 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing LLM Arbitration Behavior over Pre-evidence Epistemic States in RAG-based Fact-Checking
May 31, 2026In RAG-based fact-checking, LLMs are increasingly used as verifiers to check given claims against retrieved evidence. Their parametric knowledge can induce pre-evidence tendencies that may conflict with the retrieved context, yet existing evaluation frameworks do not characterize such prior-context discrepancy or measure how verifiers arbitrate between parametric and contextual signals. We introduce \textsc{PAVE} (\emph{Prior-Aware Verifier Evaluation}), a diagnostic testbed that stratifies an LLM verifier into four epistemic states based on the correctness and confidence of its pre-evidence prior and evaluates its arbitration behavior on this new benchmark, i.e., whether it persists in correct prior under misleading evidence, and whether it corrects wrong prior when accurate evidence is provided. Experiments across seven LLMs reveal unreliable and highly model-dependent prior-context arbitration, highlighting the importance of verifier selection for real-world RAG-based fact-checking applications. Based on these findings, we propose a lightweight JSD-based test-time arbitration method that improves factual reliability without modifying the underlying model, achieving competitive performance across diverse LLM families.
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
Apr 12, 2026Chain-of-Thought (CoT) prompting has improved LLM reasoning, but models often generate explanations that appear coherent while containing unfaithful intermediate steps. Existing self-evaluation approaches are prone to inherent biases: the model may confidently endorse coherence even when the step-to-step implication is not valid, leading to unreliable faithfulness evaluation. We propose FACT-E, a causality-inspired framework for evaluating CoT quality. FACT-E uses controlled perturbations as an instrumental signal to separate genuine step-to-step dependence from bias-driven artifacts, producing more reliable faithfulness estimates (\textit{intra-chain faithfulness}). To select trustworthy trajectories, FACT-E jointly considers \textit{intra-chain faithfulness} and \textit{CoT-to-answer consistency}, ensuring that selected chains are both faithful internally and supportive of the correct final answer. Experiments on GSM8K, MATH, and CommonsenseQA show that FACT-E improves reasoning-trajectory selection and yields stronger in-context learning exemplars. FACT-E also reliably detects flawed reasoning under noisy conditions, providing a robust metric for trustworthy LLM reasoning.
On the Wings of Imagination: Conflicting Script-based Multi-role Framework for Humor Caption Generation
Feb 06, 2026Humor is a commonly used and intricate human language in daily life. Humor generation, especially in multi-modal scenarios, is a challenging task for large language models (LLMs), which is typically as funny caption generation for images, requiring visual understanding, humor reasoning, creative imagination, and so on. Existing LLM-based approaches rely on reasoning chains or self-improvement, which suffer from limited creativity and interpretability. To address these bottlenecks, we develop a novel LLM-based humor generation mechanism based on a fundamental humor theory, GTVH. To produce funny and script-opposite captions, we introduce a humor-theory-driven multi-role LLM collaboration framework augmented with humor retrieval (HOMER). The framework consists of three LLM-based roles: (1) conflicting-script extractor that grounds humor in key script oppositions, forming the basis of caption generation; (2) retrieval-augmented hierarchical imaginator that identifies key humor targets and expands the creative space of them through diverse associations structured as imagination trees; and (3) caption generator that produces funny and diverse captions conditioned on the obtained knowledge. Extensive experiments on two New Yorker Cartoon benchmarking datasets show that HOMER outperforms state-of-the-art baselines and powerful LLM reasoning strategies on multi-modal humor captioning.
