 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation-oriented Knowledge Distillation for Deep Face Recognition
Jun 06, 2022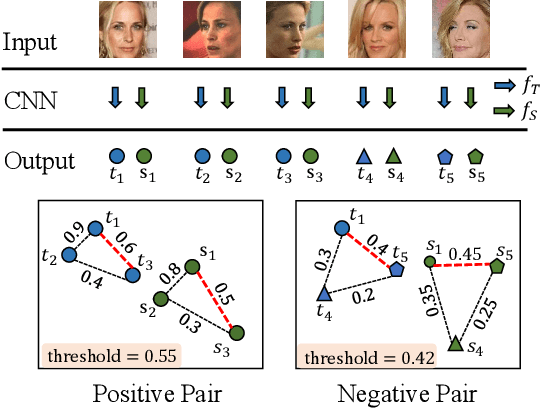
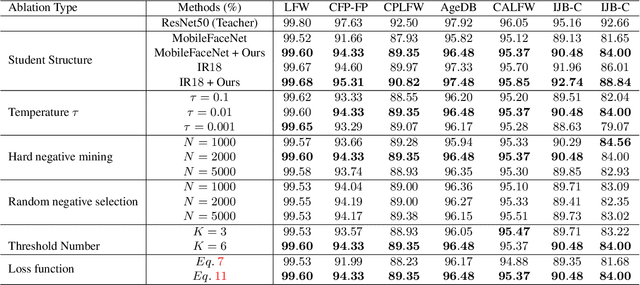
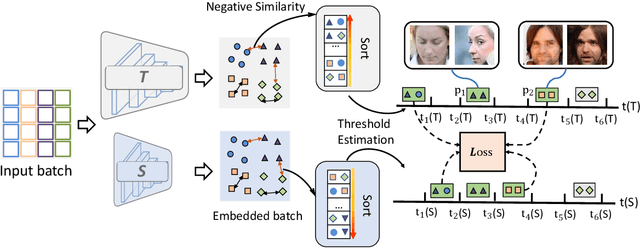
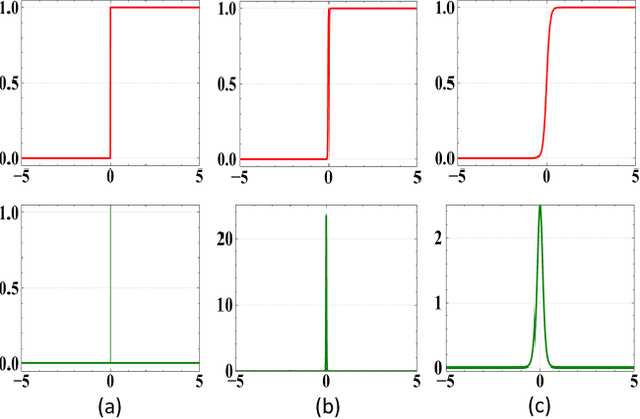
Knowledge distillation (KD) is a widely-used technique that utilizes large networks to improve the performance of compact models. Previous KD approaches usually aim to guide the student to mimic the teacher's behavior completely in the representation space. However, such one-to-one corresponding constraints may lead to inflexible knowledge transfer from the teacher to the student, especially those with low model capacities. Inspired by the ultimate goal of KD methods, we propose a novel Evaluation oriented KD method (EKD) for deep face recognition to directly reduce the performance gap between the teacher and student models during training. Specifically, we adopt the commonly used evaluation metrics in face recognition, i.e., False Positive Rate (FPR) and True Positive Rate (TPR) as the performance indicator. According to the evaluation protocol, the critical pair relations that cause the TPR and FPR difference between the teacher and student models are selected. Then, the critical relations in the student are constrained to approximate the corresponding ones in the teacher by a novel rank-based loss function, giving more flexibility to the student with low capacity. Extensive experimental results on popular benchmarks demonstrate the superiority of our EKD over state-of-the-art competitors.
