 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-by-Narrating: Narrative Pre-Training for Zero-Shot Dialogue Comprehension
Mar 19, 2022

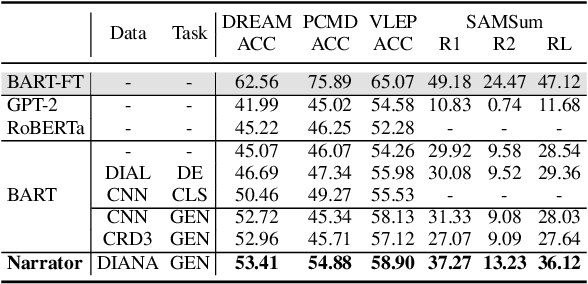
Comprehending a dialogue requires a model to capture diverse kinds of key information in the utterances, which are either scattered around or implicitly implied in different turns of conversations. Therefore, dialogue comprehension requires diverse capabilities such as paraphrasing, summarizing, and commonsense reasoning. Towards the objective of pre-training a zero-shot dialogue comprehension model, we develop a novel narrative-guided pre-training strategy that learns by narrating the key information from a dialogue input. However, the dialogue-narrative parallel corpus for such a pre-training strategy is currently unavailable. For this reason, we first construct a dialogue-narrative parallel corpus by automatically aligning movie subtitles and their synopses. We then pre-train a BART model on the data and evaluate its performance on four dialogue-based tasks that require comprehension. Experimental results show that our model not only achieves superior zero-shot performance but also exhibits stronger fine-grained dialogue comprehension capabilities. The data and code are available at https://github.com/zhaochaocs/Diana
PRIMA: Planner-Reasoner Inside a Multi-task Reasoning Agent
Feb 13, 2022

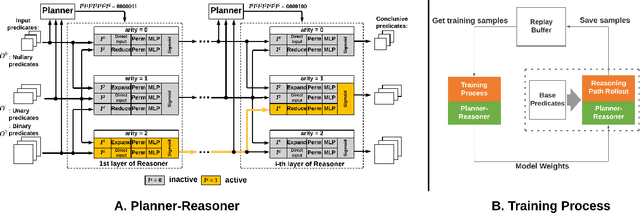
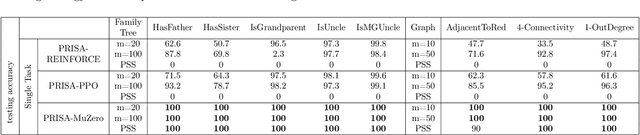
We consider the problem of multi-task reasoning (MTR), where an agent can solve multiple tasks via (first-order) logic reasoning. This capability is essential for human-like intelligence due to its strong generalizability and simplicity for handling multiple tasks. However, a major challenge in developing effective MTR is the intrinsic conflict between reasoning capability and efficiency. An MTR-capable agent must master a large set of "skills" to tackle diverse tasks, but executing a particular task at the inference stage requires only a small subset of immediately relevant skills. How can we maintain broad reasoning capability and also efficient specific-task performance? To address this problem, we propose a Planner-Reasoner framework capable of state-of-the-art MTR capability and high efficiency. The Reasoner models shareable (first-order) logic deduction rules, from which the Planner selects a subset to compose into efficient reasoning paths. The entire model is trained in an end-to-end manner using deep reinforcement learning, and experimental studies over a variety of domains validate its effectiveness.
Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories
Oct 27, 2021
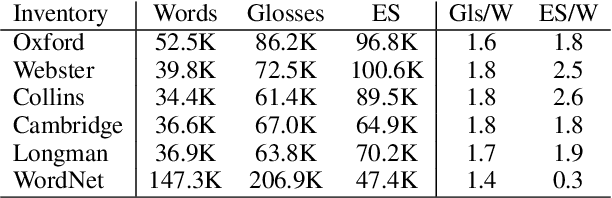
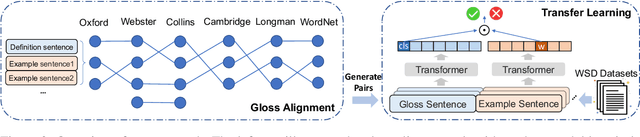

Word Sense Disambiguation (WSD) aims to automatically identify the exact meaning of one word according to its context. Existing supervised models struggle to make correct predictions on rare word senses due to limited training data and can only select the best definition sentence from one predefined word sense inventory (e.g., WordNet). To address the data sparsity problem and generalize the model to be independent of one predefined inventory, we propose a gloss alignment algorithm that can align definition sentences (glosses) with the same meaning from different sense inventories to collect rich lexical knowledge. We then train a model to identify semantic equivalence between a target word in context and one of its glosses using these aligned inventories, which exhibits strong transfer capability to many WSD tasks. Experiments on benchmark datasets show that the proposed method improves predictions on both frequent and rare word senses, outperforming prior work by 1.2% on the All-Words WSD Task and 4.3% on the Low-Shot WSD Task. Evaluation on WiC Task also indicates that our method can better capture word meanings in context.
Improving Machine Reading Comprehension with Contextualized Commonsense Knowledge
Sep 12, 2020
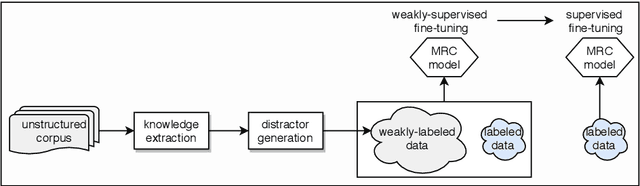
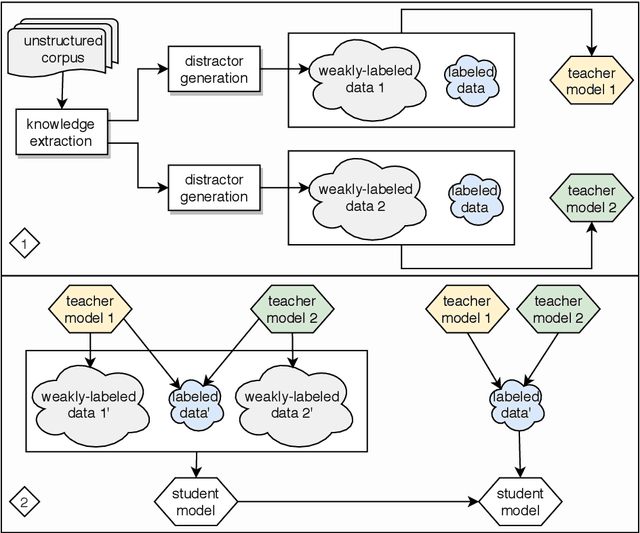
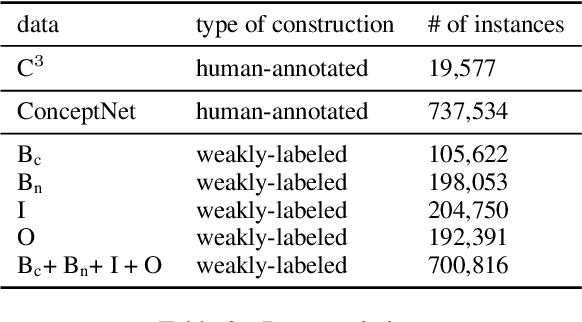
In this paper, we aim to extract commonsense knowledge to improve machine reading comprehension. We propose to represent relations implicitly by situating structured knowledge in a context instead of relying on a pre-defined set of relations, and we call it contextualized knowledge. Each piece of contextualized knowledge consists of a pair of interrelated verbal and nonverbal messages extracted from a script and the scene in which they occur as context to implicitly represent the relation between the verbal and nonverbal messages, which are originally conveyed by different modalities within the script. We propose a two-stage fine-tuning strategy to use the large-scale weakly-labeled data based on a single type of contextualized knowledge and employ a teacher-student paradigm to inject multiple types of contextualized knowledge into a student machine reader. Experimental results demonstrate that our method outperforms a state-of-the-art baseline by a 4.3% improvement in accuracy on the machine reading comprehension dataset C^3, wherein most of the questions require unstated prior knowledge.
