive states. These tasks require models to connect visual perception to executable programs, because correctness depends not only on syntax but also on layout, data semantics, interaction behavior, and domain-specific constraints that apply after execution. This survey examines Multimodal Code Intelligence, covering systems that generate, edit, refine, or reason with code under visually grounded inputs and outputs. We first formulate the field by the role that code plays in each task, distinguishing code as a rendered artifact, an editable symbolic structure, a scientific representation, an intermediate reasoning trace, or an executable policy or tool interface. We then organize benchmarks and methods into four domains: Graphical User Interface, Scientific Visualization, Structured Graphics, and Frontier Tasks and Frameworks. This taxonomy connects mature artifact-generation problems to emerging agentic and unified settings and allows us to compare how different tasks treat evidence of correctness. Looking ahead, we argue that future research may benefit from four verification-centered directions. Multi-signal validation can combine complementary evidence of correctness, multi-state verification can test behavior across execution trajectories, cross-task transfer testing can probe reusable visual-code skills, and verifiable agent traces can reveal whether agent actions are grounded in visual evidence. Together, these directions may move this field from single-output imitation toward evidence-grounded executable systems. An ongoing project and resources are available on \href{https://github.com/xjywhu/Awesome-Multimodal-LLM-for-Code}{GitHub}.
OmniDiagram: Advancing Unified Diagram Code Generation via Visual Interrogation Reward
Apr 07, 2026The paradigm of programmable diagram generation is evolving rapidly, playing a crucial role in structured visualization. However, most existing studies are confined to a narrow range of task formulations and language support, constraining their applicability to diverse diagram types. In this work, we propose OmniDiagram, a unified framework that incorporates diverse diagram code languages and task definitions. To address the challenge of aligning code logic with visual fidelity in Reinforcement Learning (RL), we introduce a novel visual feedback strategy named Visual Interrogation Verifies All (\textsc{Viva}). Unlike brittle syntax-based rules or pixel-level matching, \textsc{Viva} rewards the visual structure of rendered diagrams through a generative approach. Specifically, \textsc{Viva} actively generates targeted visual inquiries to scrutinize diagram visual fidelity and provides fine-grained feedback for optimization. This mechanism facilitates a self-evolving training process, effectively obviating the need for manually annotated ground truth code. Furthermore, we construct M3$^2$Diagram, the first large-scale diagram code generation dataset, containing over 196k high-quality instances. Experimental results confirm that the combination of SFT and our \textsc{Viva}-based RL allows OmniDiagram to establish a new state-of-the-art (SOTA) across diagram code generation benchmarks.
DiffStyle3D: Consistent 3D Gaussian Stylization via Attention Optimization
Jan 27, 20263D style transfer enables the creation of visually expressive 3D content, enriching the visual appearance of 3D scenes and objects. However, existing VGG- and CLIP-based methods struggle to model multi-view consistency within the model itself, while diffusion-based approaches can capture such consistency but rely on denoising directions, leading to unstable training. To address these limitations, we propose DiffStyle3D, a novel diffusion-based paradigm for 3DGS style transfer that directly optimizes in the latent space. Specifically, we introduce an Attention-Aware Loss that performs style transfer by aligning style features in the self-attention space, while preserving original content through content feature alignment. Inspired by the geometric invariance of 3D stylization, we propose a Geometry-Guided Multi-View Consistency method that integrates geometric information into self-attention to enable cross-view correspondence modeling. Based on geometric information, we additionally construct a geometry-aware mask to prevent redundant optimization in overlapping regions across views, which further improves multi-view consistency. Extensive experiments show that DiffStyle3D outperforms state-of-the-art methods, achieving higher stylization quality and visual realism.