Multi-scale Attention Flow for Probabilistic Time Series Forecasting
May 16, 2022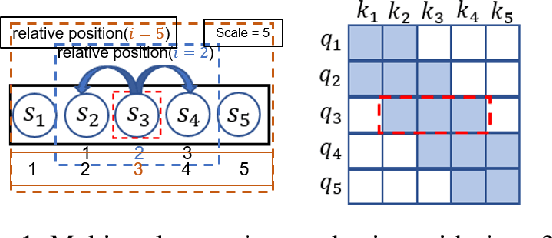
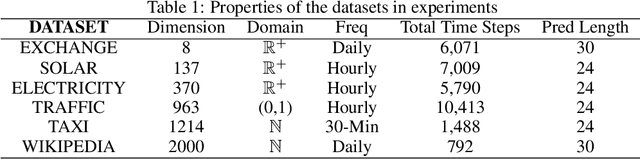
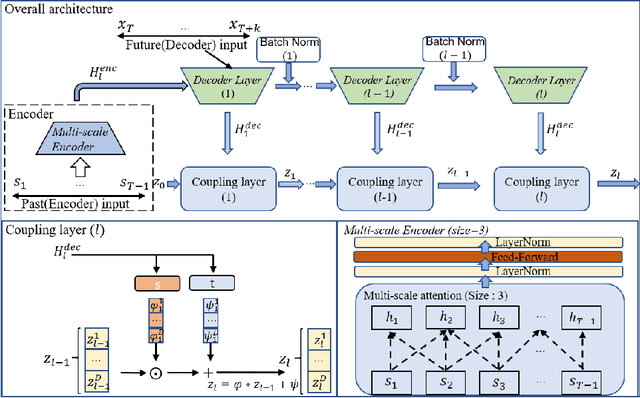
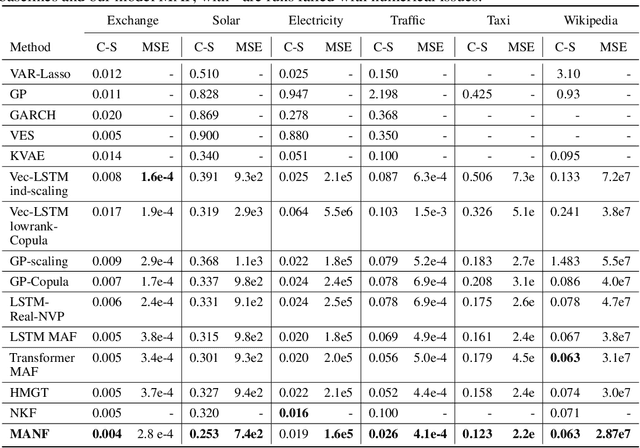
The probability prediction of multivariate time series is a notoriously challenging but practical task. On the one hand, the challenge is how to effectively capture the cross-series correlations between interacting time series, to achieve accurate distribution modeling. On the other hand, we should consider how to capture the contextual information within time series more accurately to model multivariate temporal dynamics of time series. In this work, we proposed a novel non-autoregressive deep learning model, called Multi-scale Attention Normalizing Flow(MANF), where we integrate multi-scale attention and relative position information and the multivariate data distribution is represented by the conditioned normalizing flow. Additionally, compared with autoregressive modeling methods, our model avoids the influence of cumulative error and does not increase the time complexity. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets.
