 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMES: Towards Scalable Multi-Task Recommendation via Expert Sparsity
Feb 10, 2026Industrial recommender systems typically rely on multi-task learning to estimate diverse user feedback signals and aggregate them for ranking. Recent advances in model scaling have shown promising gains in recommendation. However, naively increasing model capacity imposes prohibitive online inference costs and often yields diminishing returns for sparse tasks with skewed label distributions. This mismatch between uniform parameter scaling and heterogeneous task capacity demands poses a fundamental challenge for scalable multi-task recommendation. In this work, we investigate parameter sparsification as a principled scaling paradigm and identify two critical obstacles when applying sparse Mixture-of-Experts (MoE) to multi-task recommendation: exploded expert activation that undermines instance-level sparsity and expert load skew caused by independent task-wise routing. To address these challenges, we propose SMES, a scalable sparse MoE framework with progressive expert routing. SMES decomposes expert activation into a task-shared expert subset jointly selected across tasks and task-adaptive private experts, explicitly bounding per-instance expert execution while preserving task-specific capacity. In addition, SMES introduces a global multi-gate load-balancing regularizer that stabilizes training by regulating aggregated expert utilization across all tasks. SMES has been deployed in Kuaishou large-scale short-video services, supporting over 400 million daily active users. Extensive online experiments demonstrate stable improvements, with GAUC gain of 0.29% and a 0.31% uplift in user watch time.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025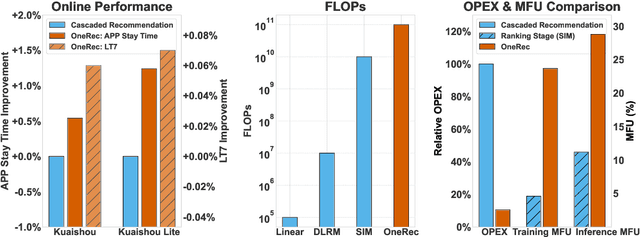

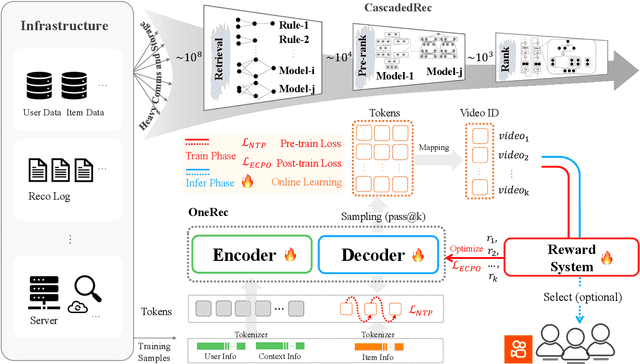
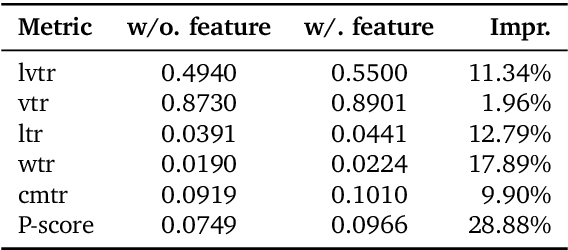
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Temporal Convolution Domain Adaptation Learning for Crops Growth Prediction
Feb 24, 2022

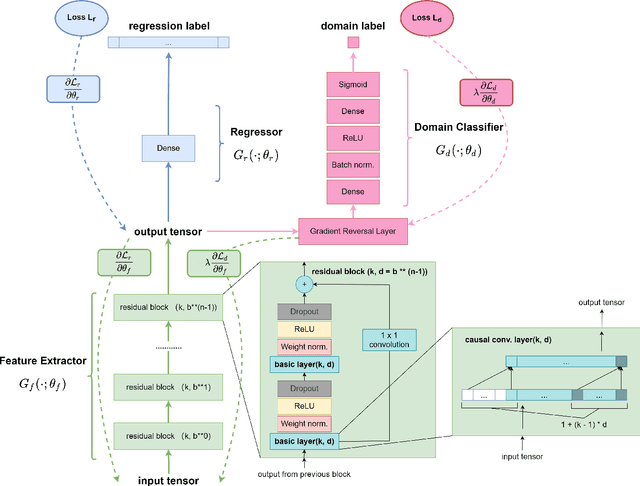
Existing Deep Neural Nets on crops growth prediction mostly rely on availability of a large amount of data. In practice, it is difficult to collect enough high-quality data to utilize the full potential of these deep learning models. In this paper, we construct an innovative network architecture based on domain adaptation learning to predict crops growth curves with limited available crop data. This network architecture overcomes the challenge of data availability by incorporating generated data from the developed crops simulation model. We are the first to use the temporal convolution filters as the backbone to construct a domain adaptation network architecture which is suitable for deep learning regression models with very limited training data of the target domain. We conduct experiments to test the performance of the network and compare our proposed architecture with other state-of-the-art methods, including a recent LSTM-based domain adaptation network architecture. The results show that the proposed temporal convolution-based network architecture outperforms all benchmarks not only in accuracy but also in model size and convergence rate.