 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving VLA Policies: Selected Diffusion Noise for Spurious-Robust Action Smoothing
Jun 12, 2026Diffusion-based Vision-Language-Action (VLA) policies enable strong generalization in robotic manipulation, but remain sensitive to spurious visual correlations and noisy action generation, leading to brittle behavior under perturbations. We introduce Selected Diffusion Noise (SDN), a simple, training-free test-time method that improves both robustness and success rate by leveraging the diffusion noise space as a controllable degree of freedom. SDN dynamically samples noise vectors that are maximally separated from a reference set to mitigate reliance on spurious cues, while selecting candidates that yield more coherent action trajectories. This dual objective encourages stable behavior even under object-masked observations and reduces action jitter without modifying model parameters. We evaluate SDN on two simulation benchmarks (Google Robot, Widow-X) and two real-world robotic datasets across multiple VLA policies, including pi_0, Groot-N1.5, and Groot-N1.6. SDN consistently improves success rates by +8% in simulation and +10% in real-world settings, while producing smoother and more stable actions. Our results highlight that diffusion noise selection can serve as an effective and general mechanism for enhancing VLA policies at test time.
The Expressivity Boundary of Probabilistic Circuits: A Comparison with Large Language Models
May 13, 2026Probabilistic Circuits (PCs) are deep generative models that support exact and efficient probabilistic inference. Yet in autoregressive language modeling, PCs still lag behind Transformer-based large language models (LLMs), suggesting an important expressivity gap. In this work, we compare PCs and LLMs under a unified autoregressive formulation. First, an output bottleneck: PCs parameterize predictions as convex combinations in probability space, which struggles to represent the sharp distributions typical of language; adopting a logit-space parameterization substantially narrows this gap. Second, a context-encoding bottleneck: we prove that structured-decomposable PCs can match Transformer separation rank on vtree-aligned partitions, but show, both theoretically and empirically, that this capacity is limited to partitions aligned with the fixed routing structure, leading to severe degradation when the data exhibits heterogeneous dependency topologies. We further prove that decomposable PCs are strictly more expressive than structured-decomposable ones, though effectively optimizing them remains an open challenge.
Lookahead Path Likelihood Optimization for Diffusion LLMs
Feb 03, 2026Diffusion Large Language Models (dLLMs) support arbitrary-order generation, yet their inference performance critically depends on the unmasking order. Existing strategies rely on heuristics that greedily optimize local confidence, offering limited guidance for identifying unmasking paths that are globally consistent and accurate. To bridge this gap, we introduce path log-likelihood (Path LL), a trajectory-conditioned objective that strongly correlates with downstream accuracy and enables principled selection of unmasking paths. To optimize Path LL at inference time, we propose POKE, an efficient value estimator that predicts the expected future Path LL of a partial decoding trajectory. We then integrate this lookahead signal into POKE-SMC, a Sequential Monte Carlo-based search framework for dynamically identifying optimal unmasking paths. Extensive experiments across 6 reasoning tasks show that POKE-SMC consistently improves accuracy, achieving 2%--3% average gains over strong decoding-time scaling baselines at comparable inference overhead on LLaDA models and advancing the accuracy--compute Pareto frontier.
