 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexSpeech: Towards Stable, Controllable and Expressive Text-to-Speech
May 08, 2025Current speech generation research can be categorized into two primary classes: non-autoregressive and autoregressive. The fundamental distinction between these approaches lies in the duration prediction strategy employed for predictable-length sequences. The NAR methods ensure stability in speech generation by explicitly and independently modeling the duration of each phonetic unit. Conversely, AR methods employ an autoregressive paradigm to predict the compressed speech token by implicitly modeling duration with Markov properties. Although this approach improves prosody, it does not provide the structural guarantees necessary for stability. To simultaneously address the issues of stability and naturalness in speech generation, we propose FlexSpeech, a stable, controllable, and expressive TTS model. The motivation behind FlexSpeech is to incorporate Markov dependencies and preference optimization directly on the duration predictor to boost its naturalness while maintaining explicit modeling of the phonetic units to ensure stability. Specifically, we decompose the speech generation task into two components: an AR duration predictor and a NAR acoustic model. The acoustic model is trained on a substantial amount of data to learn to render audio more stably, given reference audio prosody and phone durations. The duration predictor is optimized in a lightweight manner for different stylistic variations, thereby enabling rapid style transfer while maintaining a decoupled relationship with the specified speaker timbre. Experimental results demonstrate that our approach achieves SOTA stability and naturalness in zero-shot TTS. More importantly, when transferring to a specific stylistic domain, we can accomplish lightweight optimization of the duration module solely with about 100 data samples, without the need to adjust the acoustic model, thereby enabling rapid and stable style transfer.
From Specificity to Generality: Revisiting Generalizable Artifacts in Detecting Face Deepfakes
Apr 07, 2025Detecting deepfakes has been an increasingly important topic, especially given the rapid development of AI generation techniques. In this paper, we ask: How can we build a universal detection framework that is effective for most facial deepfakes? One significant challenge is the wide variety of deepfake generators available, resulting in varying forgery artifacts (e.g., lighting inconsistency, color mismatch, etc). But should we ``teach" the detector to learn all these artifacts separately? It is impossible and impractical to elaborate on them all. So the core idea is to pinpoint the more common and general artifacts across different deepfakes. Accordingly, we categorize deepfake artifacts into two distinct yet complementary types: Face Inconsistency Artifacts (FIA) and Up-Sampling Artifacts (USA). FIA arise from the challenge of generating all intricate details, inevitably causing inconsistencies between the complex facial features and relatively uniform surrounding areas. USA, on the other hand, are the inevitable traces left by the generator's decoder during the up-sampling process. This categorization stems from the observation that all existing deepfakes typically exhibit one or both of these artifacts. To achieve this, we propose a new data-level pseudo-fake creation framework that constructs fake samples with only the FIA and USA, without introducing extra less-general artifacts. Specifically, we employ a super-resolution to simulate the USA, while design a Blender module that uses image-level self-blending on diverse facial regions to create the FIA. We surprisingly found that, with this intuitive design, a standard image classifier trained only with our pseudo-fake data can non-trivially generalize well to unseen deepfakes.
Qwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
InSerter: Speech Instruction Following with Unsupervised Interleaved Pre-training
Mar 04, 2025



Recent advancements in speech large language models (SpeechLLMs) have attracted considerable attention. Nonetheless, current methods exhibit suboptimal performance in adhering to speech instructions. Notably, the intelligence of models significantly diminishes when processing speech-form input as compared to direct text-form input. Prior work has attempted to mitigate this semantic inconsistency between speech and text representations through techniques such as representation and behavior alignment, which involve the meticulous design of data pairs during the post-training phase. In this paper, we introduce a simple and scalable training method called InSerter, which stands for Interleaved Speech-Text Representation Pre-training. InSerter is designed to pre-train large-scale unsupervised speech-text sequences, where the speech is synthesized from randomly selected segments of an extensive text corpus using text-to-speech conversion. Consequently, the model acquires the ability to generate textual continuations corresponding to the provided speech segments, obviating the need for intensive data design endeavors. To systematically evaluate speech instruction-following capabilities, we introduce SpeechInstructBench, the first comprehensive benchmark specifically designed for speech-oriented instruction-following tasks. Our proposed InSerter achieves SOTA performance in SpeechInstructBench and demonstrates superior or competitive results across diverse speech processing tasks.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025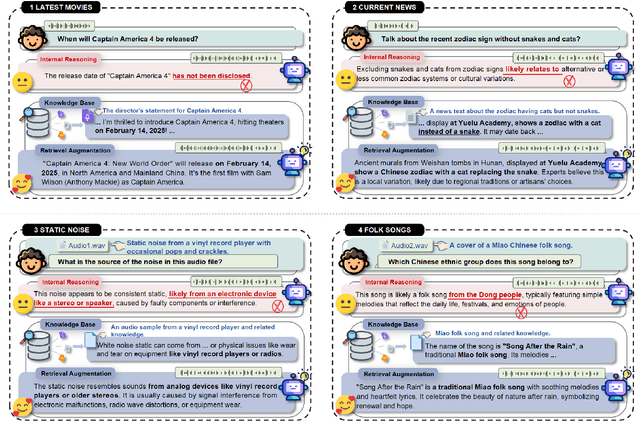
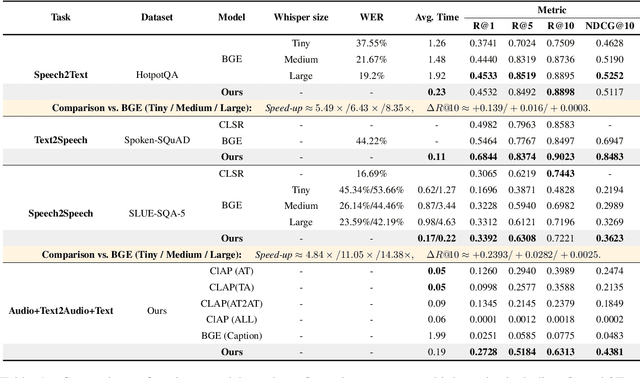
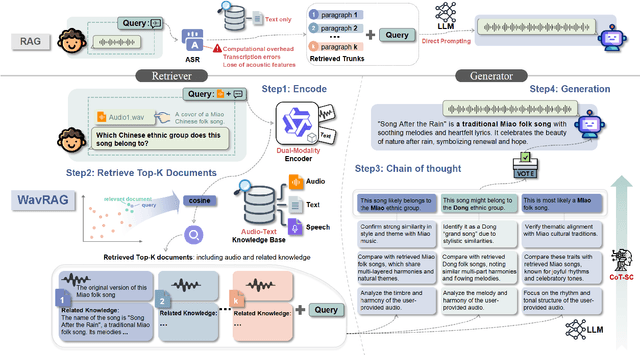
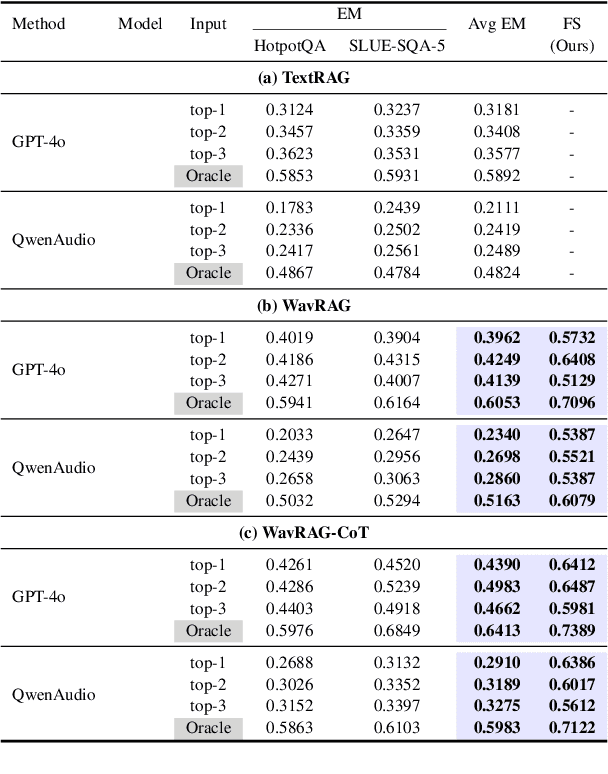
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
HedgeAgents: A Balanced-aware Multi-agent Financial Trading System
Feb 17, 2025



As automated trading gains traction in the financial market, algorithmic investment strategies are increasingly prominent. While Large Language Models (LLMs) and Agent-based models exhibit promising potential in real-time market analysis and trading decisions, they still experience a significant -20% loss when confronted with rapid declines or frequent fluctuations, impeding their practical application. Hence, there is an imperative to explore a more robust and resilient framework. This paper introduces an innovative multi-agent system, HedgeAgents, aimed at bolstering system robustness via ``hedging'' strategies. In this well-balanced system, an array of hedging agents has been tailored, where HedgeAgents consist of a central fund manager and multiple hedging experts specializing in various financial asset classes. These agents leverage LLMs' cognitive capabilities to make decisions and coordinate through three types of conferences. Benefiting from the powerful understanding of LLMs, our HedgeAgents attained a 70% annualized return and a 400% total return over a period of 3 years. Moreover, we have observed with delight that HedgeAgents can even formulate investment experience comparable to those of human experts (https://hedgeagents.github.io/).
