 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Wings of Imagination: Conflicting Script-based Multi-role Framework for Humor Caption Generation
Feb 06, 2026Humor is a commonly used and intricate human language in daily life. Humor generation, especially in multi-modal scenarios, is a challenging task for large language models (LLMs), which is typically as funny caption generation for images, requiring visual understanding, humor reasoning, creative imagination, and so on. Existing LLM-based approaches rely on reasoning chains or self-improvement, which suffer from limited creativity and interpretability. To address these bottlenecks, we develop a novel LLM-based humor generation mechanism based on a fundamental humor theory, GTVH. To produce funny and script-opposite captions, we introduce a humor-theory-driven multi-role LLM collaboration framework augmented with humor retrieval (HOMER). The framework consists of three LLM-based roles: (1) conflicting-script extractor that grounds humor in key script oppositions, forming the basis of caption generation; (2) retrieval-augmented hierarchical imaginator that identifies key humor targets and expands the creative space of them through diverse associations structured as imagination trees; and (3) caption generator that produces funny and diverse captions conditioned on the obtained knowledge. Extensive experiments on two New Yorker Cartoon benchmarking datasets show that HOMER outperforms state-of-the-art baselines and powerful LLM reasoning strategies on multi-modal humor captioning.
HugRAG: Hierarchical Causal Knowledge Graph Design for RAG
Feb 04, 2026Retrieval augmented generation (RAG) has enhanced large language models by enabling access to external knowledge, with graph-based RAG emerging as a powerful paradigm for structured retrieval and reasoning. However, existing graph-based methods often over-rely on surface-level node matching and lack explicit causal modeling, leading to unfaithful or spurious answers. Prior attempts to incorporate causality are typically limited to local or single-document contexts and also suffer from information isolation that arises from modular graph structures, which hinders scalability and cross-module causal reasoning. To address these challenges, we propose HugRAG, a framework that rethinks knowledge organization for graph-based RAG through causal gating across hierarchical modules. HugRAG explicitly models causal relationships to suppress spurious correlations while enabling scalable reasoning over large-scale knowledge graphs. Extensive experiments demonstrate that HugRAG consistently outperforms competitive graph-based RAG baselines across multiple datasets and evaluation metrics. Our work establishes a principled foundation for structured, scalable, and causally grounded RAG systems.
DiffCoT: Diffusion-styled Chain-of-Thought Reasoning in LLMs
Jan 07, 2026Chain-of-Thought (CoT) reasoning improves multi-step mathematical problem solving in large language models but remains vulnerable to exposure bias and error accumulation, as early mistakes propagate irreversibly through autoregressive decoding. In this work, we propose DiffCoT, a diffusion-styled CoT framework that reformulates CoT reasoning as an iterative denoising process. DiffCoT integrates diffusion principles at the reasoning-step level via a sliding-window mechanism, enabling unified generation and retrospective correction of intermediate steps while preserving token-level autoregression. To maintain causal consistency, we further introduce a causal diffusion noise schedule that respects the temporal structure of reasoning chains. Extensive experiments on three multi-step CoT reasoning benchmarks across diverse model backbones demonstrate that DiffCoT consistently outperforms existing CoT preference optimization methods, yielding improved robustness and error-correction capability in CoT reasoning.
Towards Comprehensive Stage-wise Benchmarking of Large Language Models in Fact-Checking
Jan 06, 2026Large Language Models (LLMs) are increasingly deployed in real-world fact-checking systems, yet existing evaluations focus predominantly on claim verification and overlook the broader fact-checking workflow, including claim extraction and evidence retrieval. This narrow focus prevents current benchmarks from revealing systematic reasoning failures, factual blind spots, and robustness limitations of modern LLMs. To bridge this gap, we present FactArena, a fully automated arena-style evaluation framework that conducts comprehensive, stage-wise benchmarking of LLMs across the complete fact-checking pipeline. FactArena integrates three key components: (i) an LLM-driven fact-checking process that standardizes claim decomposition, evidence retrieval via tool-augmented interactions, and justification-based verdict prediction; (ii) an arena-styled judgment mechanism guided by consolidated reference guidelines to ensure unbiased and consistent pairwise comparisons across heterogeneous judge agents; and (iii) an arena-driven claim-evolution module that adaptively generates more challenging and semantically controlled claims to probe LLMs' factual robustness beyond fixed seed data. Across 16 state-of-the-art LLMs spanning seven model families, FactArena produces stable and interpretable rankings. Our analyses further reveal significant discrepancies between static claim-verification accuracy and end-to-end fact-checking competence, highlighting the necessity of holistic evaluation. The proposed framework offers a scalable and trustworthy paradigm for diagnosing LLMs' factual reasoning, guiding future model development, and advancing the reliable deployment of LLMs in safety-critical fact-checking applications.