Training One Model to Master Cross-Level Agentic Actions via Reinforcement Learning
Dec 10, 2025The paradigm of agentic AI is shifting from engineered complex workflows to post-training native models. However, existing agents are typically confined to static, predefined action spaces--such as exclusively using APIs, GUI events, or robotic commands. This rigidity limits their adaptability in dynamic environments where the optimal granularity of interaction varies contextually. To bridge this gap, we propose CrossAgent, a unified agentic model that masters heterogeneous action spaces and autonomously selects the most effective interface for each step of a trajectory. We introduce a comprehensive training pipeline that integrates cold-start supervised fine-tuning with a Multi-Turn Group Relative Policy Optimization (GRPO) algorithm. This approach enables the agent to learn adaptive action switching--balancing high-level efficiency with low-level precision--without human-specified rules. Extensive experiments on over 800 tasks in the open-world Minecraft environment demonstrate that CrossAgent achieves state-of-the-art performance. By dynamically leveraging the strengths of diverse action spaces, our model significantly outperforms fixed-action baselines, exhibiting superior generalization and efficiency in long-horizon reasoning. All code and models are available at https://github.com/CraftJarvis/OpenHA
S-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025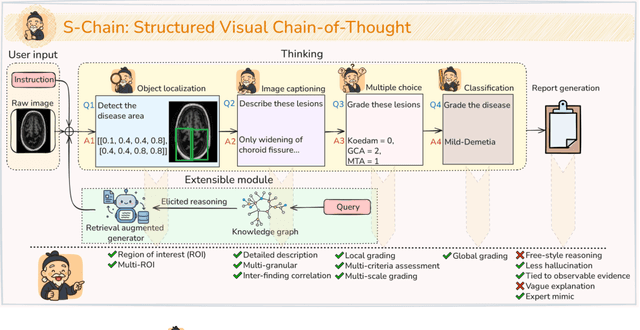
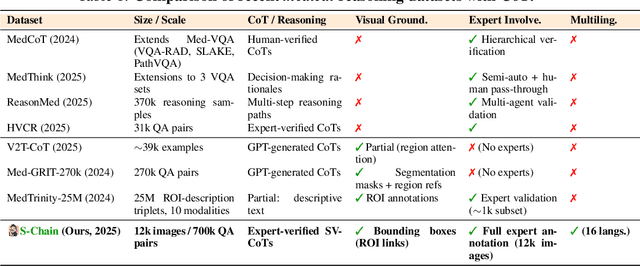
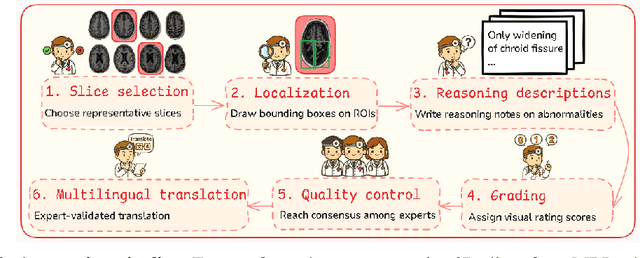
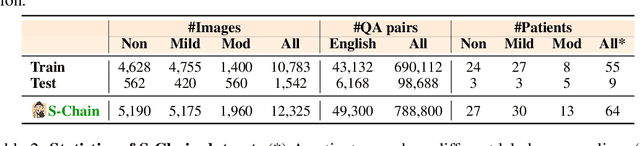
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents
Jul 31, 2025While Reinforcement Learning (RL) has achieved remarkable success in language modeling, its triumph hasn't yet fully translated to visuomotor agents. A primary challenge in RL models is their tendency to overfit specific tasks or environments, thereby hindering the acquisition of generalizable behaviors across diverse settings. This paper provides a preliminary answer to this challenge by demonstrating that RL-finetuned visuomotor agents in Minecraft can achieve zero-shot generalization to unseen worlds. Specifically, we explore RL's potential to enhance generalizable spatial reasoning and interaction capabilities in 3D worlds. To address challenges in multi-task RL representation, we analyze and establish cross-view goal specification as a unified multi-task goal space for visuomotor policies. Furthermore, to overcome the significant bottleneck of manual task design, we propose automated task synthesis within the highly customizable Minecraft environment for large-scale multi-task RL training, and we construct an efficient distributed RL framework to support this. Experimental results show RL significantly boosts interaction success rates by $4\times$ and enables zero-shot generalization of spatial reasoning across diverse environments, including real-world settings. Our findings underscore the immense potential of RL training in 3D simulated environments, especially those amenable to large-scale task generation, for significantly advancing visuomotor agents' spatial reasoning.