Efficient Test-Time Model Adaptation without Forgetting
Apr 06, 2022
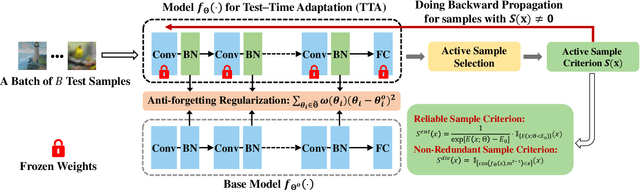
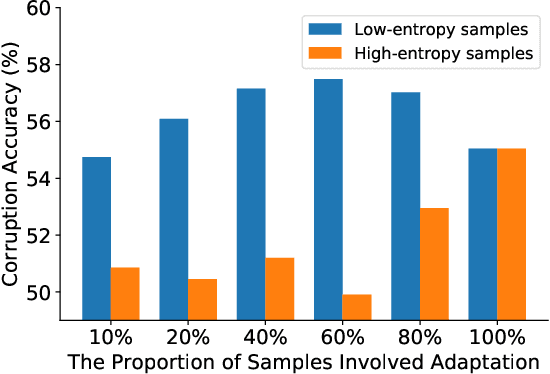
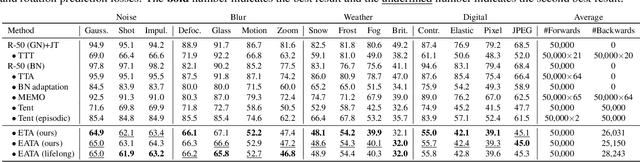
Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and testing data by adapting a given model w.r.t. any testing sample. This task is particularly important for deep models when the test environment changes frequently. Although some recent attempts have been made to handle this task, we still face two practical challenges: 1) existing methods have to perform backward computation for each test sample, resulting in unbearable prediction cost to many applications; 2) while existing TTA solutions can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as catastrophic forgetting). In this paper, we point out that not all the test samples contribute equally to model adaptation, and high-entropy ones may lead to noisy gradients that could disrupt the model. Motivated by this, we propose an active sample selection criterion to identify reliable and non-redundant samples, on which the model is updated to minimize the entropy loss for test-time adaptation. Furthermore, to alleviate the forgetting issue, we introduce a Fisher regularizer to constrain important model parameters from drastic changes, where the Fisher importance is estimated from test samples with generated pseudo labels. Extensive experiments on CIFAR-10-C, ImageNet-C, and ImageNet-R verify the effectiveness of our proposed method.
Boost Test-Time Performance with Closed-Loop Inference
Mar 26, 2022
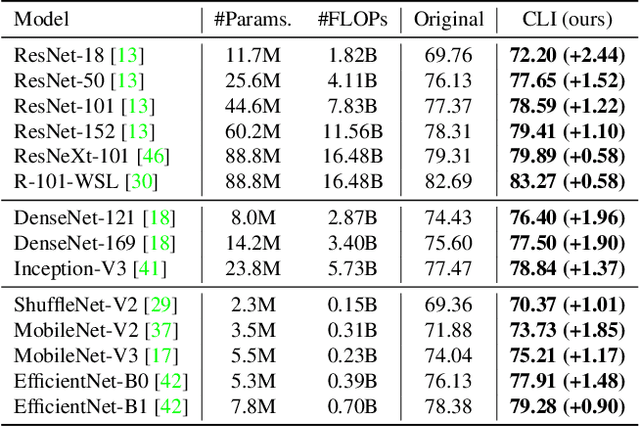
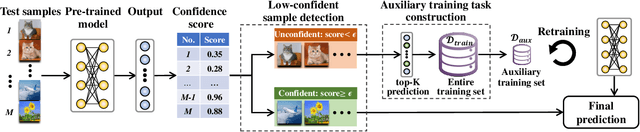
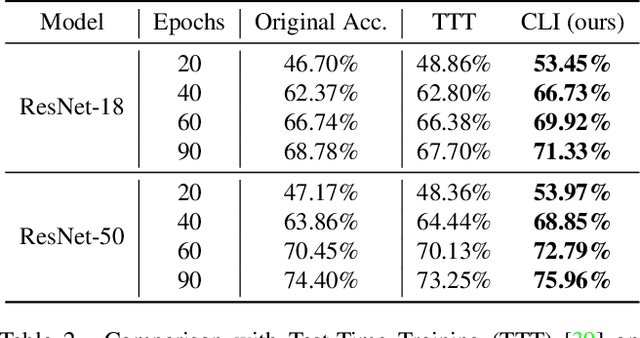
Conventional deep models predict a test sample with a single forward propagation, which, however, may not be sufficient for predicting hard-classified samples. On the contrary, we human beings may need to carefully check the sample many times before making a final decision. During the recheck process, one may refine/adjust the prediction by referring to related samples. Motivated by this, we propose to predict those hard-classified test samples in a looped manner to boost the model performance. However, this idea may pose a critical challenge: how to construct looped inference, so that the original erroneous predictions on these hard test samples can be corrected