 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-Transformer: Towards Better Document-to-Document Neural Machine Translation
Dec 12, 2022



Directly training a document-to-document (Doc2Doc) neural machine translation (NMT) via Transformer from scratch, especially on small datasets usually fails to converge. Our dedicated probing tasks show that 1) both the absolute position and relative position information gets gradually weakened or even vanished once it reaches the upper encoder layers, and 2) the vanishing of absolute position information in encoder output causes the training failure of Doc2Doc NMT. To alleviate this problem, we propose a position-aware Transformer (P-Transformer) to enhance both the absolute and relative position information in both self-attention and cross-attention. Specifically, we integrate absolute positional information, i.e., position embeddings, into the query-key pairs both in self-attention and cross-attention through a simple yet effective addition operation. Moreover, we also integrate relative position encoding in self-attention. The proposed P-Transformer utilizes sinusoidal position encoding and does not require any task-specified position embedding, segment embedding, or attention mechanism. Through the above methods, we build a Doc2Doc NMT model with P-Transformer, which ingests the source document and completely generates the target document in a sequence-to-sequence (seq2seq) way. In addition, P-Transformer can be applied to seq2seq-based document-to-sentence (Doc2Sent) and sentence-to-sentence (Sent2Sent) translation. Extensive experimental results of Doc2Doc NMT show that P-Transformer significantly outperforms strong baselines on widely-used 9 document-level datasets in 7 language pairs, covering small-, middle-, and large-scales, and achieves a new state-of-the-art. Experimentation on discourse phenomena shows that our Doc2Doc NMT models improve the translation quality in both BLEU and discourse coherence. We make our code available on Github.
Federated Learning on Non-IID Graphs via Structural Knowledge Sharing
Nov 23, 2022



Graph neural networks (GNNs) have shown their superiority in modeling graph data. Owing to the advantages of federated learning, federated graph learning (FGL) enables clients to train strong GNN models in a distributed manner without sharing their private data. A core challenge in federated systems is the non-IID problem, which also widely exists in real-world graph data. For example, local data of clients may come from diverse datasets or even domains, e.g., social networks and molecules, increasing the difficulty for FGL methods to capture commonly shared knowledge and learn a generalized encoder. From real-world graph datasets, we observe that some structural properties are shared by various domains, presenting great potential for sharing structural knowledge in FGL. Inspired by this, we propose FedStar, an FGL framework that extracts and shares the common underlying structure information for inter-graph federated learning tasks. To explicitly extract the structure information rather than encoding them along with the node features, we define structure embeddings and encode them with an independent structure encoder. Then, the structure encoder is shared across clients while the feature-based knowledge is learned in a personalized way, making FedStar capable of capturing more structure-based domain-invariant information and avoiding feature misalignment issues. We perform extensive experiments over both cross-dataset and cross-domain non-IID FGL settings, demonstrating the superiority of FedStar.
CCPrompt: Counterfactual Contrastive Prompt-Tuning for Many-Class Classification
Nov 11, 2022



With the success of the prompt-tuning paradigm in Natural Language Processing (NLP), various prompt templates have been proposed to further stimulate specific knowledge for serving downstream tasks, e.g., machine translation, text generation, relation extraction, and so on. Existing prompt templates are mainly shared among all training samples with the information of task description. However, training samples are quite diverse. The sharing task description is unable to stimulate the unique task-related information in each training sample, especially for tasks with the finite-label space. To exploit the unique task-related information, we imitate the human decision process which aims to find the contrastive attributes between the objective factual and their potential counterfactuals. Thus, we propose the \textbf{C}ounterfactual \textbf{C}ontrastive \textbf{Prompt}-Tuning (CCPrompt) approach for many-class classification, e.g., relation classification, topic classification, and entity typing. Compared with simple classification tasks, these tasks have more complex finite-label spaces and are more rigorous for prompts. First of all, we prune the finite label space to construct fact-counterfactual pairs. Then, we exploit the contrastive attributes by projecting training instances onto every fact-counterfactual pair. We further set up global prototypes corresponding with all contrastive attributes for selecting valid contrastive attributes as additional tokens in the prompt template. Finally, a simple Siamese representation learning is employed to enhance the robustness of the model. We conduct experiments on relation classification, topic classification, and entity typing tasks in both fully supervised setting and few-shot setting. The results indicate that our model outperforms former baselines.
