 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning with Demonstrations from Mismatched Task under Sparse Reward
Dec 03, 2022



Reinforcement learning often suffer from the sparse reward issue in real-world robotics problems. Learning from demonstration (LfD) is an effective way to eliminate this problem, which leverages collected expert data to aid online learning. Prior works often assume that the learning agent and the expert aim to accomplish the same task, which requires collecting new data for every new task. In this paper, we consider the case where the target task is mismatched from but similar with that of the expert. Such setting can be challenging and we found existing LfD methods can not effectively guide learning in mismatched new tasks with sparse rewards. We propose conservative reward shaping from demonstration (CRSfD), which shapes the sparse rewards using estimated expert value function. To accelerate learning processes, CRSfD guides the agent to conservatively explore around demonstrations. Experimental results of robot manipulation tasks show that our approach outperforms baseline LfD methods when transferring demonstrations collected in a single task to other different but similar tasks.
Safe Model-Based Reinforcement Learning with an Uncertainty-Aware Reachability Certificate
Oct 14, 2022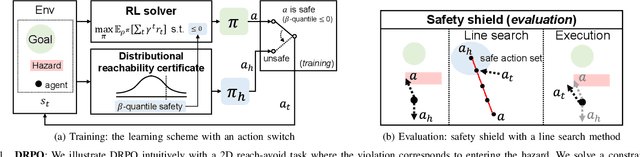
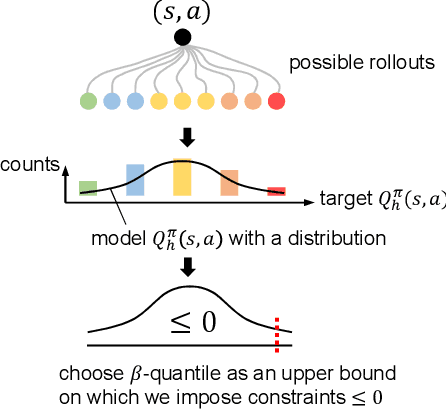
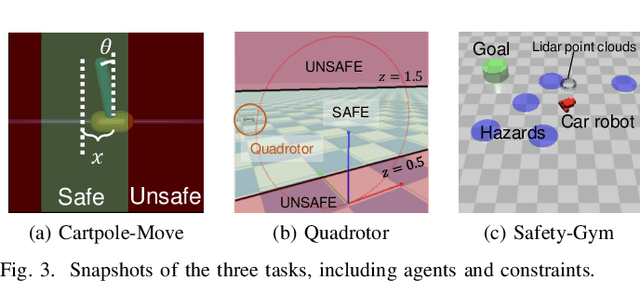
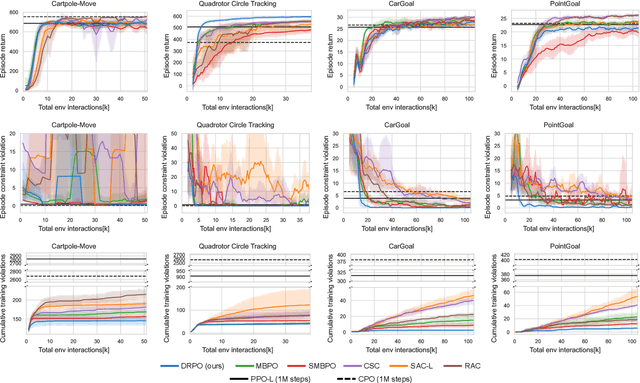
Safe reinforcement learning (RL) that solves constraint-satisfactory policies provides a promising way to the broader safety-critical applications of RL in real-world problems such as robotics. Among all safe RL approaches, model-based methods reduce training time violations further due to their high sample efficiency. However, lacking safety robustness against the model uncertainties remains an issue in safe model-based RL, especially in training time safety. In this paper, we propose a distributional reachability certificate (DRC) and its Bellman equation to address model uncertainties and characterize robust persistently safe states. Furthermore, we build a safe RL framework to resolve constraints required by the DRC and its corresponding shield policy. We also devise a line search method to maintain safety and reach higher returns simultaneously while leveraging the shield policy. Comprehensive experiments on classical benchmarks such as constrained tracking and navigation indicate that the proposed algorithm achieves comparable returns with much fewer constraint violations during training.