with little additional effort. To address this, we propose a general Closed-Loop Inference (CLI) method. Specifically, we first devise a filtering criterion to identify those hard-classified test samples that need additional inference loops. For each hard sample, we construct an additional auxiliary learning task based on its original top-$K$ predictions to calibrate the model, and then use the calibrated model to obtain the final prediction. Promising results on ImageNet (in-distribution test samples) and ImageNet-C (out-of-distribution test samples) demonstrate the effectiveness of CLI in improving the performance of any pre-trained model.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022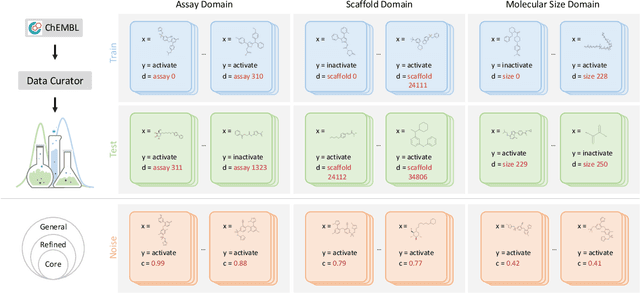

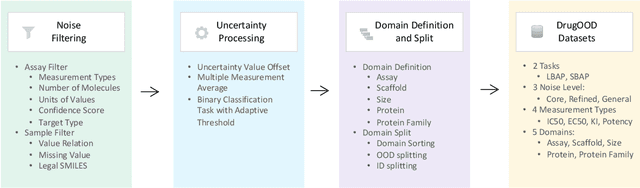
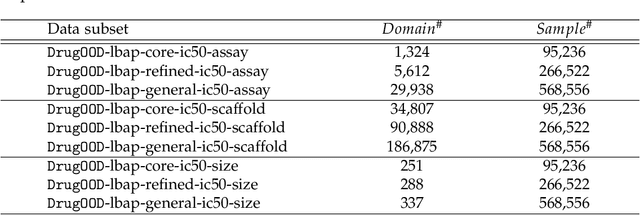
AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
AdaXpert: Adapting Neural Architecture for Growing Data
Jul 01, 2021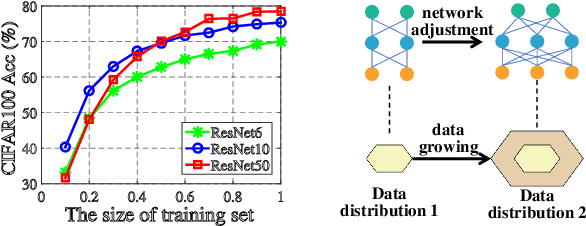
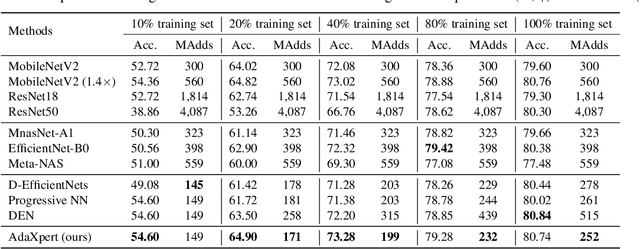
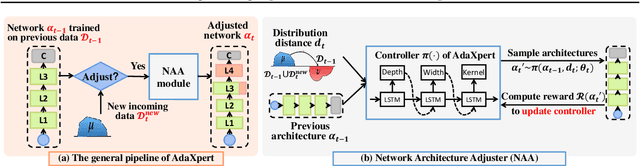
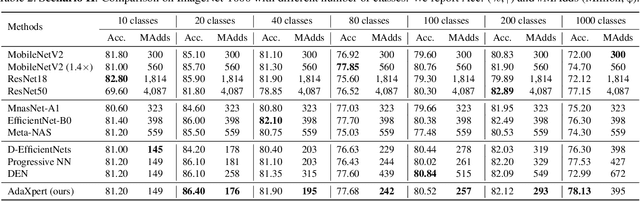
In real-world applications, data often come in a growing manner, where the data volume and the number of classes may increase dynamically. This will bring a critical challenge for learning: given the increasing data volume or the number of classes, one has to instantaneously adjust the neural model capacity to obtain promising performance. Existing methods either ignore the growing nature of data or seek to independently search an optimal architecture for a given dataset, and thus are incapable of promptly adjusting the architectures for the changed data. To address this, we present a neural architecture adaptation method, namely Adaptation eXpert (AdaXpert), to efficiently adjust previous architectures on the growing data. Specifically, we introduce an architecture adjuster to generate a suitable architecture for each data snapshot, based on the previous architecture and the different extent between current and previous data distributions. Furthermore, we propose an adaptation condition to determine the necessity of adjustment, thereby avoiding unnecessary and time-consuming adjustments. Extensive experiments on two growth scenarios (increasing data volume and number of classes) demonstrate the effectiveness of the proposed method.
