 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangeAnywhere: Sample Generation for Remote Sensing Change Detection via Semantic Latent Diffusion Model
Apr 13, 2024Remote sensing change detection (CD) is a pivotal technique that pinpoints changes on a global scale based on multi-temporal images. With the recent expansion of deep learning, supervised deep learning-based CD models have shown satisfactory performance. However, CD sample labeling is very time-consuming as it is densely labeled and requires expert knowledge. To alleviate this problem, we introduce ChangeAnywhere, a novel CD sample generation method using the semantic latent diffusion model and single-temporal images. Specifically, ChangeAnywhere leverages the relative ease of acquiring large single-temporal semantic datasets to generate large-scale, diverse, and semantically annotated bi-temporal CD datasets. ChangeAnywhere captures the two essentials of CD samples, i.e., change implies semantically different, and non-change implies reasonable change under the same semantic constraints. We generated ChangeAnywhere-100K, the largest synthesis CD dataset with 100,000 pairs of CD samples based on the proposed method. The ChangeAnywhere-100K significantly improved both zero-shot and few-shot performance on two CD benchmark datasets for various deep learning-based CD models, as demonstrated by transfer experiments. This paper delineates the enormous potential of ChangeAnywhere for CD sample generation and demonstrates the subsequent enhancement of model performance. Therefore, ChangeAnywhere offers a potent tool for remote sensing CD. All codes and pre-trained models will be available at https://github.com/tangkai-RS/ChangeAnywhere.
High Noise Scheduling is a Must
Apr 09, 2024



Consistency models possess high capabilities for image generation, advancing sampling steps to a single step through their advanced techniques. Current advancements move one step forward consistency training techniques and eliminates the limitation of distillation training. Even though the proposed curriculum and noise scheduling in improved training techniques yield better results than basic consistency models, it lacks well balanced noise distribution and its consistency between curriculum. In this study, it is investigated the balance between high and low noise levels in noise distribution and offered polynomial noise distribution to maintain the stability. This proposed polynomial noise distribution is also supported with a predefined Karras noises to prevent unique noise levels arises with Karras noise generation algorithm. Furthermore, by elimination of learned noisy steps with a curriculum based on sinusoidal function increase the performance of the model in denoising. To make a fair comparison with the latest released consistency model training techniques, experiments are conducted with same hyper-parameters except curriculum and noise distribution. The models utilized during experiments are determined with low depth to prove the robustness of our proposed technique. The results show that the polynomial noise distribution outperforms the model trained with log-normal noise distribution, yielding a 33.54 FID score after 100,000 training steps with constant discretization steps. Additionally, the implementation of a sinusoidal-based curriculum enhances denoising performance, resulting in a FID score of 30.48.
Text2MDT: Extracting Medical Decision Trees from Medical Texts
Jan 04, 2024Knowledge of the medical decision process, which can be modeled as medical decision trees (MDTs), is critical to build clinical decision support systems. However, the current MDT construction methods rely heavily on time-consuming and laborious manual annotation. In this work, we propose a novel task, Text2MDT, to explore the automatic extraction of MDTs from medical texts such as medical guidelines and textbooks. We normalize the form of the MDT and create an annotated Text-to-MDT dataset in Chinese with the participation of medical experts. We investigate two different methods for the Text2MDT tasks: (a) an end-to-end framework which only relies on a GPT style large language models (LLM) instruction tuning to generate all the node information and tree structures. (b) The pipeline framework which decomposes the Text2MDT task to three subtasks. Experiments on our Text2MDT dataset demonstrate that: (a) the end-to-end method basd on LLMs (7B parameters or larger) show promising results, and successfully outperform the pipeline methods. (b) The chain-of-thought (COT) prompting method \cite{Wei2022ChainOT} can improve the performance of the fine-tuned LLMs on the Text2MDT test set. (c) the lightweight pipelined method based on encoder-based pretrained models can perform comparably with LLMs with model complexity two magnititudes smaller. Our Text2MDT dataset is open-sourced at \url{https://tianchi.aliyun.com/dataset/95414}, and the source codes are open-sourced at \url{https://github.com/michael-wzhu/text2dt}.
An Incremental Update Framework for Online Recommenders with Data-Driven Prior
Dec 26, 2023



