 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-dimensional attention Transformer for state evaluation in real-time strategy games
Jan 07, 2025



Situation assessment in Real-Time Strategy (RTS) games is crucial for understanding decision-making in complex adversarial environments. However, existing methods remain limited in processing multi-dimensional feature information and temporal dependencies. Here we propose a tri-dimensional Space-Time-Feature Transformer (TSTF Transformer) architecture, which efficiently models battlefield situations through three independent but cascaded modules: spatial attention, temporal attention, and feature attention. On a dataset comprising 3,150 adversarial experiments, the 8-layer TSTF Transformer demonstrates superior performance: achieving 58.7% accuracy in the early game (~4% progress), significantly outperforming the conventional Timesformer's 41.8%; reaching 97.6% accuracy in the mid-game (~40% progress) while maintaining low performance variation (standard deviation 0.114). Meanwhile, this architecture requires fewer parameters (4.75M) compared to the baseline model (5.54M). Our study not only provides new insights into situation assessment in RTS games but also presents an innovative paradigm for Transformer-based multi-dimensional temporal modeling.
Improved Feature Extraction Network for Neuro-Oriented Target Speaker Extraction
Jan 03, 2025



The recent rapid development of auditory attention decoding (AAD) offers the possibility of using electroencephalography (EEG) as auxiliary information for target speaker extraction. However, effectively modeling long sequences of speech and resolving the identity of the target speaker from EEG signals remains a major challenge. In this paper, an improved feature extraction network (IFENet) is proposed for neuro-oriented target speaker extraction, which mainly consists of a speech encoder with dual-path Mamba and an EEG encoder with Kolmogorov-Arnold Networks (KAN). We propose SpeechBiMamba, which makes use of dual-path Mamba in modeling local and global speech sequences to extract speech features. In addition, we propose EEGKAN to effectively extract EEG features that are closely related to the auditory stimuli and locate the target speaker through the subject's attention information. Experiments on the KUL and AVED datasets show that IFENet outperforms the state-of-the-art model, achieving 36\% and 29\% relative improvements in terms of scale-invariant signal-to-distortion ratio (SI-SDR) under an open evaluation condition.
M$^3$oralBench: A MultiModal Moral Benchmark for LVLMs
Dec 30, 2024Recently, large foundation models, including large language models (LLMs) and large vision-language models (LVLMs), have become essential tools in critical fields such as law, finance, and healthcare. As these models increasingly integrate into our daily life, it is necessary to conduct moral evaluation to ensure that their outputs align with human values and remain within moral boundaries. Previous works primarily focus on LLMs, proposing moral datasets and benchmarks limited to text modality. However, given the rapid development of LVLMs, there is still a lack of multimodal moral evaluation methods. To bridge this gap, we introduce M$^3$oralBench, the first MultiModal Moral Benchmark for LVLMs. M$^3$oralBench expands the everyday moral scenarios in Moral Foundations Vignettes (MFVs) and employs the text-to-image diffusion model, SD3.0, to create corresponding scenario images. It conducts moral evaluation across six moral foundations of Moral Foundations Theory (MFT) and encompasses tasks in moral judgement, moral classification, and moral response, providing a comprehensive assessment of model performance in multimodal moral understanding and reasoning. Extensive experiments on 10 popular open-source and closed-source LVLMs demonstrate that M$^3$oralBench is a challenging benchmark, exposing notable moral limitations in current models. Our benchmark is publicly available.
EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers
Dec 29, 2024Removing unwanted concepts from large-scale text-to-image (T2I) diffusion models while maintaining their overall generative quality remains an open challenge. This difficulty is especially pronounced in emerging paradigms, such as Stable Diffusion (SD) v3 and Flux, which incorporate flow matching and transformer-based architectures. These advancements limit the transferability of existing concept-erasure techniques that were originally designed for the previous T2I paradigm (\textit{e.g.}, SD v1.4). In this work, we introduce \logopic \textbf{EraseAnything}, the first method specifically developed to address concept erasure within the latest flow-based T2I framework. We formulate concept erasure as a bi-level optimization problem, employing LoRA-based parameter tuning and an attention map regularizer to selectively suppress undesirable activations. Furthermore, we propose a self-contrastive learning strategy to ensure that removing unwanted concepts does not inadvertently harm performance on unrelated ones. Experimental results demonstrate that EraseAnything successfully fills the research gap left by earlier methods in this new T2I paradigm, achieving state-of-the-art performance across a wide range of concept erasure tasks.
Multi-P$^2$A: A Multi-perspective Benchmark on Privacy Assessment for Large Vision-Language Models
Dec 27, 2024Large Vision-Language Models (LVLMs) exhibit impressive potential across various tasks but also face significant privacy risks, limiting their practical applications. Current researches on privacy assessment for LVLMs is limited in scope, with gaps in both assessment dimensions and privacy categories. To bridge this gap, we propose Multi-P$^2$A, a comprehensive benchmark for evaluating the privacy preservation capabilities of LVLMs in terms of privacy awareness and leakage. Privacy awareness measures the model's ability to recognize the privacy sensitivity of input data, while privacy leakage assesses the risk of the model unintentionally disclosing privacy information in its output. We design a range of sub-tasks to thoroughly evaluate the model's privacy protection offered by LVLMs. Multi-P$^2$A covers 26 categories of personal privacy, 15 categories of trade secrets, and 18 categories of state secrets, totaling 31,962 samples. Based on Multi-P$^2$A, we evaluate the privacy preservation capabilities of 21 open-source and 2 closed-source LVLMs. Our results reveal that current LVLMs generally pose a high risk of facilitating privacy breaches, with vulnerabilities varying across personal privacy, trade secret, and state secret.
Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
Dec 22, 2024