Decomposed Mutual Information Optimization for Generalized Context in Meta-Reinforcement Learning
Oct 09, 2022
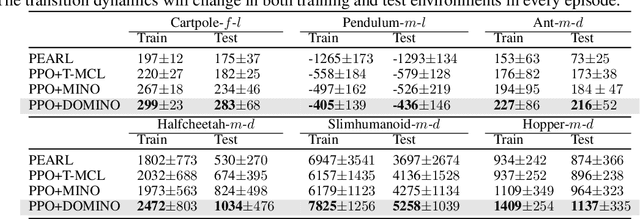
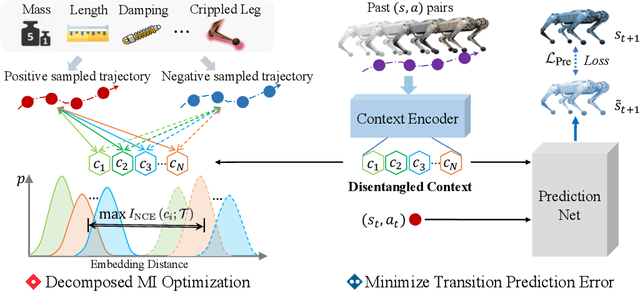
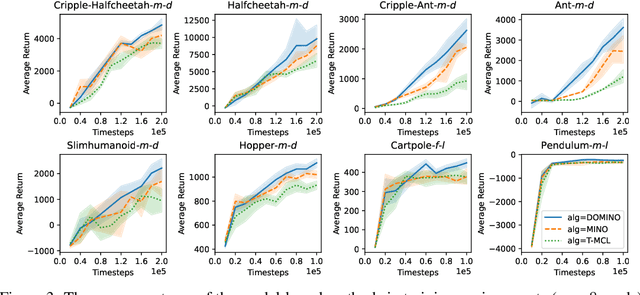
Adapting to the changes in transition dynamics is essential in robotic applications. By learning a conditional policy with a compact context, context-aware meta-reinforcement learning provides a flexible way to adjust behavior according to dynamics changes. However, in real-world applications, the agent may encounter complex dynamics changes. Multiple confounders can influence the transition dynamics, making it challenging to infer accurate context for decision-making. This paper addresses such a challenge by Decomposed Mutual INformation Optimization (DOMINO) for context learning, which explicitly learns a disentangled context to maximize the mutual information between the context and historical trajectories, while minimizing the state transition prediction error. Our theoretical analysis shows that DOMINO can overcome the underestimation of the mutual information caused by multi-confounded challenges via learning disentangled context and reduce the demand for the number of samples collected in various environments. Extensive experiments show that the context learned by DOMINO benefits both model-based and model-free reinforcement learning algorithms for dynamics generalization in terms of sample efficiency and performance in unseen environments.
Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
Oct 08, 2022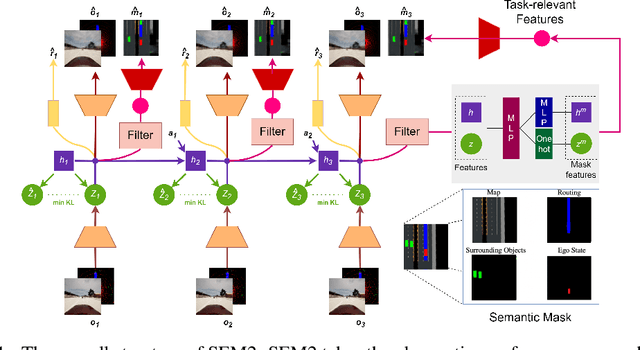

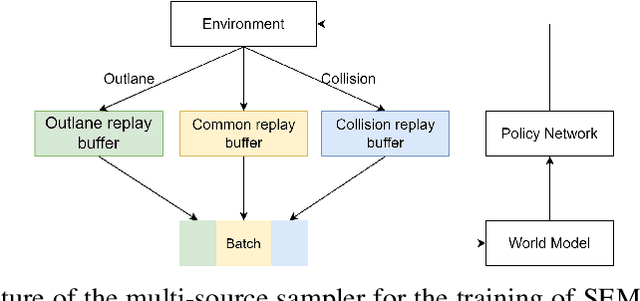
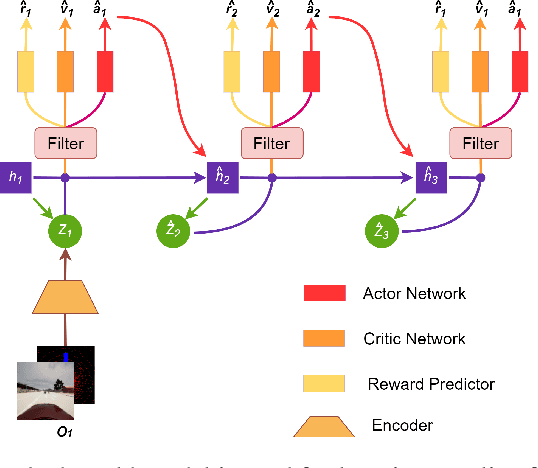
End-to-end autonomous driving provides a feasible way to automatically maximize overall driving system performance by directly mapping the raw pixels from a front-facing camera to control signals. Recent advanced methods construct a latent world model to map the high dimensional observations into compact latent space. However, the latent states embedded by the world model proposed in previous works may contain a large amount of task-irrelevant information, resulting in low sampling efficiency and poor robustness to input perturbations. Meanwhile, the training data distribution is usually unbalanced, and the learned policy is hard to cope with the corner cases during the driving process. To solve the above challenges, we present a semantic masked recurrent world model (SEM2), which introduces a latent filter to extract key task-relevant features and reconstruct a semantic mask via the filtered features, and is trained with a multi-source data sampler, which aggregates common data and multiple corner case data in a single batch, to balance the data distribution. Extensive experiments on CARLA show that our method outperforms the state-of-the-art approaches in terms of sample efficiency and robustness to input permutations.
Zero-Shot Policy Transfer with Disentangled Task Representation of Meta-Reinforcement Learning
Oct 01, 2022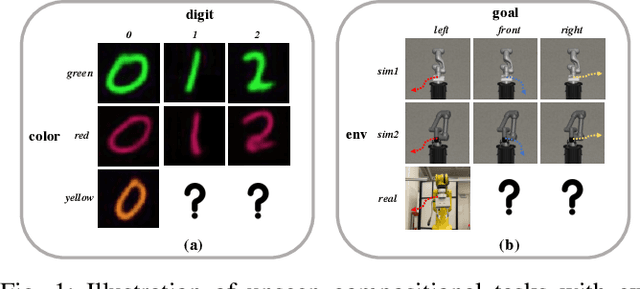
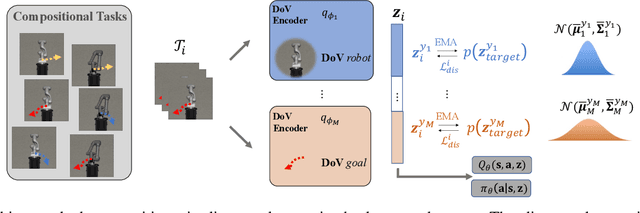
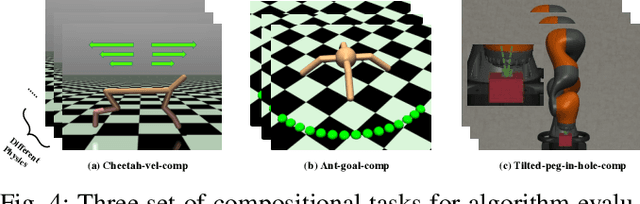
Humans are capable of abstracting various tasks as different combinations of multiple attributes. This perspective of compositionality is vital for human rapid learning and adaption since previous experiences from related tasks can be combined to generalize across novel compositional settings. In this work, we aim to achieve zero-shot policy generalization of Reinforcement Learning (RL) agents by leveraging the task compositionality. Our proposed method is a meta- RL algorithm with disentangled task representation, explicitly encoding different aspects of the tasks. Policy generalization is then performed by inferring unseen compositional task representations via the obtained disentanglement without extra exploration. The evaluation is conducted on three simulated tasks and a challenging real-world robotic insertion task. Experimental results demonstrate that our proposed method achieves policy generalization to unseen compositional tasks in a zero-shot manner.