ngram-OAXE: Phrase-Based Order-Agnostic Cross Entropy for Non-Autoregressive Machine Translation
Oct 08, 2022
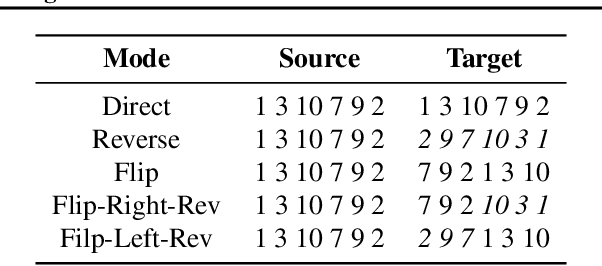
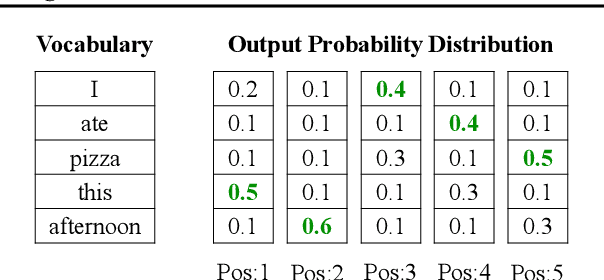
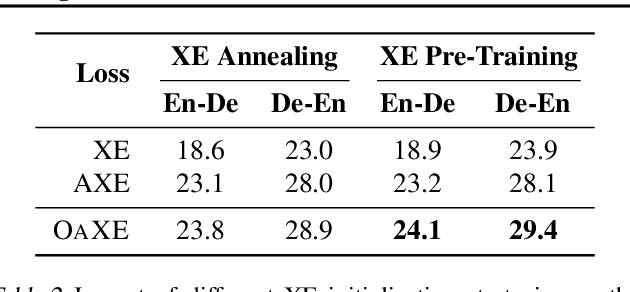
Recently, a new training oaxe loss has proven effective to ameliorate the effect of multimodality for non-autoregressive translation (NAT), which removes the penalty of word order errors in the standard cross-entropy loss. Starting from the intuition that reordering generally occurs between phrases, we extend oaxe by only allowing reordering between ngram phrases and still requiring a strict match of word order within the phrases. Extensive experiments on NAT benchmarks across language pairs and data scales demonstrate the effectiveness and universality of our approach. %Further analyses show that the proposed ngram-oaxe alleviates the multimodality problem with a better modeling of phrase translation. Further analyses show that ngram-oaxe indeed improves the translation of ngram phrases, and produces more fluent translation with a better modeling of sentence structure.