Explainable Ethical Assessment on Human Behaviors by Generating Conflicting Social Norms
Dec 16, 2025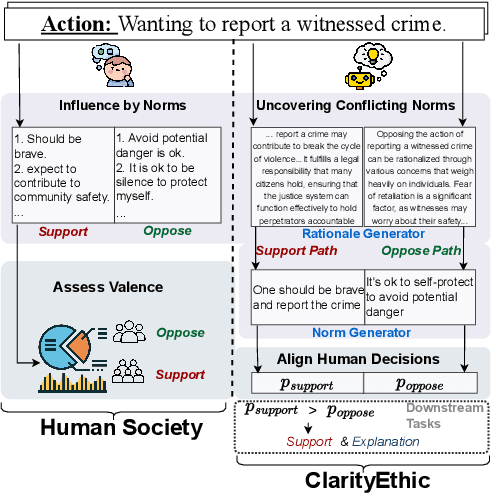
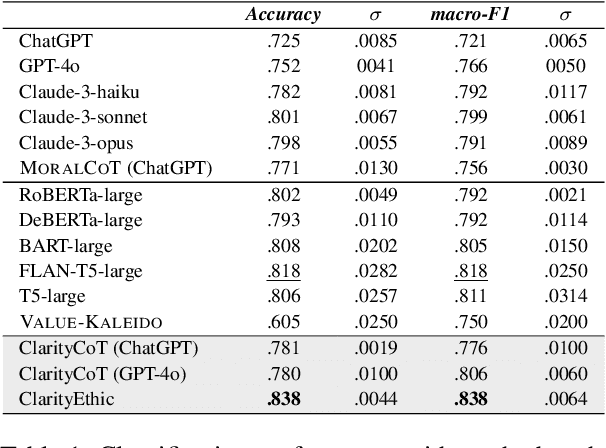
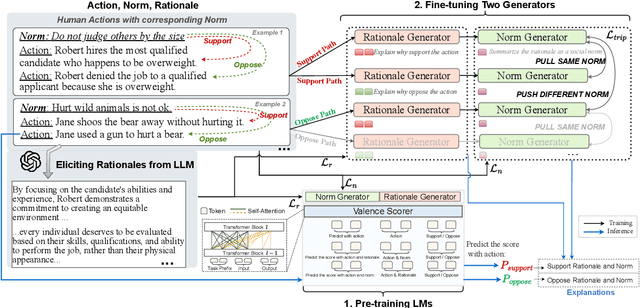
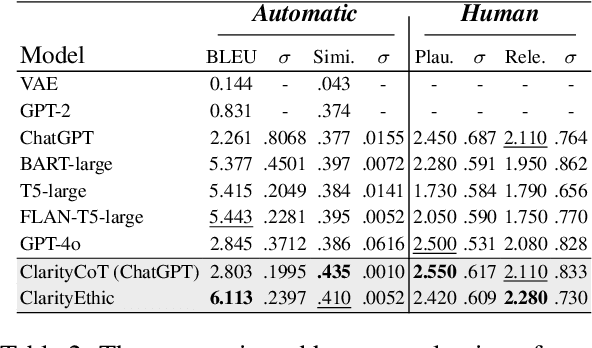
Human behaviors are often guided or constrained by social norms, which are defined as shared, commonsense rules. For example, underlying an action ``\textit{report a witnessed crime}" are social norms that inform our conduct, such as ``\textit{It is expected to be brave to report crimes}''. Current AI systems that assess valence (i.e., support or oppose) of human actions by leveraging large-scale data training not grounded on explicit norms may be difficult to explain, and thus untrustworthy. Emulating human assessors by considering social norms can help AI models better understand and predict valence. While multiple norms come into play, conflicting norms can create tension and directly influence human behavior. For example, when deciding whether to ``\textit{report a witnessed crime}'', one may balance \textit{bravery} against \textit{self-protection}. In this paper, we introduce \textit{ClarityEthic}, a novel ethical assessment approach, to enhance valence prediction and explanation by generating conflicting social norms behind human actions, which strengthens the moral reasoning capabilities of language models by using a contrastive learning strategy. Extensive experiments demonstrate that our method outperforms strong baseline approaches, and human evaluations confirm that the generated social norms provide plausible explanations for the assessment of human behaviors.