Online recommenders have attained growing interest and created great revenue for businesses. Given numerous users and items, incremental update becomes a mainstream paradigm for learning large-scale models in industrial scenarios, where only newly arrived data within a sliding window is fed into the model, meeting the strict requirements of quick response. However, this strategy would be prone to overfitting to newly arrived data. When there exists a significant drift of data distribution, the long-term information would be discarded, which harms the recommendation performance. Conventional methods address this issue through native model-based continual learning methods, without analyzing the data characteristics for online recommenders. To address the aforementioned issue, we propose an incremental update framework for online recommenders with Data-Driven Prior (DDP), which is composed of Feature Prior (FP) and Model Prior (MP). The FP performs the click estimation for each specific value to enhance the stability of the training process. The MP incorporates previous model output into the current update while strictly following the Bayes rules, resulting in a theoretically provable prior for the robust update. In this way, both the FP and MP are well integrated into the unified framework, which is model-agnostic and can accommodate various advanced interaction models. Extensive experiments on two publicly available datasets as well as an industrial dataset demonstrate the superior performance of the proposed framework.
Latent Diffusion Model for Medical Image Standardization and Enhancement
Oct 08, 2023



Computed tomography (CT) serves as an effective tool for lung cancer screening, diagnosis, treatment, and prognosis, providing a rich source of features to quantify temporal and spatial tumor changes. Nonetheless, the diversity of CT scanners and customized acquisition protocols can introduce significant inconsistencies in texture features, even when assessing the same patient. This variability poses a fundamental challenge for subsequent research that relies on consistent image features. Existing CT image standardization models predominantly utilize GAN-based supervised or semi-supervised learning, but their performance remains limited. We present DiffusionCT, an innovative score-based DDPM model that operates in the latent space to transform disparate non-standard distributions into a standardized form. The architecture comprises a U-Net-based encoder-decoder, augmented by a DDPM model integrated at the bottleneck position. First, the encoder-decoder is trained independently, without embedding DDPM, to capture the latent representation of the input data. Second, the latent DDPM model is trained while keeping the encoder-decoder parameters fixed. Finally, the decoder uses the transformed latent representation to generate a standardized CT image, providing a more consistent basis for downstream analysis. Empirical tests on patient CT images indicate notable improvements in image standardization using DiffusionCT. Additionally, the model significantly reduces image noise in SPAD images, further validating the effectiveness of DiffusionCT for advanced imaging tasks.
When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities
Jul 31, 2023The advent of large language models marks a revolutionary breakthrough in artificial intelligence. With the unprecedented scale of training and model parameters, the capability of large language models has been dramatically improved, leading to human-like performances in understanding, language synthesizing, and common-sense reasoning, etc. Such a major leap-forward in general AI capacity will change the pattern of how personalization is conducted. For one thing, it will reform the way of interaction between humans and personalization systems. Instead of being a passive medium of information filtering, large language models present the foundation for active user engagement. On top of such a new foundation, user requests can be proactively explored, and user's required information can be delivered in a natural and explainable way. For another thing, it will also considerably expand the scope of personalization, making it grow from the sole function of collecting personalized information to the compound function of providing personalized services. By leveraging large language models as general-purpose interface, the personalization systems may compile user requests into plans, calls the functions of external tools to execute the plans, and integrate the tools' outputs to complete the end-to-end personalization tasks. Today, large language models are still being developed, whereas the application in personalization is largely unexplored. Therefore, we consider it to be the right time to review the challenges in personalization and the opportunities to address them with LLMs. In particular, we dedicate this perspective paper to the discussion of the following aspects: the development and challenges for the existing personalization system, the newly emerged capabilities of large language models, and the potential ways of making use of large language models for personalization.
Forward-Forward Contrastive Learning
May 04, 2023Medical image classification is one of the most important tasks for computer-aided diagnosis. Deep learning models, particularly convolutional neural networks, have been successfully used for disease classification from medical images, facilitated by automated feature learning. However, the diverse imaging modalities and clinical pathology make it challenging to construct generalized and robust classifications. Towards improving the model performance, we propose a novel pretraining approach, namely Forward Forward Contrastive Learning (FFCL), which leverages the Forward-Forward Algorithm in a contrastive learning framework--both locally and globally. Our experimental results on the chest X-ray dataset indicate that the proposed FFCL achieves superior performance (3.69% accuracy over ImageNet pretrained ResNet-18) over existing pretraining models in the pneumonia classification task. Moreover, extensive ablation experiments support the particular local and global contrastive pretraining design in FFCL.
Meta-causal Learning for Single Domain Generalization
Apr 07, 2023