Energy-Based Learning for Cooperative Games, with Applications to Feature/Data/Model Valuations
Jun 05, 2021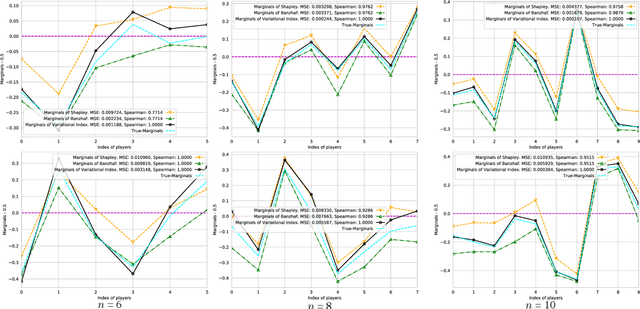
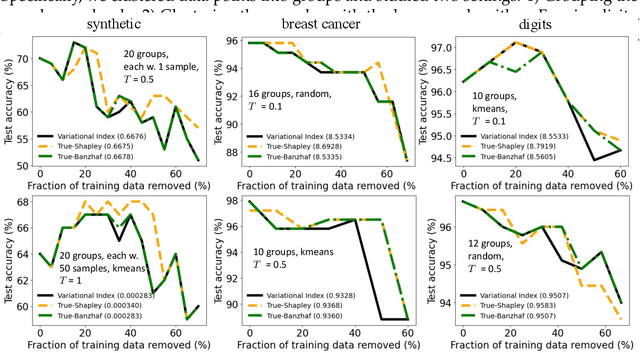
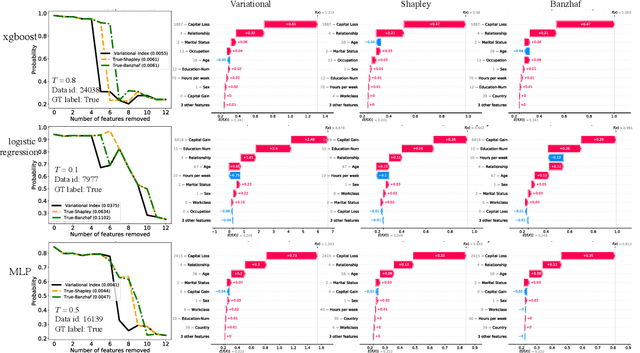
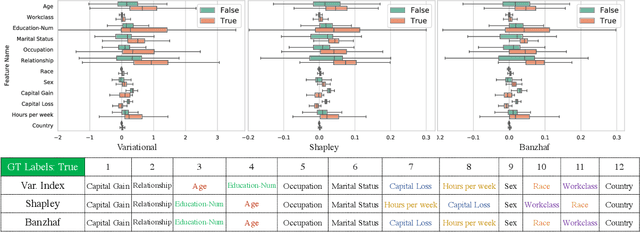
Valuation problems, such as attribution-based feature interpretation, data valuation and model valuation for ensembles, become increasingly more important in many machine learning applications. Such problems are commonly solved by well-known game-theoretic criteria, such as Shapley value or Banzhaf index. In this work, we present a novel energy-based treatment for cooperative games, with a theoretical justification by the maximum entropy framework. Surprisingly, by conducting variational inference of the energy-based model, we recover various game-theoretic valuation criteria, such as Shapley value and Banzhaf index, through conducting one-step gradient ascent for maximizing the mean-field ELBO objective. This observation also verifies the rationality of existing criteria, as they are all trying to decouple the correlations among the players through the mean-field approach. By running gradient ascent for multiple steps, we achieve a trajectory of the valuations, among which we define the valuation with the best conceivable decoupling error as the Variational Index. We experimentally demonstrate that the proposed Variational Index enjoys intriguing properties on certain synthetic and real-world valuation problems.