LLM-based Few-Shot Early Rumor Detection with Imitation Agent
Dec 20, 2025Early Rumor Detection (EARD) aims to identify the earliest point at which a claim can be accurately classified based on a sequence of social media posts. This is especially challenging in data-scarce settings. While Large Language Models (LLMs) perform well in few-shot NLP tasks, they are not well-suited for time-series data and are computationally expensive for both training and inference. In this work, we propose a novel EARD framework that combines an autonomous agent and an LLM-based detection model, where the agent acts as a reliable decision-maker for \textit{early time point determination}, while the LLM serves as a powerful \textit{rumor detector}. This approach offers the first solution for few-shot EARD, necessitating only the training of a lightweight agent and allowing the LLM to remain training-free. Extensive experiments on four real-world datasets show our approach boosts performance across LLMs and surpasses existing EARD methods in accuracy and earliness.
Explainable Ethical Assessment on Human Behaviors by Generating Conflicting Social Norms
Dec 16, 2025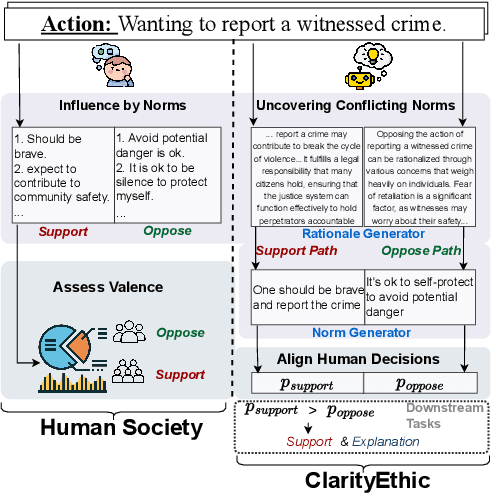
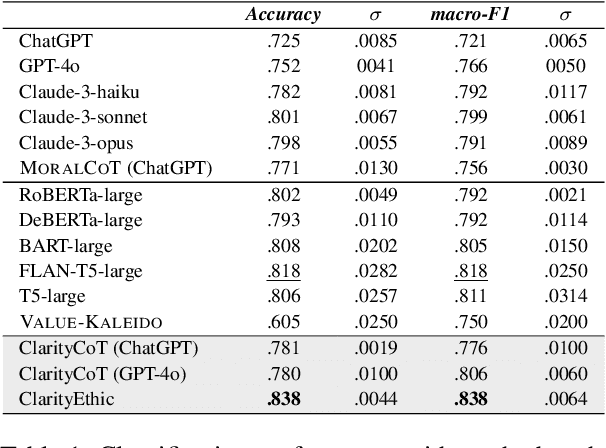
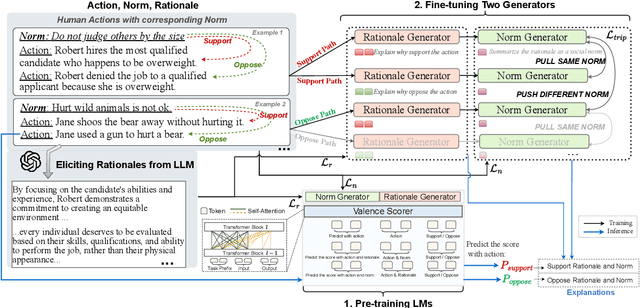
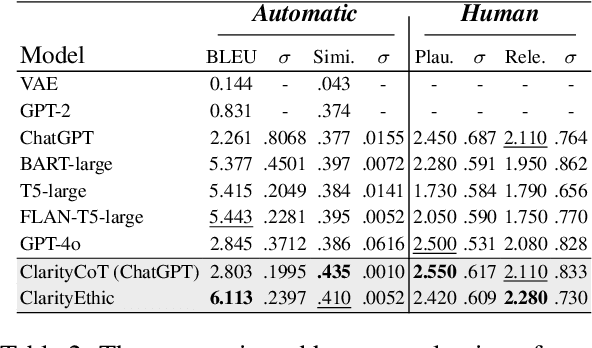
Human behaviors are often guided or constrained by social norms, which are defined as shared, commonsense rules. For example, underlying an action ``\textit{report a witnessed crime}" are social norms that inform our conduct, such as ``\textit{It is expected to be brave to report crimes}''. Current AI systems that assess valence (i.e., support or oppose) of human actions by leveraging large-scale data training not grounded on explicit norms may be difficult to explain, and thus untrustworthy. Emulating human assessors by considering social norms can help AI models better understand and predict valence. While multiple norms come into play, conflicting norms can create tension and directly influence human behavior. For example, when deciding whether to ``\textit{report a witnessed crime}'', one may balance \textit{bravery} against \textit{self-protection}. In this paper, we introduce \textit{ClarityEthic}, a novel ethical assessment approach, to enhance valence prediction and explanation by generating conflicting social norms behind human actions, which strengthens the moral reasoning capabilities of language models by using a contrastive learning strategy. Extensive experiments demonstrate that our method outperforms strong baseline approaches, and human evaluations confirm that the generated social norms provide plausible explanations for the assessment of human behaviors.