Federated Learning from Pre-Trained Models: A Contrastive Learning Approach
Sep 21, 2022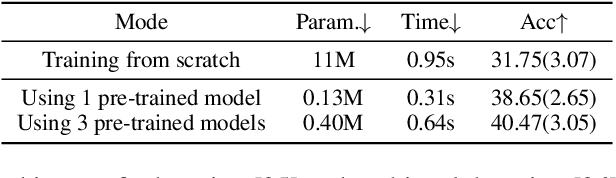
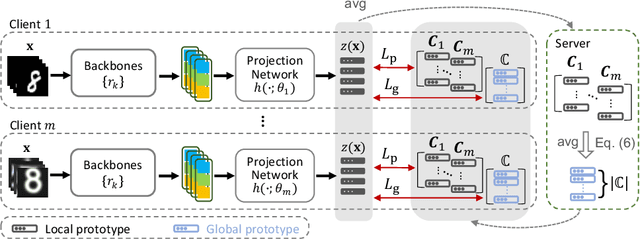
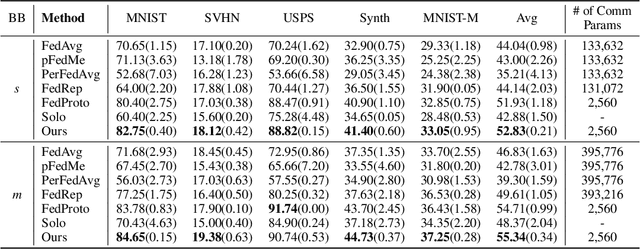
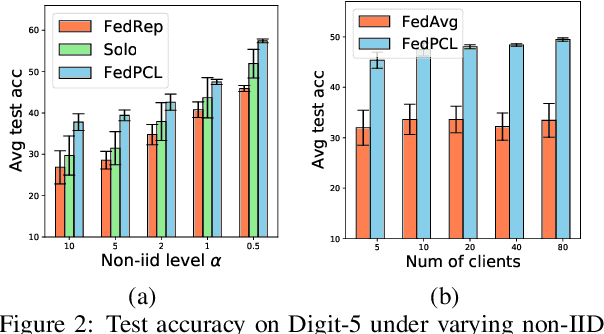
Federated Learning (FL) is a machine learning paradigm that allows decentralized clients to learn collaboratively without sharing their private data. However, excessive computation and communication demands pose challenges to current FL frameworks, especially when training large-scale models. To prevent these issues from hindering the deployment of FL systems, we propose a lightweight framework where clients jointly learn to fuse the representations generated by multiple fixed pre-trained models rather than training a large-scale model from scratch. This leads us to a more practical FL problem by considering how to capture more client-specific and class-relevant information from the pre-trained models and jointly improve each client's ability to exploit those off-the-shelf models. In this work, we design a Federated Prototype-wise Contrastive Learning (FedPCL) approach which shares knowledge across clients through their class prototypes and builds client-specific representations in a prototype-wise contrastive manner. Sharing prototypes rather than learnable model parameters allows each client to fuse the representations in a personalized way while keeping the shared knowledge in a compact form for efficient communication. We perform a thorough evaluation of the proposed FedPCL in the lightweight framework, measuring and visualizing its ability to fuse various pre-trained models on popular FL datasets.
Improving Compositional Generalization in Math Word Problem Solving
Sep 03, 2022



Compositional generalization refers to a model's capability to generalize to newly composed input data based on the data components observed during training. It has triggered a series of compositional generalization analysis on different tasks as generalization is an important aspect of language and problem solving skills. However, the similar discussion on math word problems (MWPs) is limited. In this manuscript, we study compositional generalization in MWP solving. Specifically, we first introduce a data splitting method to create compositional splits from existing MWP datasets. Meanwhile, we synthesize data to isolate the effect of compositions. To improve the compositional generalization in MWP solving, we propose an iterative data augmentation method that includes diverse compositional variation into training data and could collaborate with MWP methods. During the evaluation, we examine a set of methods and find all of them encounter severe performance loss on the evaluated datasets. We also find our data augmentation method could significantly improve the compositional generalization of general MWP methods. Code is available at https://github.com/demoleiwang/CGMWP.