Performance-Driven Controller Tuning via Derivative-Free Reinforcement Learning
Sep 11, 2022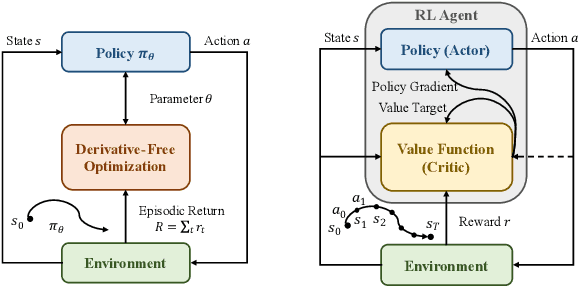
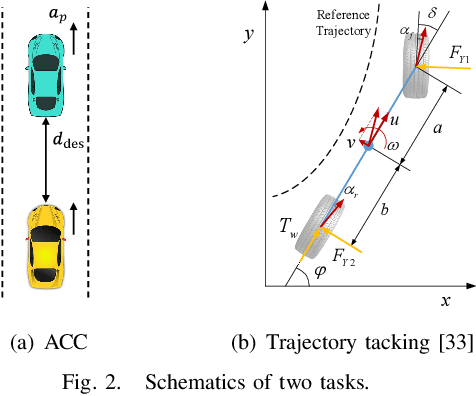
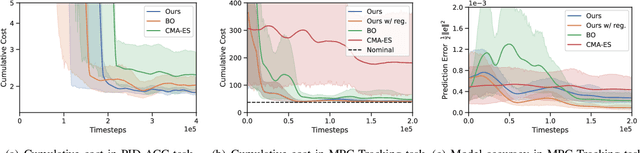
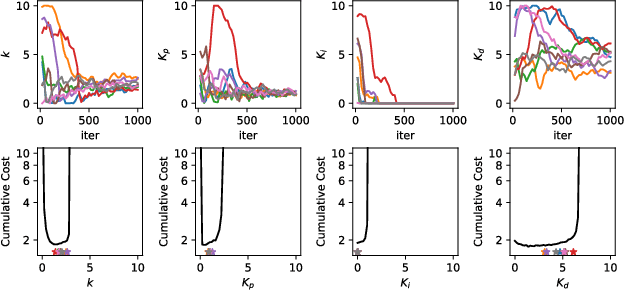
Choosing an appropriate parameter set for the designed controller is critical for the final performance but usually requires a tedious and careful tuning process, which implies a strong need for automatic tuning methods. However, among existing methods, derivative-free ones suffer from poor scalability or low efficiency, while gradient-based ones are often unavailable due to possibly non-differentiable controller structure. To resolve the issues, we tackle the controller tuning problem using a novel derivative-free reinforcement learning (RL) framework, which performs timestep-wise perturbation in parameter space during experience collection and integrates derivative-free policy updates into the advanced actor-critic RL architecture to achieve high versatility and efficiency. To demonstrate the framework's efficacy, we conduct numerical experiments on two concrete examples from autonomous driving, namely, adaptive cruise control with PID controller and trajectory tracking with MPC controller. Experimental results show that the proposed method outperforms popular baselines and highlight its strong potential for controller tuning.