Comprehensive Image Captioning via Scene Graph Decomposition
Jul 23, 2020
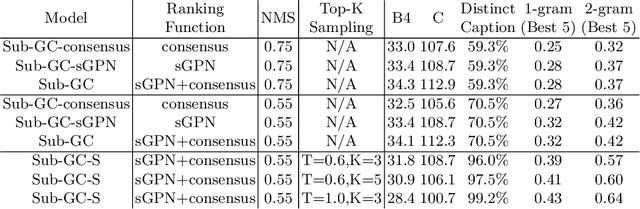
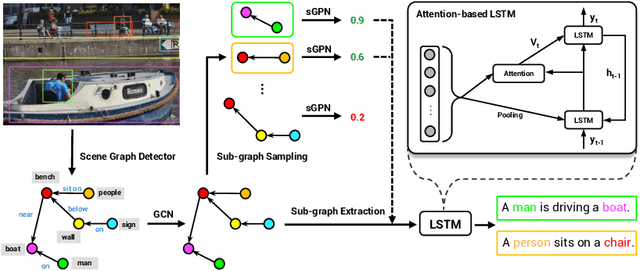
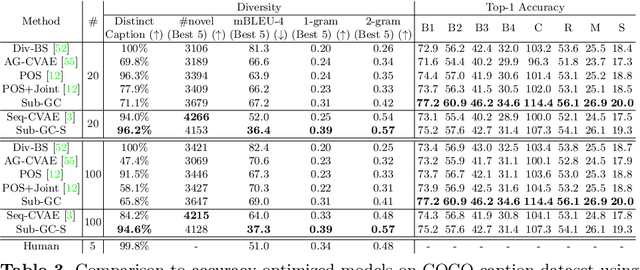
We address the challenging problem of image captioning by revisiting the representation of image scene graph. At the core of our method lies the decomposition of a scene graph into a set of sub-graphs, with each sub-graph capturing a semantic component of the input image. We design a deep model to select important sub-graphs, and to decode each selected sub-graph into a single target sentence. By using sub-graphs, our model is able to attend to different components of the image. Our method thus accounts for accurate, diverse, grounded and controllable captioning at the same time. We present extensive experiments to demonstrate the benefits of our comprehensive captioning model. Our method establishes new state-of-the-art results in caption diversity, grounding, and controllability, and compares favourably to latest methods in caption quality. Our project website can be found at http://pages.cs.wisc.edu/~yiwuzhong/Sub-GC.html.