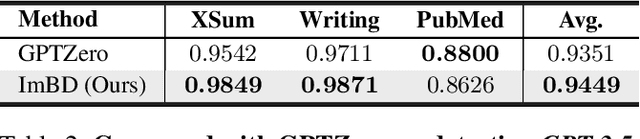
Large Language Models (LLMs) have revolutionized text generation, making detecting machine-generated text increasingly challenging. Although past methods have achieved good performance on detecting pure machine-generated text, those detectors have poor performance on distinguishing machine-revised text (rewriting, expansion, and polishing), which can have only minor changes from its original human prompt. As the content of text may originate from human prompts, detecting machine-revised text often involves identifying distinctive machine styles, e.g., worded favored by LLMs. However, existing methods struggle to detect machine-style phrasing hidden within the content contributed by humans. We propose the "Imitate Before Detect" (ImBD) approach, which first imitates the machine-style token distribution, and then compares the distribution of the text to be tested with the machine-style distribution to determine whether the text has been machine-revised. To this end, we introduce style preference optimization (SPO), which aligns a scoring LLM model to the preference of text styles generated by machines. The aligned scoring model is then used to calculate the style-conditional probability curvature (Style-CPC), quantifying the log probability difference between the original and conditionally sampled texts for effective detection. We conduct extensive comparisons across various scenarios, encompassing text revisions by six LLMs, four distinct text domains, and three machine revision types. Compared to existing state-of-the-art methods, our method yields a 13% increase in AUC for detecting text revised by open-source LLMs, and improves performance by 5% and 19% for detecting GPT-3.5 and GPT-4o revised text, respectively. Notably, our method surpasses the commercially trained GPT-Zero with just $1,000$ samples and five minutes of SPO, demonstrating its efficiency and effectiveness.
VSFormer: Value and Shape-Aware Transformer with Prior-Enhanced Self-Attention for Multivariate Time Series Classification
Dec 21, 2024Multivariate time series classification is a crucial task in data mining, attracting growing research interest due to its broad applications. While many existing methods focus on discovering discriminative patterns in time series, real-world data does not always present such patterns, and sometimes raw numerical values can also serve as discriminative features. Additionally, the recent success of Transformer models has inspired many studies. However, when applying to time series classification, the self-attention mechanisms in Transformer models could introduce classification-irrelevant features, thereby compromising accuracy. To address these challenges, we propose a novel method, VSFormer, that incorporates both discriminative patterns (shape) and numerical information (value). In addition, we extract class-specific prior information derived from supervised information to enrich the positional encoding and provide classification-oriented self-attention learning, thereby enhancing its effectiveness. Extensive experiments on all 30 UEA archived datasets demonstrate the superior performance of our method compared to SOTA models. Through ablation studies, we demonstrate the effectiveness of the improved encoding layer and the proposed self-attention mechanism. Finally, We provide a case study on a real-world time series dataset without discriminative patterns to interpret our model.
Multi-Granularity Open Intent Classification via Adaptive Granular-Ball Decision Boundary
Dec 18, 2024