A Contact-Safe Reinforcement Learning Framework for Contact-Rich Robot Manipulation
Jul 27, 2022
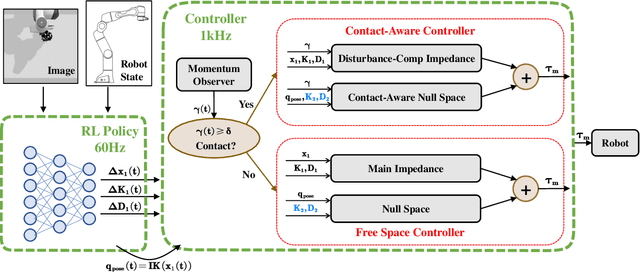
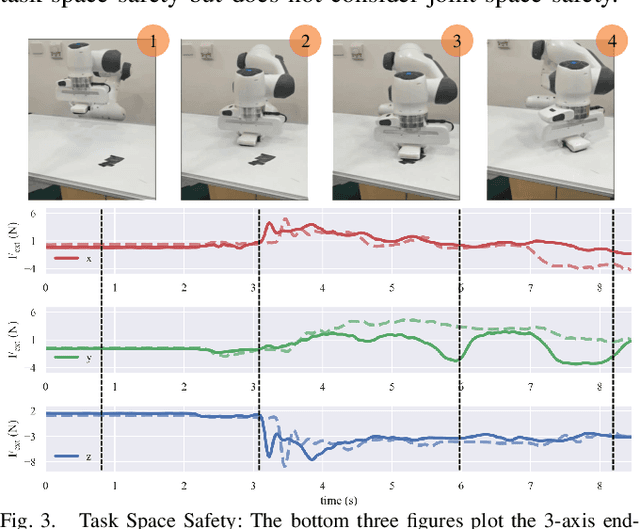
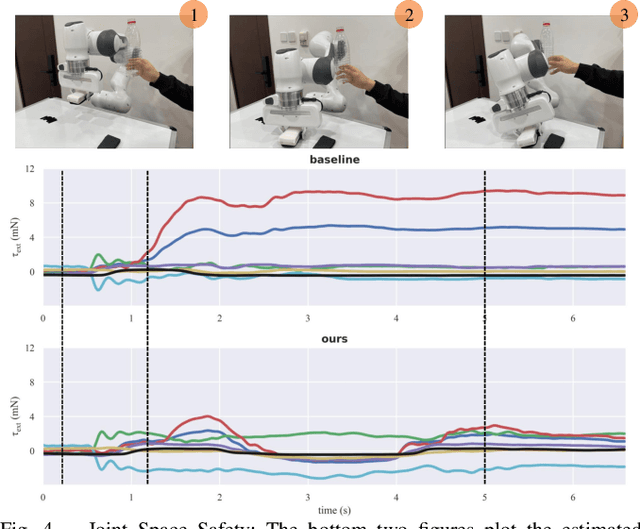
Reinforcement learning shows great potential to solve complex contact-rich robot manipulation tasks. However, the safety of using RL in the real world is a crucial problem, since unexpected dangerous collisions might happen when the RL policy is imperfect during training or in unseen scenarios. In this paper, we propose a contact-safe reinforcement learning framework for contact-rich robot manipulation, which maintains safety in both the task space and joint space. When the RL policy causes unexpected collisions between the robot arm and the environment, our framework is able to immediately detect the collision and ensure the contact force to be small. Furthermore, the end-effector is enforced to perform contact-rich tasks compliantly, while keeping robust to external disturbances. We train the RL policy in simulation and transfer it to the real robot. Real world experiments on robot wiping tasks show that our method is able to keep the contact force small both in task space and joint space even when the policy is under unseen scenario with unexpected collision, while rejecting the disturbances on the main task.