On Effective Parallelization of Monte Carlo Tree Search
Jun 15, 2020

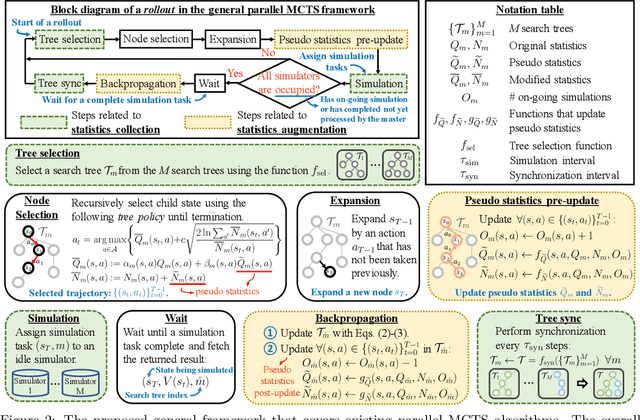
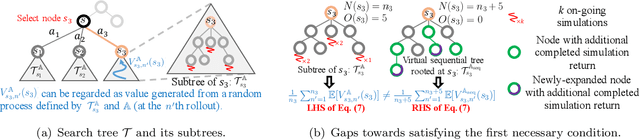
Despite its groundbreaking success in Go and computer games, Monte Carlo Tree Search (MCTS) is computationally expensive as it requires a substantial number of rollouts to construct the search tree, which calls for effective parallelization. However, how to design effective parallel MCTS algorithms has not been systematically studied and remains poorly understood. In this paper, we seek to lay its first theoretical foundations, by examining the potential performance loss caused by parallelization when achieving a desired speedup. In particular, we focus on studying the conditions under which the performance loss (measured in excess regret) vanishes over time. To this end, we propose a general parallel MCTS framework that can be specialized to major existing parallel MCTS algorithms. We derive two necessary conditions for the algorithms covered by the general framework to have vanishing excess regret (i.e. excess regret converges to zero as the total number of rollouts grows). We demonstrate the effectiveness of the necessary conditions by showing that, for depth-2 search trees, the recently developed WU-UCT algorithm satisfies both necessary conditions and has provable vanishing excess regret. Finally, we perform empirical studies to closely examine the necessary conditions under the general tree search setting (with arbitrary tree depth). It shows that the topological discrepancy between the search trees constructed by the parallel and the sequential MCTS algorithms is the main reason for the performance loss.
Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension
May 19, 2020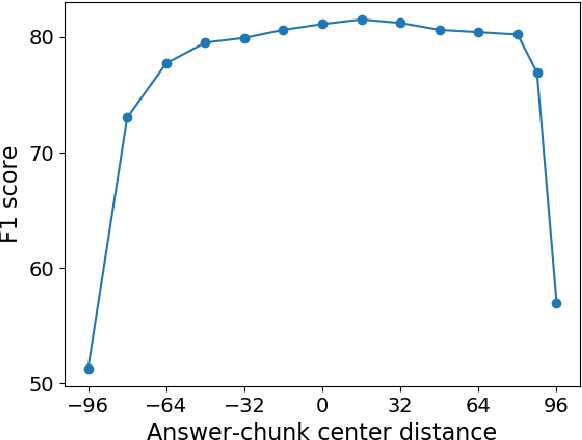

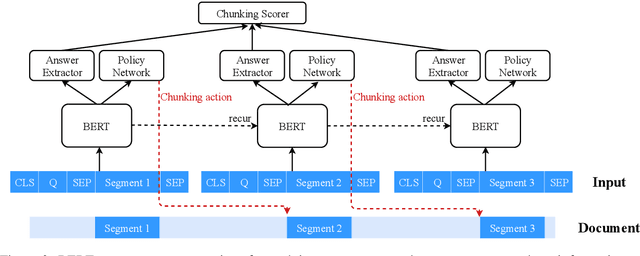
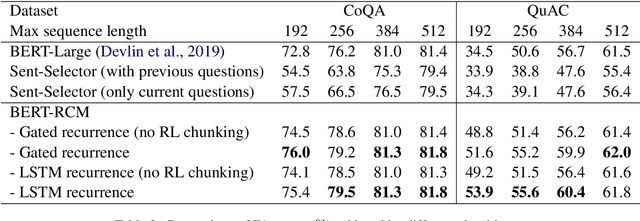
In this paper, we study machine reading comprehension (MRC) on long texts, where a model takes as inputs a lengthy document and a question and then extracts a text span from the document as an answer. State-of-the-art models tend to use a pretrained transformer model (e.g., BERT) to encode the joint contextual information of document and question. However, these transformer-based models can only take a fixed-length (e.g., 512) text as its input. To deal with even longer text inputs, previous approaches usually chunk them into equally-spaced segments and predict answers based on each segment independently without considering the information from other segments. As a result, they may form segments that fail to cover the correct answer span or retain insufficient contexts around it, which significantly degrades the performance. Moreover, they are less capable of answering questions that need cross-segment information. We propose to let a model learn to chunk in a more flexible way via reinforcement learning: a model can decide the next segment that it wants to process in either direction. We also employ recurrent mechanisms to enable information to flow across segments. Experiments on three MRC datasets -- CoQA, QuAC, and TriviaQA -- demonstrate the effectiveness of our proposed recurrent chunking mechanisms: we can obtain segments that are more likely to contain complete answers and at the same time provide sufficient contexts around the ground truth answers for better predictions.