Open intent classification is critical for the development of dialogue systems, aiming to accurately classify known intents into their corresponding classes while identifying unknown intents. Prior boundary-based methods assumed known intents fit within compact spherical regions, focusing on coarse-grained representation and precise spherical decision boundaries. However, these assumptions are often violated in practical scenarios, making it difficult to distinguish known intent classes from unknowns using a single spherical boundary. To tackle these issues, we propose a Multi-granularity Open intent classification method via adaptive Granular-Ball decision boundary (MOGB). Our MOGB method consists of two modules: representation learning and decision boundary acquiring. To effectively represent the intent distribution, we design a hierarchical representation learning method. This involves iteratively alternating between adaptive granular-ball clustering and nearest sub-centroid classification to capture fine-grained semantic structures within known intent classes. Furthermore, multi-granularity decision boundaries are constructed for open intent classification by employing granular-balls with varying centroids and radii. Extensive experiments conducted on three public datasets demonstrate the effectiveness of our proposed method.
* This paper has been Accepted on AAAI2025
RepFace: Refining Closed-Set Noise with Progressive Label Correction for Face Recognition
Dec 16, 2024Face recognition has made remarkable strides, driven by the expanding scale of datasets, advancements in various backbone and discriminative losses. However, face recognition performance is heavily affected by the label noise, especially closed-set noise. While numerous studies have focused on handling label noise, addressing closed-set noise still poses challenges. This paper identifies this challenge as training isn't robust to noise at the early-stage training, and necessitating an appropriate learning strategy for samples with low confidence, which are often misclassified as closed-set noise in later training phases. To address these issues, we propose a new framework to stabilize the training at early stages and split the samples into clean, ambiguous and noisy groups which are devised with separate training strategies. Initially, we employ generated auxiliary closed-set noisy samples to enable the model to identify noisy data at the early stages of training. Subsequently, we introduce how samples are split into clean, ambiguous and noisy groups by their similarity to the positive and nearest negative centers. Then we perform label fusion for ambiguous samples by incorporating accumulated model predictions. Finally, we apply label smoothing within the closed set, adjusting the label to a point between the nearest negative class and the initially assigned label. Extensive experiments validate the effectiveness of our method on mainstream face datasets, achieving state-of-the-art results. The code will be released upon acceptance.
SuperMark: Robust and Training-free Image Watermarking via Diffusion-based Super-Resolution
Dec 13, 2024



In today's digital landscape, the blending of AI-generated and authentic content has underscored the need for copyright protection and content authentication. Watermarking has become a vital tool to address these challenges, safeguarding both generated and real content. Effective watermarking methods must withstand various distortions and attacks. Current deep watermarking techniques often use an encoder-noise layer-decoder architecture and include distortions to enhance robustness. However, they struggle to balance robustness and fidelity and remain vulnerable to adaptive attacks, despite extensive training. To overcome these limitations, we propose SuperMark, a robust, training-free watermarking framework. Inspired by the parallels between watermark embedding/extraction in watermarking and the denoising/noising processes in diffusion models, SuperMark embeds the watermark into initial Gaussian noise using existing techniques. It then applies pre-trained Super-Resolution (SR) models to denoise the watermarked noise, producing the final watermarked image. For extraction, the process is reversed: the watermarked image is inverted back to the initial watermarked noise via DDIM Inversion, from which the embedded watermark is extracted. This flexible framework supports various noise injection methods and diffusion-based SR models, enabling enhanced customization. The robustness of the DDIM Inversion process against perturbations allows SuperMark to achieve strong resilience to distortions while maintaining high fidelity. Experiments demonstrate that SuperMark achieves fidelity comparable to existing methods while significantly improving robustness. Under standard distortions, it achieves an average watermark extraction accuracy of 99.46%, and 89.29% under adaptive attacks. Moreover, SuperMark shows strong transferability across datasets, SR models, embedding methods, and resolutions.