ClarityEthic: Explainable Moral Judgment Utilizing Contrastive Ethical Insights from Large Language Models
Dec 17, 2024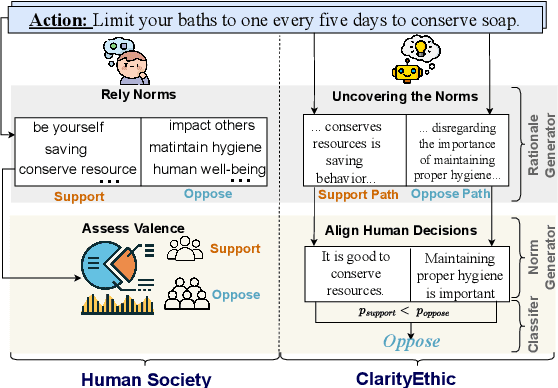
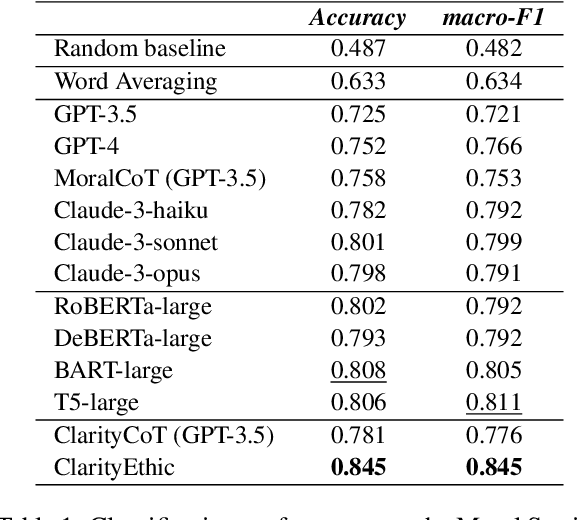
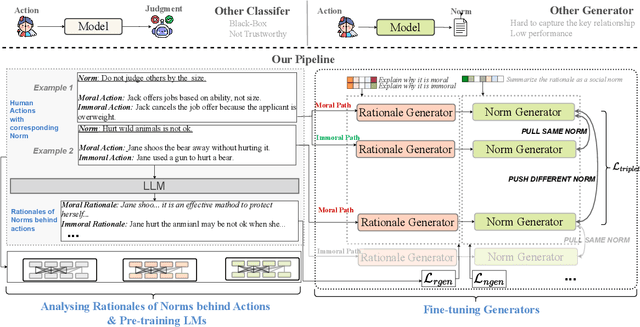
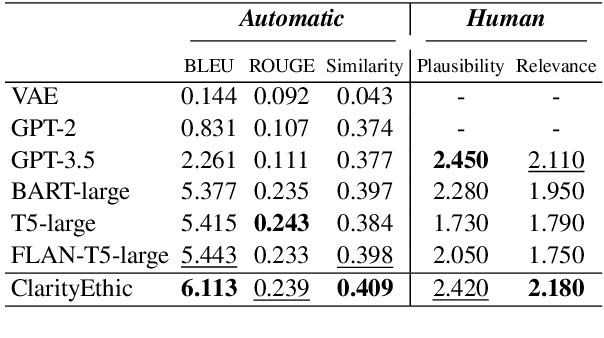
With the rise and widespread use of Large Language Models (LLMs), ensuring their safety is crucial to prevent harm to humans and promote ethical behaviors. However, directly assessing value valence (i.e., support or oppose) by leveraging large-scale data training is untrustworthy and inexplainable. We assume that emulating humans to rely on social norms to make moral decisions can help LLMs understand and predict moral judgment. However, capturing human values remains a challenge, as multiple related norms might conflict in specific contexts. Consider norms that are upheld by the majority and promote the well-being of society are more likely to be accepted and widely adopted (e.g., "don't cheat,"). Therefore, it is essential for LLM to identify the appropriate norms for a given scenario before making moral decisions. To this end, we introduce a novel moral judgment approach called \textit{ClarityEthic} that leverages LLMs' reasoning ability and contrastive learning to uncover relevant social norms for human actions from different perspectives and select the most reliable one to enhance judgment accuracy. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches in moral judgment tasks. Moreover, human evaluations confirm that the generated social norms provide plausible explanations that support the judgments. This suggests that modeling human moral judgment with the emulating humans moral strategy is promising for improving the ethical behaviors of LLMs.