Single domain generalization aims to learn a model from a single training domain (source domain) and apply it to multiple unseen test domains (target domains). Existing methods focus on expanding the distribution of the training domain to cover the target domains, but without estimating the domain shift between the source and target domains. In this paper, we propose a new learning paradigm, namely simulate-analyze-reduce, which first simulates the domain shift by building an auxiliary domain as the target domain, then learns to analyze the causes of domain shift, and finally learns to reduce the domain shift for model adaptation. Under this paradigm, we propose a meta-causal learning method to learn meta-knowledge, that is, how to infer the causes of domain shift between the auxiliary and source domains during training. We use the meta-knowledge to analyze the shift between the target and source domains during testing. Specifically, we perform multiple transformations on source data to generate the auxiliary domain, perform counterfactual inference to learn to discover the causal factors of the shift between the auxiliary and source domains, and incorporate the inferred causality into factor-aware domain alignments. Extensive experiments on several benchmarks of image classification show the effectiveness of our method.
DiffusionCT: Latent Diffusion Model for CT Image Standardization
Jan 20, 2023



Computed tomography (CT) imaging is a widely used modality for early lung cancer diagnosis, treatment, and prognosis. Features extracted from CT images are now accepted to quantify spatial and temporal variations in tumor architecture and function. However, CT images are often acquired using scanners from different vendors with customized acquisition standards, resulting in significantly different texture features even for the same patient, posing a fundamental challenge to downstream studies. Existing CT image harmonization models rely on supervised or semi-supervised techniques, with limited performance. In this paper, we have proposed a diffusion-based CT image standardization model called DiffusionCT which works on latent space by mapping latent distribution into a standard distribution. DiffusionCT incorporates an Unet-based encoder-decoder and a diffusion model embedded in its bottleneck part. The Unet first trained without the diffusion model to learn the latent representation of the input data. The diffusion model is trained in the next training phase. All the trained models work together on image standardization. The encoded representation outputted from the Unet encoder passes through the diffusion model, and the diffusion model maps the distribution in to target standard image domain. Finally, the decode takes that transformed latent representation to synthesize a standardized image. The experimental results show that DiffusionCT significantly improves the performance of the standardization task.
SoccerNet 2022 Challenges Results
Oct 05, 2022
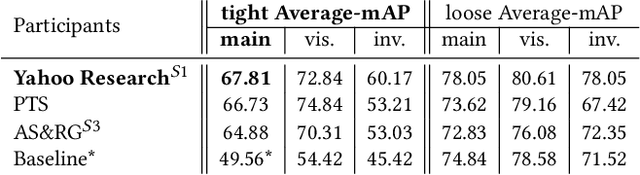
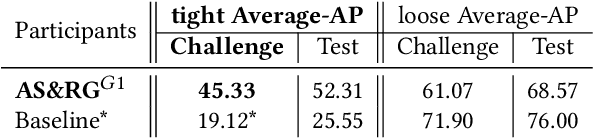
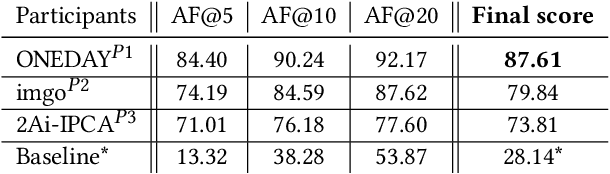
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.