CtrlFormer: Learning Transferable State Representation for Visual Control via Transformer
Jun 17, 2022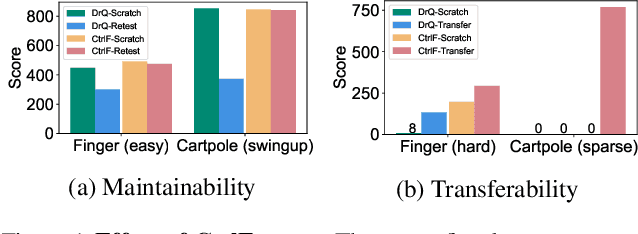

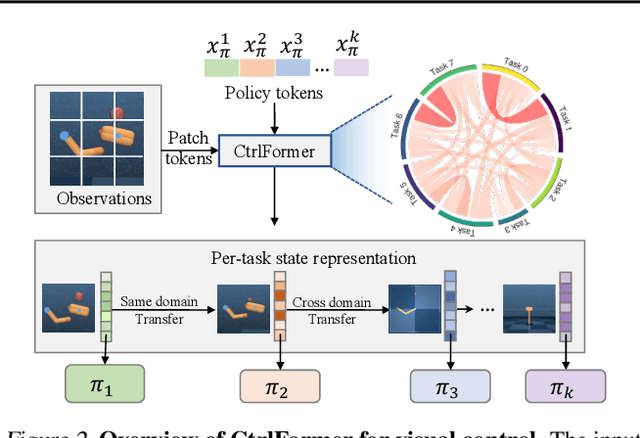

Transformer has achieved great successes in learning vision and language representation, which is general across various downstream tasks. In visual control, learning transferable state representation that can transfer between different control tasks is important to reduce the training sample size. However, porting Transformer to sample-efficient visual control remains a challenging and unsolved problem. To this end, we propose a novel Control Transformer (CtrlFormer), possessing many appealing benefits that prior arts do not have. Firstly, CtrlFormer jointly learns self-attention mechanisms between visual tokens and policy tokens among different control tasks, where multitask representation can be learned and transferred without catastrophic forgetting. Secondly, we carefully design a contrastive reinforcement learning paradigm to train CtrlFormer, enabling it to achieve high sample efficiency, which is important in control problems. For example, in the DMControl benchmark, unlike recent advanced methods that failed by producing a zero score in the "Cartpole" task after transfer learning with 100k samples, CtrlFormer can achieve a state-of-the-art score with only 100k samples while maintaining the performance of previous tasks. The code and models are released in our project homepage.
Flow-based Recurrent Belief State Learning for POMDPs
May 23, 2022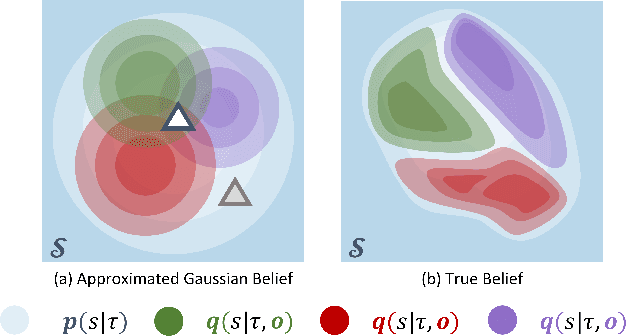
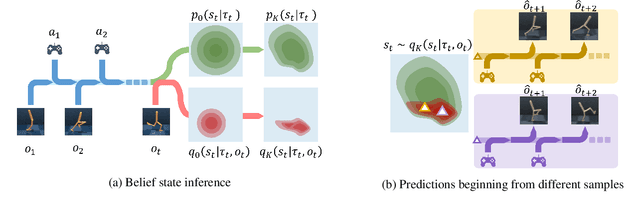
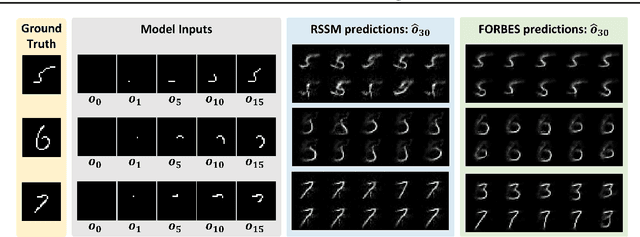
Partially Observable Markov Decision Process (POMDP) provides a principled and generic framework to model real world sequential decision making processes but yet remains unsolved, especially for high dimensional continuous space and unknown models. The main challenge lies in how to accurately obtain the belief state, which is the probability distribution over the unobservable environment states given historical information. Accurately calculating this belief state is a precondition for obtaining an optimal policy of POMDPs. Recent advances in deep learning techniques show great potential to learn good belief states. However, existing methods can only learn approximated distribution with limited flexibility. In this paper, we introduce the \textbf{F}l\textbf{O}w-based \textbf{R}ecurrent \textbf{BE}lief \textbf{S}tate model (FORBES), which incorporates normalizing flows into the variational inference to learn general continuous belief states for POMDPs. Furthermore, we show that the learned belief states can be plugged into downstream RL algorithms to improve performance. In experiments, we show that our methods successfully capture the complex belief states that enable multi-modal predictions as well as high quality reconstructions, and results on challenging visual-motor control tasks show that our method achieves superior performance and sample efficiency.