Logical Natural Language Generation from Open-Domain Tables
Apr 28, 2020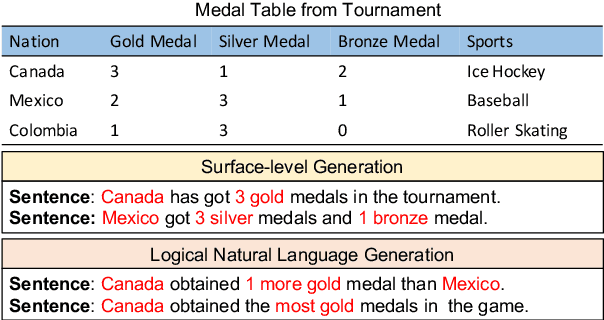

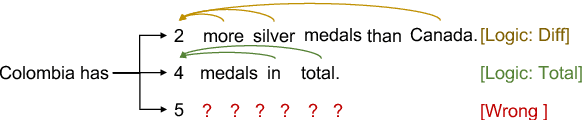
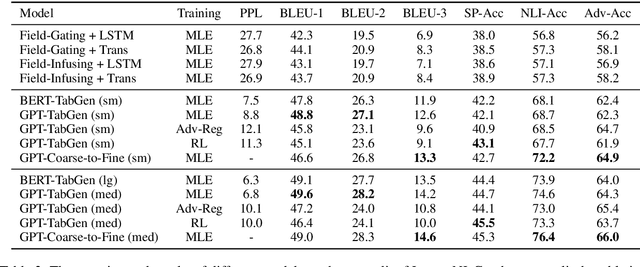
Neural natural language generation (NLG) models have recently shown remarkable progress in fluency and coherence. However, existing studies on neural NLG are primarily focused on surface-level realizations with limited emphasis on logical inference, an important aspect of human thinking and language. In this paper, we suggest a new NLG task where a model is tasked with generating natural language statements that can be \emph{logically entailed} by the facts in an open-domain semi-structured table. To facilitate the study of the proposed logical NLG problem, we use the existing TabFact dataset \cite{chen2019tabfact} featured with a wide range of logical/symbolic inferences as our testbed, and propose new automatic metrics to evaluate the fidelity of generation models w.r.t.\ logical inference. The new task poses challenges to the existing monotonic generation frameworks due to the mismatch between sequence order and logical order. In our experiments, we comprehensively survey different generation architectures (LSTM, Transformer, Pre-Trained LM) trained with different algorithms (RL, Adversarial Training, Coarse-to-Fine) on the dataset and made following observations: 1) Pre-Trained LM can significantly boost both the fluency and logical fidelity metrics, 2) RL and Adversarial Training are trading fluency for fidelity, 3) Coarse-to-Fine generation can help partially alleviate the fidelity issue while maintaining high language fluency. The code and data are available at \url{https://github.com/wenhuchen/LogicNLG}.