Disentangling Identity and Pose for Facial Expression Recognition
Aug 17, 2022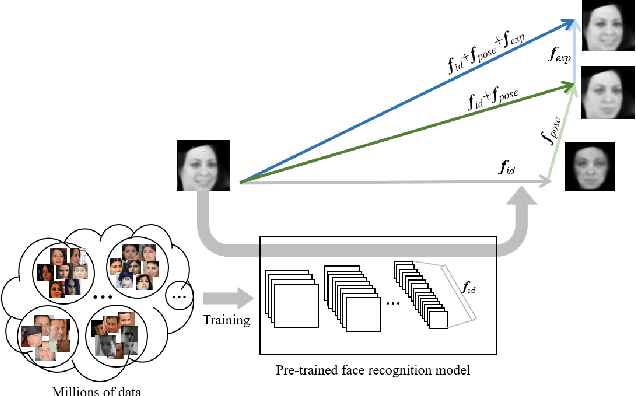

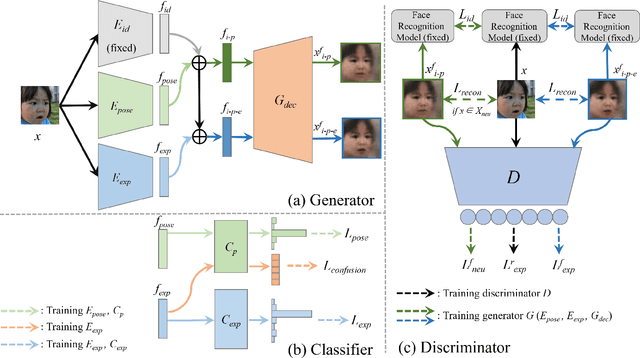
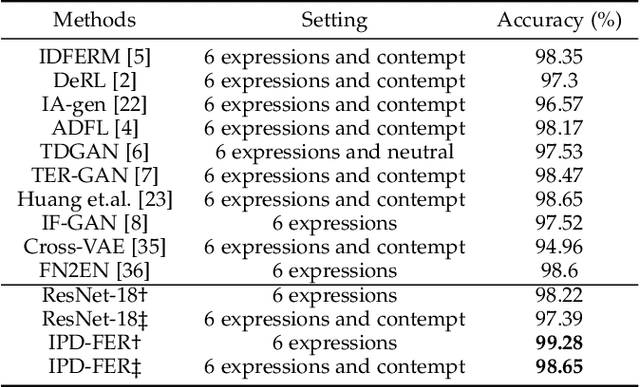
Facial expression recognition (FER) is a challenging problem because the expression component is always entangled with other irrelevant factors, such as identity and head pose. In this work, we propose an identity and pose disentangled facial expression recognition (IPD-FER) model to learn more discriminative feature representation. We regard the holistic facial representation as the combination of identity, pose and expression. These three components are encoded with different encoders. For identity encoder, a well pre-trained face recognition model is utilized and fixed during training, which alleviates the restriction on specific expression training data in previous works and makes the disentanglement practicable on in-the-wild datasets. At the same time, the pose and expression encoder are optimized with corresponding labels. Combining identity and pose feature, a neutral face of input individual should be generated by the decoder. When expression feature is added, the input image should be reconstructed. By comparing the difference between synthesized neutral and expressional images of the same individual, the expression component is further disentangled from identity and pose. Experimental results verify the effectiveness of our method on both lab-controlled and in-the-wild databases and we achieve state-of-the-art recognition performance.