EBM-Fold: Fully-Differentiable Protein Folding Powered by Energy-based Models
May 31, 2021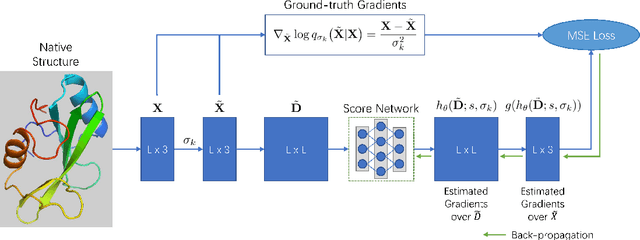

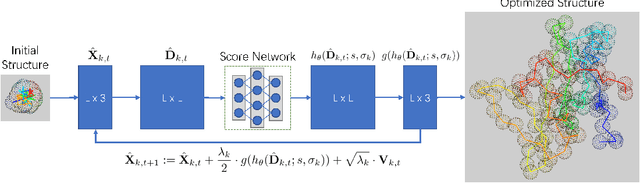
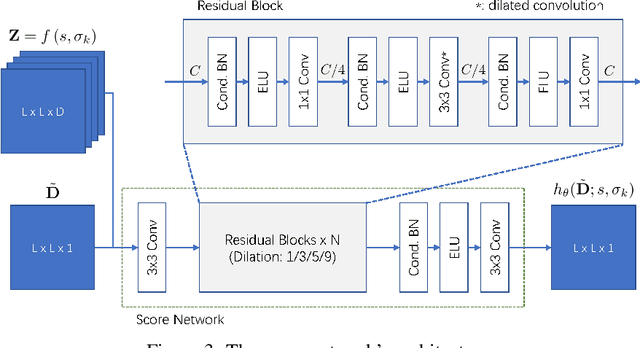
Accurate protein structure prediction from amino-acid sequences is critical to better understanding the protein function. Recent advances in this area largely benefit from more precise inter-residue distance and orientation predictions, powered by deep neural networks. However, the structure optimization procedure is still dominated by traditional tools, e.g. Rosetta, where the structure is solved via minimizing a pre-defined statistical energy function (with optional prediction-based restraints). Such energy function may not be optimal in formulating the whole conformation space of proteins. In this paper, we propose a fully-differentiable approach for protein structure optimization, guided by a data-driven generative network. This network is trained in a denoising manner, attempting to predict the correction signal from corrupted distance matrices between Ca atoms. Once the network is well trained, Langevin dynamics based sampling is adopted to gradually optimize structures from random initialization. Extensive experiments demonstrate that our EBM-Fold approach can efficiently produce high-quality decoys, compared against traditional Rosetta-based structure optimization routines.
tFold-TR: Combining Deep Learning Enhanced Hybrid Potential Energy for Template-Based Modeling Structure Refinement
May 30, 2021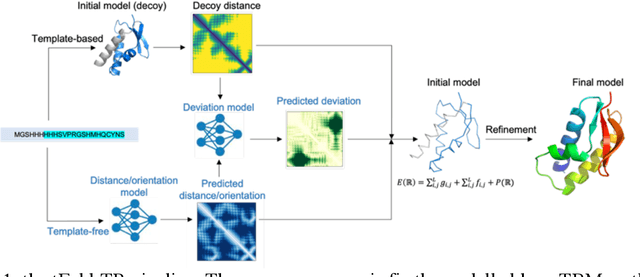


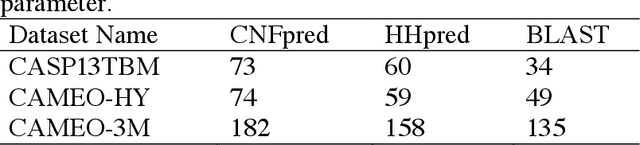
Protein structure prediction has been a grand challenge for over 50 years, owing to its broad scientific and application interests. There are two primary types of modeling algorithms, template-free modeling and template-based modeling. The latter one is suitable for easy prediction tasks and is widely adopted in computer-aided drug discoveries for drug design and screening. Although it has been several decades since its first edition, the current template-based modeling approach suffers from two critical problems: 1) there are many missing regions in the template-query sequence alignment, and 2) the accuracy of the distance pairs from different regions of the template varies, and this information is not well introduced into the modeling. To solve these two problems, we propose a structural optimization process based on template modeling, introducing two neural network models to predict the distance information of the missing regions and the accuracy of the distance pairs of different regions in the template modeling structure. The predicted distances and residue pairwise-specific deviations are incorporated into the potential energy function for structural optimization, which significantly improves the qualities of the original template modeling decoys.