TabFact: A Large-scale Dataset for Table-based Fact Verification
Oct 08, 2019
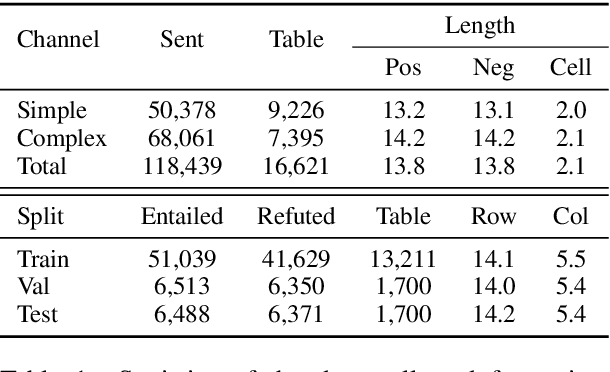
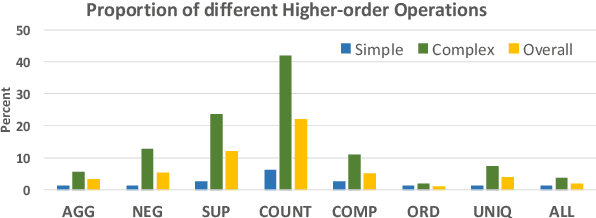
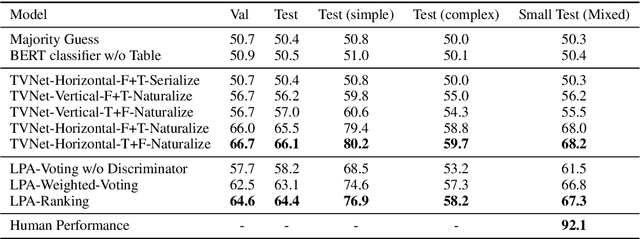
The problem of verifying whether a textual hypothesis holds based on the given evidence, also known as fact verification, plays an important role in the study of natural language understanding and semantic representation. However, existing studies are mainly restricted to dealing with unstructured evidence (e.g., natural language sentences and documents, news, etc), while verification under structured evidence, such as tables, graphs, and databases, remains unexplored. This paper specifically aims to study the fact verification given semi-structured data as evidence. To this end, we construct a large-scale dataset called TabFact with 16k Wikipedia tables as the evidence for 118k human-annotated natural language statements, which are labeled as either ENTAILED or REFUTED. TabFact is challenging since it involves both soft linguistic reasoning and hard symbolic reasoning. To address these reasoning challenges, we design two different models: Table-BERT and Latent Program Algorithm (LPA). Table-BERT leverages the state-of-the-art pre-trained language model to encode the linearized tables and statements into continuous vectors for verification. LPA parses statements into LISP-like programs and executes them against the tables to obtain the returned binary value for verification. Both methods achieve similar accuracy but still lag far behind human performance. We also perform a comprehensive analysis to demonstrate great future opportunities. The data and code of the dataset are provided in \url{https://github.com/wenhuchen/Table-Fact-Checking}.
Teaching Pretrained Models with Commonsense Reasoning: A Preliminary KB-Based Approach
Sep 20, 2019
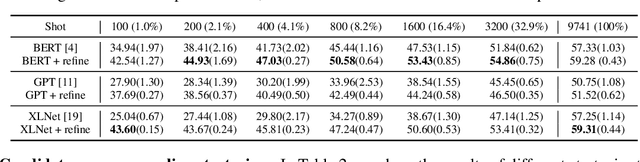


Recently, pretrained language models (e.g., BERT) have achieved great success on many downstream natural language understanding tasks and exhibit a certain level of commonsense reasoning ability. However, their performance on commonsense tasks is still far from that of humans. As a preliminary attempt, we propose a simple yet effective method to teach pretrained models with commonsense reasoning by leveraging the structured knowledge in ConceptNet, the largest commonsense knowledge base (KB). Specifically, the structured knowledge in KB allows us to construct various logical forms, and then generate multiple-choice questions requiring commonsense logical reasoning. Experimental results demonstrate that, when refined on these training examples, the pretrained models consistently improve their performance on tasks that require commonsense reasoning, especially in the few-shot learning setting. Besides, we also perform analysis to understand which logical relations are more relevant to commonsense reasoning.