Reachability Constrained Reinforcement Learning
May 16, 2022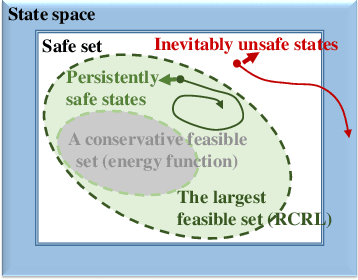
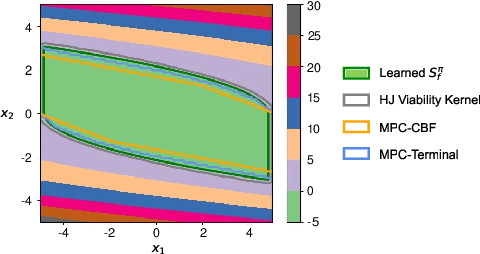
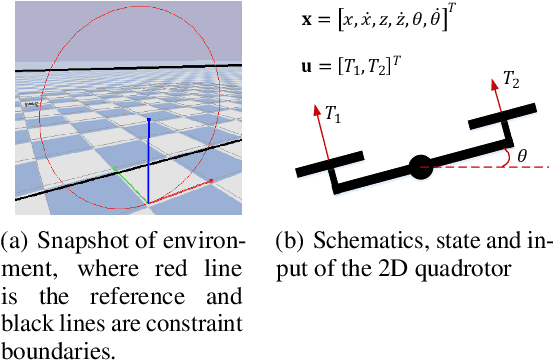
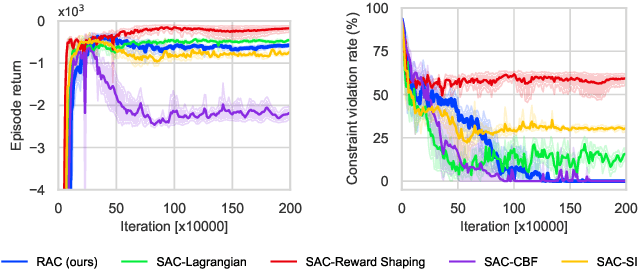
Constrained Reinforcement Learning (CRL) has gained significant interest recently, since the satisfaction of safety constraints is critical for real world problems. However, existing CRL methods constraining discounted cumulative costs generally lack rigorous definition and guarantee of safety. On the other hand, in the safe control research, safety is defined as persistently satisfying certain state constraints. Such persistent safety is possible only on a subset of the state space, called feasible set, where an optimal largest feasible set exists for a given environment. Recent studies incorporating safe control with CRL using energy-based methods such as control barrier function (CBF), safety index (SI) leverage prior conservative estimation of feasible sets, which harms performance of the learned policy. To deal with this problem, this paper proposes a reachability CRL (RCRL) method by using reachability analysis to characterize the largest feasible sets. We characterize the feasible set by the established self-consistency condition, then a safety value function can be learned and used as constraints in CRL. We also use the multi-time scale stochastic approximation theory to prove that the proposed algorithm converges to a local optimum, where the largest feasible set can be guaranteed. Empirical results on different benchmarks such as safe-control-gym and Safety-Gym validate the learned feasible set, the performance in optimal criteria, and constraint satisfaction of RCRL, compared to state-of-the-art CRL baselines.