Mitigating Reward Over-optimization in Direct Alignment Algorithms with Importance Sampling
Jun 11, 2025Direct Alignment Algorithms (DAAs) such as Direct Preference Optimization (DPO) have emerged as alternatives to the standard Reinforcement Learning from Human Feedback (RLHF) for aligning large language models (LLMs) with human values. However, these methods are more susceptible to over-optimization, in which the model drifts away from the reference policy, leading to degraded performance as training progresses. This paper proposes a novel importance-sampling approach to mitigate the over-optimization problem of offline DAAs. This approach, called (IS-DAAs), multiplies the DAA objective with an importance ratio that accounts for the reference policy distribution. IS-DAAs additionally avoid the high variance issue associated with importance sampling by clipping the importance ratio to a maximum value. Our extensive experiments demonstrate that IS-DAAs can effectively mitigate over-optimization, especially under low regularization strength, and achieve better performance than other methods designed to address this problem. Our implementations are provided publicly at this link.
Rethinking Probabilistic Circuit Parameter Learning
May 26, 2025Probabilistic Circuits (PCs) offer a computationally scalable framework for generative modeling, supporting exact and efficient inference of a wide range of probabilistic queries. While recent advances have significantly improved the expressiveness and scalability of PCs, effectively training their parameters remains a challenge. In particular, a widely used optimization method, full-batch Expectation-Maximization (EM), requires processing the entire dataset before performing a single update, making it ineffective for large datasets. While empirical extensions to the mini-batch setting have been proposed, it remains unclear what objective these algorithms are optimizing, making it difficult to assess their theoretical soundness. This paper bridges the gap by establishing a novel connection between the general EM objective and the standard full-batch EM algorithm. Building on this, we derive a theoretically grounded generalization to the mini-batch setting and demonstrate its effectiveness through preliminary empirical results.
Plug-and-Play Context Feature Reuse for Efficient Masked Generation
May 25, 2025Masked generative models (MGMs) have emerged as a powerful framework for image synthesis, combining parallel decoding with strong bidirectional context modeling. However, generating high-quality samples typically requires many iterative decoding steps, resulting in high inference costs. A straightforward way to speed up generation is by decoding more tokens in each step, thereby reducing the total number of steps. However, when many tokens are decoded simultaneously, the model can only estimate the univariate marginal distributions independently, failing to capture the dependency among them. As a result, reducing the number of steps significantly compromises generation fidelity. In this work, we introduce ReCAP (Reused Context-Aware Prediction), a plug-and-play module that accelerates inference in MGMs by constructing low-cost steps via reusing feature embeddings from previously decoded context tokens. ReCAP interleaves standard full evaluations with lightweight steps that cache and reuse context features, substantially reducing computation while preserving the benefits of fine-grained, iterative generation. We demonstrate its effectiveness on top of three representative MGMs (MaskGIT, MAGE, and MAR), including both discrete and continuous token spaces and covering diverse architectural designs. In particular, on ImageNet256 class-conditional generation, ReCAP achieves up to 2.4x faster inference than the base model with minimal performance drop, and consistently delivers better efficiency-fidelity trade-offs under various generation settings.
ROCKET-2: Steering Visuomotor Policy via Cross-View Goal Alignment
Mar 04, 2025



We aim to develop a goal specification method that is semantically clear, spatially sensitive, and intuitive for human users to guide agent interactions in embodied environments. Specifically, we propose a novel cross-view goal alignment framework that allows users to specify target objects using segmentation masks from their own camera views rather than the agent's observations. We highlight that behavior cloning alone fails to align the agent's behavior with human intent when the human and agent camera views differ significantly. To address this, we introduce two auxiliary objectives: cross-view consistency loss and target visibility loss, which explicitly enhance the agent's spatial reasoning ability. According to this, we develop ROCKET-2, a state-of-the-art agent trained in Minecraft, achieving an improvement in the efficiency of inference 3x to 6x. We show ROCKET-2 can directly interpret goals from human camera views for the first time, paving the way for better human-agent interaction.