GeoGNN: Quantifying and Mitigating Semantic Drift in Text-Attributed Graphs
Nov 12, 2025Graph neural networks (GNNs) on text--attributed graphs (TAGs) typically encode node texts using pretrained language models (PLMs) and propagate these embeddings through linear neighborhood aggregation. However, the representation spaces of modern PLMs are highly non--linear and geometrically structured, where textual embeddings reside on curved semantic manifolds rather than flat Euclidean spaces. Linear aggregation on such manifolds inevitably distorts geometry and causes semantic drift--a phenomenon where aggregated representations deviate from the intrinsic manifold, losing semantic fidelity and expressive power. To quantitatively investigate this problem, this work introduces a local PCA--based metric that measures the degree of semantic drift and provides the first quantitative framework to analyze how different aggregation mechanisms affect manifold structure. Building upon these insights, we propose Geodesic Aggregation, a manifold--aware mechanism that aggregates neighbor information along geodesics via log--exp mappings on the unit sphere, ensuring that representations remain faithful to the semantic manifold during message passing. We further develop GeoGNN, a practical instantiation that integrates spherical attention with manifold interpolation. Extensive experiments across four benchmark datasets and multiple text encoders show that GeoGNN substantially mitigates semantic drift and consistently outperforms strong baselines, establishing the importance of manifold--aware aggregation in text--attributed graph learning.
MM-CRITIC: A Holistic Evaluation of Large Multimodal Models as Multimodal Critique
Nov 12, 2025



The ability of critique is vital for models to self-improve and serve as reliable AI assistants. While extensively studied in language-only settings, multimodal critique of Large Multimodal Models (LMMs) remains underexplored despite their growing capabilities in tasks like captioning and visual reasoning. In this work, we introduce MM-CRITIC, a holistic benchmark for evaluating the critique ability of LMMs across multiple dimensions: basic, correction, and comparison. Covering 8 main task types and over 500 tasks, MM-CRITIC collects responses from various LMMs with different model sizes and is composed of 4471 samples. To enhance the evaluation reliability, we integrate expert-informed ground answers into scoring rubrics that guide GPT-4o in annotating responses and generating reference critiques, which serve as anchors for trustworthy judgments. Extensive experiments validate the effectiveness of MM-CRITIC and provide a comprehensive assessment of leading LMMs' critique capabilities under multiple dimensions. Further analysis reveals some key insights, including the correlation between response quality and critique, and varying critique difficulty across evaluation dimensions. Our code is available at https://github.com/MichealZeng0420/MM-Critic.
Breaking the Adversarial Robustness-Performance Trade-off in Text Classification via Manifold Purification
Nov 11, 2025A persistent challenge in text classification (TC) is that enhancing model robustness against adversarial attacks typically degrades performance on clean data. We argue that this challenge can be resolved by modeling the distribution of clean samples in the encoder embedding manifold. To this end, we propose the Manifold-Correcting Causal Flow (MC^2F), a two-module system that operates directly on sentence embeddings. A Stratified Riemannian Continuous Normalizing Flow (SR-CNF) learns the density of the clean data manifold. It identifies out-of-distribution embeddings, which are then corrected by a Geodesic Purification Solver. This solver projects adversarial points back onto the learned manifold via the shortest path, restoring a clean, semantically coherent representation. We conducted extensive evaluations on text classification (TC) across three datasets and multiple adversarial attacks. The results demonstrate that our method, MC^2F, not only establishes a new state-of-the-art in adversarial robustness but also fully preserves performance on clean data, even yielding modest gains in accuracy.
MemeArena: Automating Context-Aware Unbiased Evaluation of Harmfulness Understanding for Multimodal Large Language Models
Oct 31, 2025The proliferation of memes on social media necessitates the capabilities of multimodal Large Language Models (mLLMs) to effectively understand multimodal harmfulness. Existing evaluation approaches predominantly focus on mLLMs' detection accuracy for binary classification tasks, which often fail to reflect the in-depth interpretive nuance of harmfulness across diverse contexts. In this paper, we propose MemeArena, an agent-based arena-style evaluation framework that provides a context-aware and unbiased assessment for mLLMs' understanding of multimodal harmfulness. Specifically, MemeArena simulates diverse interpretive contexts to formulate evaluation tasks that elicit perspective-specific analyses from mLLMs. By integrating varied viewpoints and reaching consensus among evaluators, it enables fair and unbiased comparisons of mLLMs' abilities to interpret multimodal harmfulness. Extensive experiments demonstrate that our framework effectively reduces the evaluation biases of judge agents, with judgment results closely aligning with human preferences, offering valuable insights into reliable and comprehensive mLLM evaluations in multimodal harmfulness understanding. Our code and data are publicly available at https://github.com/Lbotirx/MemeArena.