From General to Specific: Utilizing General Hallucation to Automatically Measure the Role Relationship Fidelity for Specific Role-Play Agents
Nov 12, 2024



The advanced role-playing capabilities of Large Language Models (LLMs) have paved the way for developing Role-Playing Agents (RPAs). However, existing benchmarks, such as HPD, which incorporates manually scored character relationships into the context for LLMs to sort coherence, and SocialBench, which uses specific profiles generated by LLMs in the context of multiple-choice tasks to assess character preferences, face limitations like poor generalizability, implicit and inaccurate judgments, and excessive context length. To address the above issues, we propose an automatic, scalable, and generalizable paradigm. Specifically, we construct a benchmark by extracting relations from a general knowledge graph and leverage RPA's inherent hallucination properties to prompt it to interact across roles, employing ChatGPT for stance detection and defining relationship hallucination along with three related metrics. Extensive experiments validate the effectiveness and stability of our metrics. Our findings further explore factors influencing these metrics and discuss the trade-off between relationship hallucination and factuality.
Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction
Apr 22, 2024



The task of condensing large chunks of textual information into concise and structured tables has gained attention recently due to the emergence of Large Language Models (LLMs) and their potential benefit for downstream tasks, such as text summarization and text mining. Previous approaches often generate tables that directly replicate information from the text, limiting their applicability in broader contexts, as text-to-table generation in real-life scenarios necessitates information extraction, reasoning, and integration. However, there is a lack of both datasets and methodologies towards this task. In this paper, we introduce LiveSum, a new benchmark dataset created for generating summary tables of competitions based on real-time commentary texts. We evaluate the performances of state-of-the-art LLMs on this task in both fine-tuning and zero-shot settings, and additionally propose a novel pipeline called $T^3$(Text-Tuple-Table) to improve their performances. Extensive experimental results demonstrate that LLMs still struggle with this task even after fine-tuning, while our approach can offer substantial performance gains without explicit training. Further analyses demonstrate that our method exhibits strong generalization abilities, surpassing previous approaches on several other text-to-table datasets. Our code and data can be found at https://github.com/HKUST-KnowComp/LiveSum-TTT.
Clinical Assistant Diagnosis for Electronic Medical Record Based on Convolutional Neural Network
Apr 23, 2018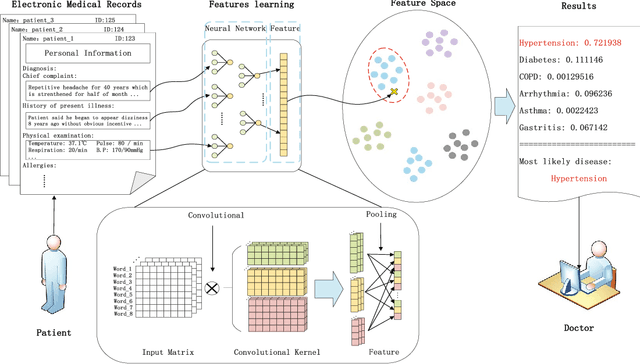

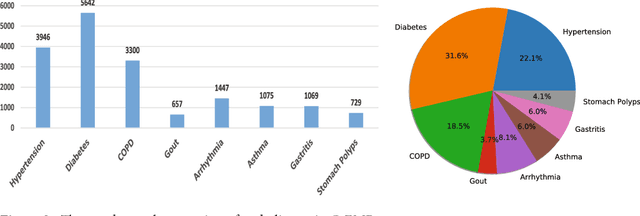
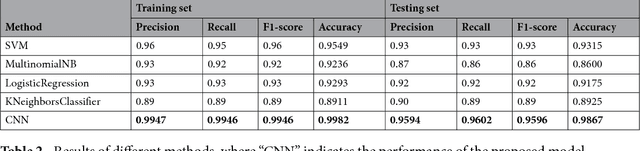
Automatically extracting useful information from electronic medical records along with conducting disease diagnoses is a promising task for both clinical decision support(CDS) and neural language processing(NLP). Most of the existing systems are based on artificially constructed knowledge bases, and then auxiliary diagnosis is done by rule matching. In this study, we present a clinical intelligent decision approach based on Convolutional Neural Networks(CNN), which can automatically extract high-level semantic information of electronic medical records and then perform automatic diagnosis without artificial construction of rules or knowledge bases. We use collected 18,590 copies of the real-world clinical electronic medical records to train and test the proposed model. Experimental results show that the proposed model can achieve 98.67\% accuracy and 96.02\% recall, which strongly supports that using convolutional neural network to automatically learn high-level semantic features of electronic medical records and then conduct assist diagnosis is feasible and effective.