ChartEdit: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs' Capability via Chart Editing
May 17, 2025Although multimodal large language models (MLLMs) show promise in generating chart rendering code, chart editing presents a greater challenge. This difficulty stems from its nature as a labor-intensive task for humans that also demands MLLMs to integrate chart understanding, complex reasoning, and precise intent interpretation. While many MLLMs claim such editing capabilities, current assessments typically rely on limited case studies rather than robust evaluation methodologies, highlighting the urgent need for a comprehensive evaluation framework. In this work, we propose ChartEdit, a new high-quality benchmark designed for chart editing tasks. This benchmark comprises $1,405$ diverse editing instructions applied to $233$ real-world charts, with each instruction-chart instance having been manually annotated and validated for accuracy. Utilizing ChartEdit, we evaluate the performance of 10 mainstream MLLMs across two types of experiments, assessing them at both the code and chart levels. The results suggest that large-scale models can generate code to produce images that partially match the reference images. However, their ability to generate accurate edits according to the instructions remains limited. The state-of-the-art (SOTA) model achieves a score of only $59.96$, highlighting significant challenges in precise modification. In contrast, small-scale models, including chart-domain models, struggle both with following editing instructions and generating overall chart images, underscoring the need for further development in this area. Code is available at https://github.com/xxlllz/ChartEdit.
Model Pruning Based on Quantified Similarity of Feature Maps
May 13, 2021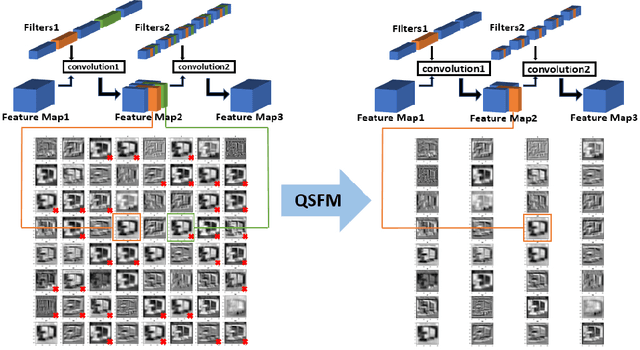

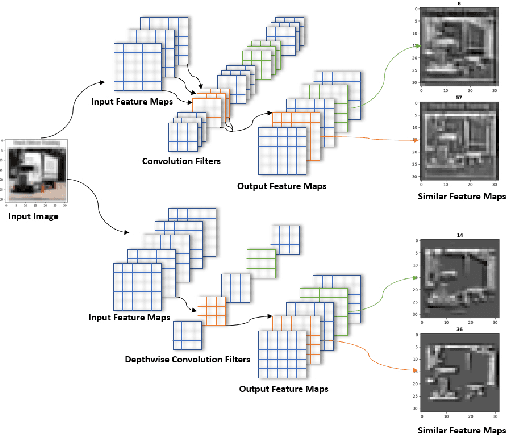
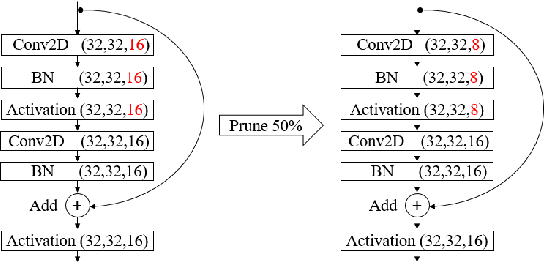
A high-accuracy CNN is often accompanied by huge parameters, which are usually stored in the high-dimensional tensors. However, there are few methods can figure out the redundant information of the parameters stored in the high-dimensional tensors, which leads to the lack of theoretical guidance for the compression of CNNs. In this paper, we propose a novel theory to find redundant information in three dimensional tensors, namely Quantified Similarity of Feature Maps (QSFM), and use this theory to prune convolutional neural networks to enhance the inference speed. Our method belongs to filter pruning, which can be implemented without using any special libraries. We perform our method not only on common convolution layers but also on special convolution layers, such as depthwise separable convolution layers. The experiments prove that QSFM can find the redundant information in the neural network effectively. Without any fine-tuning operation, QSFM can compress ResNet-56 on CIFAR-10 significantly (48.27% FLOPs and 57.90% parameters reduction) with only a loss of 0.54% in the top-1 accuracy. QSFM also prunes ResNet-56, VGG-16 and MobileNetV2 with fine-tuning operation, which also shows excellent results.