Unsupervised Video Domain Adaptation: A Disentanglement Perspective
Aug 15, 2022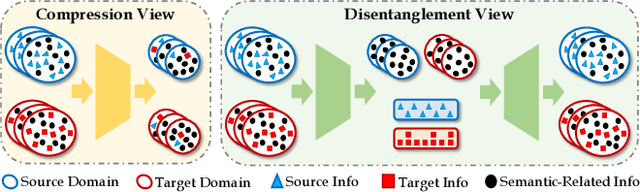
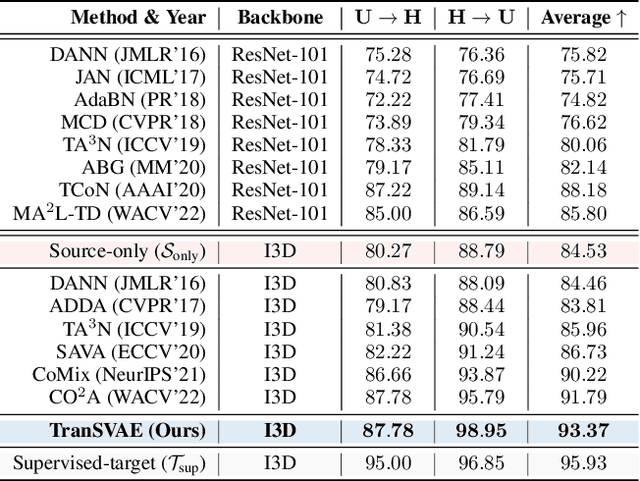
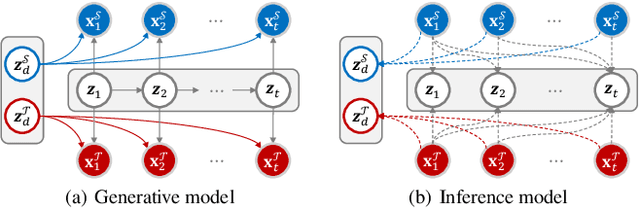
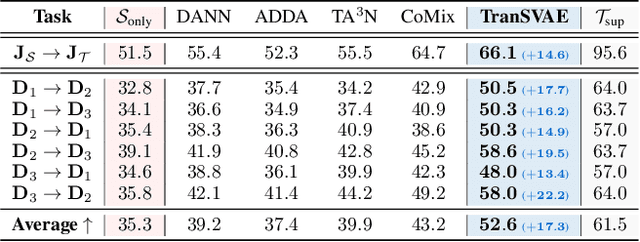
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view. Our key idea is to disentangle the domain-related information from the data during the adaptation process. Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information. A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods. Code is publicly available at https://github.com/ldkong1205/TranSVAE.
Boosting Facial Expression Recognition by A Semi-Supervised Progressive Teacher
May 28, 2022
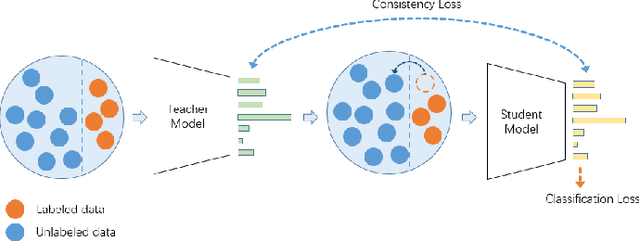

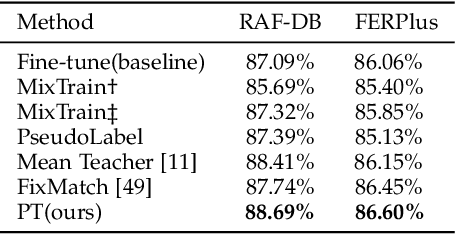
In this paper, we aim to improve the performance of in-the-wild Facial Expression Recognition (FER) by exploiting semi-supervised learning. Large-scale labeled data and deep learning methods have greatly improved the performance of image recognition. However, the performance of FER is still not ideal due to the lack of training data and incorrect annotations (e.g., label noises). Among existing in-the-wild FER datasets, reliable ones contain insufficient data to train robust deep models while large-scale ones are annotated in lower quality. To address this problem, we propose a semi-supervised learning algorithm named Progressive Teacher (PT) to utilize reliable FER datasets as well as large-scale unlabeled expression images for effective training. On the one hand, PT introduces semi-supervised learning method to relieve the shortage of data in FER. On the other hand, it selects useful labeled training samples automatically and progressively to alleviate label noise. PT uses selected clean labeled data for computing the supervised classification loss and unlabeled data for unsupervised consistency loss. Experiments on widely-used databases RAF-DB and FERPlus validate the effectiveness of our method, which achieves state-of-the-art performance with accuracy of 89.57% on RAF-DB. Additionally, when the synthetic noise rate reaches even 30%, the performance of our PT algorithm only degrades by 4.37%.