Federated Face Recognition
May 06, 2021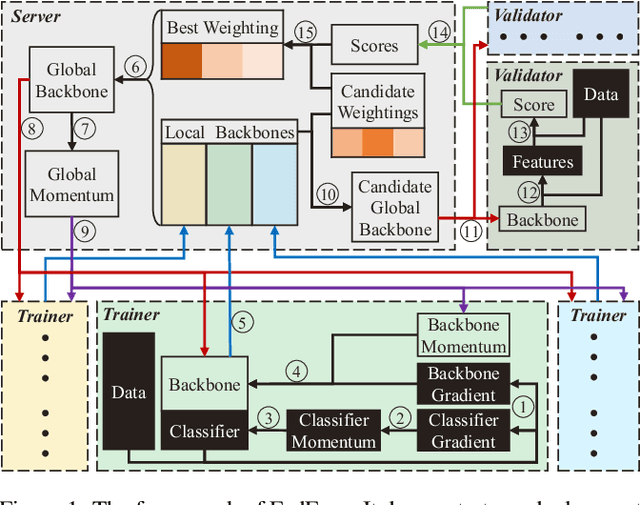
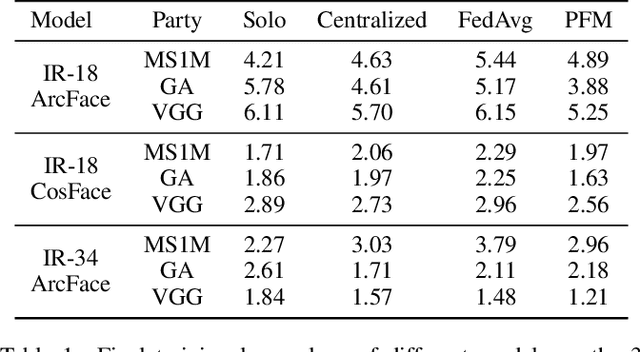
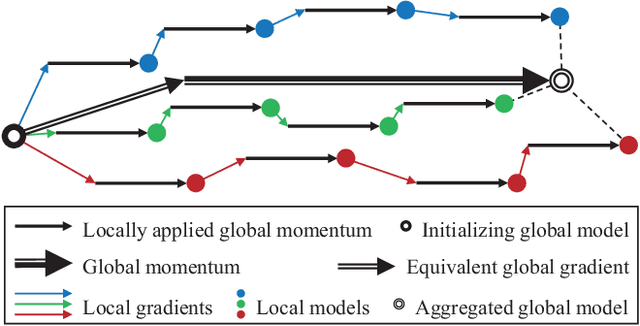
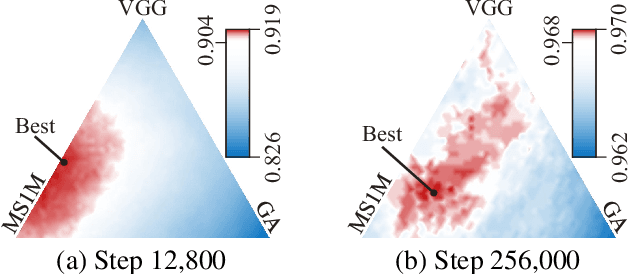
Face recognition has been extensively studied in computer vision and artificial intelligence communities in recent years. An important issue of face recognition is data privacy, which receives more and more public concerns. As a common privacy-preserving technique, Federated Learning is proposed to train a model cooperatively without sharing data between parties. However, as far as we know, it has not been successfully applied in face recognition. This paper proposes a framework named FedFace to innovate federated learning for face recognition. Specifically, FedFace relies on two major innovative algorithms, Partially Federated Momentum (PFM) and Federated Validation (FV). PFM locally applies an estimated equivalent global momentum to approximating the centralized momentum-SGD efficiently. FV repeatedly searches for better federated aggregating weightings via testing the aggregated models on some private validation datasets, which can improve the model's generalization ability. The ablation study and extensive experiments validate the effectiveness of the FedFace method and show that it is comparable to or even better than the centralized baseline in performance.