RTBAgent: A LLM-based Agent System for Real-Time Bidding
Feb 02, 2025



Real-Time Bidding (RTB) enables advertisers to place competitive bids on impression opportunities instantaneously, striving for cost-effectiveness in a highly competitive landscape. Although RTB has widely benefited from the utilization of technologies such as deep learning and reinforcement learning, the reliability of related methods often encounters challenges due to the discrepancies between online and offline environments and the rapid fluctuations of online bidding. To handle these challenges, RTBAgent is proposed as the first RTB agent system based on large language models (LLMs), which synchronizes real competitive advertising bidding environments and obtains bidding prices through an integrated decision-making process. Specifically, obtaining reasoning ability through LLMs, RTBAgent is further tailored to be more professional for RTB via involved auxiliary modules, i.e., click-through rate estimation model, expert strategy knowledge, and daily reflection. In addition, we propose a two-step decision-making process and multi-memory retrieval mechanism, which enables RTBAgent to review historical decisions and transaction records and subsequently make decisions more adaptive to market changes in real-time bidding. Empirical testing with real advertising datasets demonstrates that RTBAgent significantly enhances profitability. The RTBAgent code will be publicly accessible at: https://github.com/CaiLeng/RTBAgent.
ViSymRe: Vision-guided Multimodal Symbolic Regression
Dec 15, 2024Symbolic regression automatically searches for mathematical equations to reveal underlying mechanisms within datasets, offering enhanced interpretability compared to black box models. Traditionally, symbolic regression has been considered to be purely numeric-driven, with insufficient attention given to the potential contributions of visual information in augmenting this process. When dealing with high-dimensional and complex datasets, existing symbolic regression models are often inefficient and tend to generate overly complex equations, making subsequent mechanism analysis complicated. In this paper, we propose the vision-guided multimodal symbolic regression model, called ViSymRe, that systematically explores how visual information can improve various metrics of symbolic regression. Compared to traditional models, our proposed model has the following innovations: (1) It integrates three modalities: vision, symbol and numeric to enhance symbolic regression, enabling the model to benefit from the strengths of each modality; (2) It establishes a meta-learning framework that can learn from historical experiences to efficiently solve new symbolic regression problems; (3) It emphasizes the simplicity and structural rationality of the equations rather than merely numerical fitting. Extensive experiments show that our proposed model exhibits strong generalization capability and noise resistance. The equations it generates outperform state-of-the-art numeric-only baselines in terms of fitting effect, simplicity and structural accuracy, thus being able to facilitate accurate mechanism analysis and the development of theoretical models.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024



Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
$\boldsymbolμ\mathbf{P^2}$: Effective Sharpness Aware Minimization Requires Layerwise Perturbation Scaling
Oct 31, 2024Sharpness Aware Minimization (SAM) enhances performance across various neural architectures and datasets. As models are continually scaled up to improve performance, a rigorous understanding of SAM's scaling behaviour is paramount. To this end, we study the infinite-width limit of neural networks trained with SAM, using the Tensor Programs framework. Our findings reveal that the dynamics of standard SAM effectively reduce to applying SAM solely in the last layer in wide neural networks, even with optimal hyperparameters. In contrast, we identify a stable parameterization with layerwise perturbation scaling, which we call $\textit{Maximal Update and Perturbation Parameterization}$ ($\mu$P$^2$), that ensures all layers are both feature learning and effectively perturbed in the limit. Through experiments with MLPs, ResNets and Vision Transformers, we empirically demonstrate that $\mu$P$^2$ is the first parameterization to achieve hyperparameter transfer of the joint optimum of learning rate and perturbation radius across model scales. Moreover, we provide an intuitive condition to derive $\mu$P$^2$ for other perturbation rules like Adaptive SAM and SAM-ON, also ensuring balanced perturbation effects across all layers.