FedNoiL: A Simple Two-Level Sampling Method for Federated Learning with Noisy Labels
May 20, 2022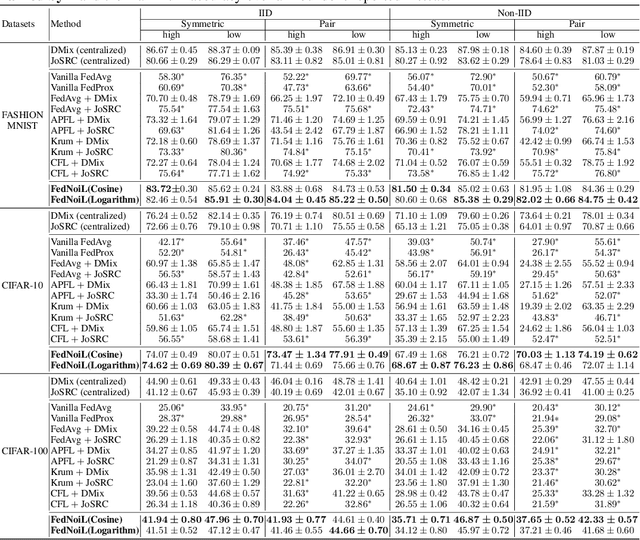
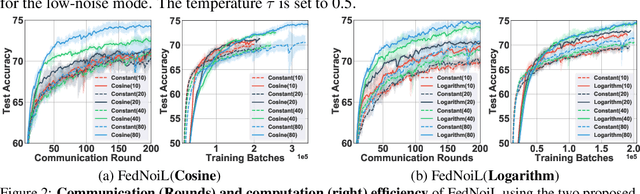
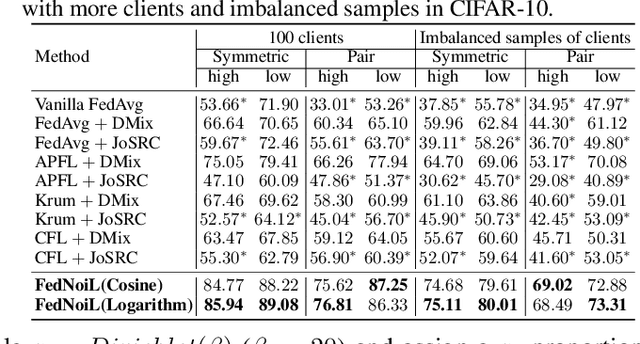
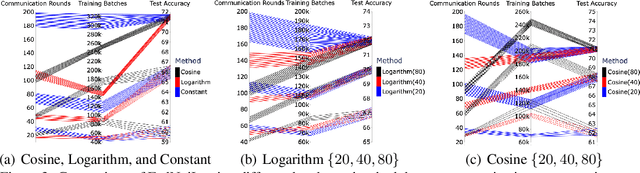
Federated learning (FL) aims at training a global model on the server side while the training data are collected and located at the local devices. Hence, the labels in practice are usually annotated by clients of varying expertise or criteria and thus contain different amounts of noises. Local training on noisy labels can easily result in overfitting to noisy labels, which is devastating to the global model through aggregation. Although recent robust FL methods take malicious clients into account, they have not addressed local noisy labels on each device and the impact to the global model. In this paper, we develop a simple two-level sampling method "FedNoiL" that (1) selects clients for more robust global aggregation on the server; and (2) selects clean labels and correct pseudo-labels at the client end for more robust local training. The sampling probabilities are built upon clean label detection by the global model. Moreover, we investigate different schedules changing the local epochs between aggregations over the course of FL, which notably improves the communication and computation efficiency in noisy label setting. In experiments with homogeneous/heterogeneous data distributions and noise ratios, we observed that direct combinations of SOTA FL methods with SOTA noisy-label learning methods can easily fail but our method consistently achieves better and robust performance.