 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig2Small: A Unifying Neural Network Framework for Model Compression
Mar 31, 2026With the development of foundational models, model compression has become a critical requirement. Various model compression approaches have been proposed such as low-rank decomposition, pruning, quantization, ergodic dynamic systems, and knowledge distillation, which are based on different heuristics. To elevate the field from fragmentation to a principled discipline, we construct a unifying mathematical framework for model compression grounded in measure theory. We further demonstrate that each model compression technique is mathematically equivalent to a neural network subject to a regularization. Building upon this mathematical and structural equivalence, we propose an experimentally-verified data-free model compression framework, termed \textit{Big2Small}, which translates Implicit Neural Representations (INRs) from data domain to the domain of network parameters. \textit{Big2Small} trains compact INRs to encode the weights of larger models and reconstruct the weights during inference. To enhance reconstruction fidelity, we introduce Outlier-Aware Preprocessing to handle extreme weight values and a Frequency-Aware Loss function to preserve high-frequency details. Experiments on image classification and segmentation demonstrate that \textit{Big2Small} achieves competitive accuracy and compression ratios compared to state-of-the-art baselines.
PRIMA: Planner-Reasoner Inside a Multi-task Reasoning Agent
Feb 13, 2022

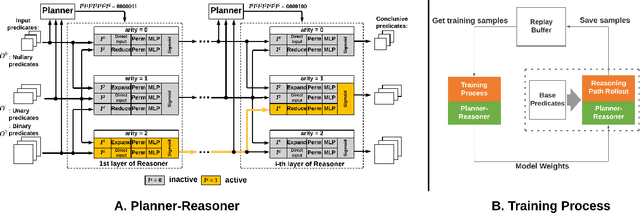
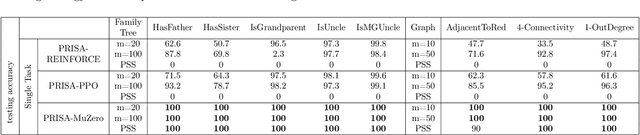
We consider the problem of multi-task reasoning (MTR), where an agent can solve multiple tasks via (first-order) logic reasoning. This capability is essential for human-like intelligence due to its strong generalizability and simplicity for handling multiple tasks. However, a major challenge in developing effective MTR is the intrinsic conflict between reasoning capability and efficiency. An MTR-capable agent must master a large set of "skills" to tackle diverse tasks, but executing a particular task at the inference stage requires only a small subset of immediately relevant skills. How can we maintain broad reasoning capability and also efficient specific-task performance? To address this problem, we propose a Planner-Reasoner framework capable of state-of-the-art MTR capability and high efficiency. The Reasoner models shareable (first-order) logic deduction rules, from which the Planner selects a subset to compose into efficient reasoning paths. The entire model is trained in an end-to-end manner using deep reinforcement learning, and experimental studies over a variety of domains validate its effectiveness.
TOPS: Transition-based VOlatility-controlled Policy Search and its Global Convergence
Jan 24, 2022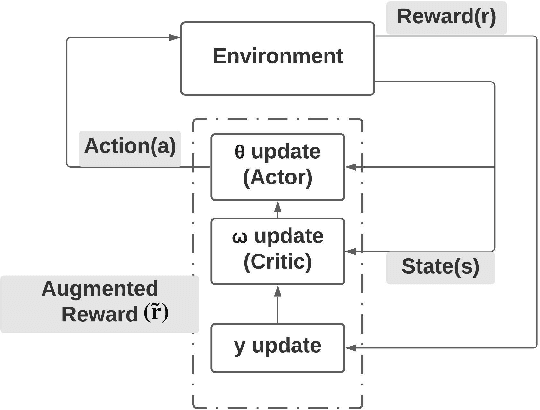
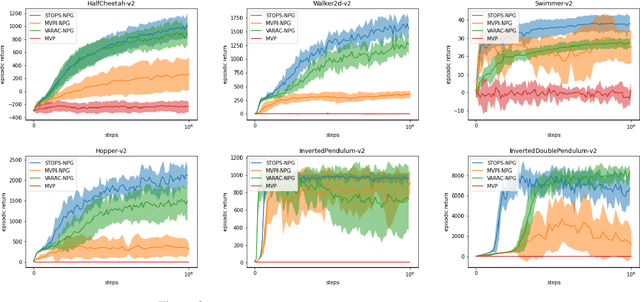
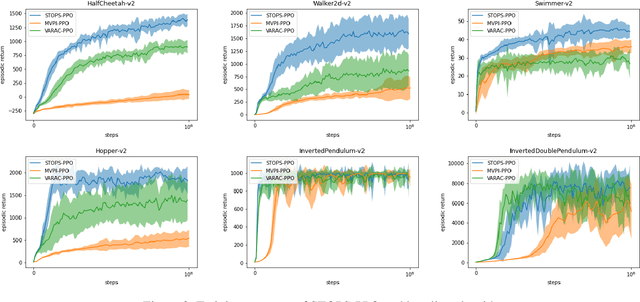
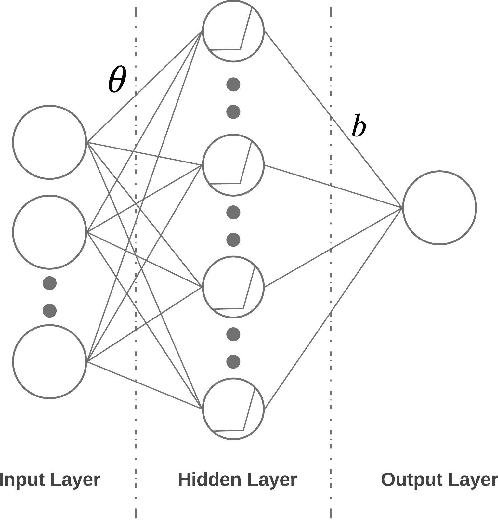
Risk-averse problems receive far less attention than risk-neutral control problems in reinforcement learning, and existing risk-averse approaches are challenging to deploy to real-world applications. One primary reason is that such risk-averse algorithms often learn from consecutive trajectories with a certain length, which significantly increases the potential danger of causing dangerous failures in practice. This paper proposes Transition-based VOlatility-controlled Policy Search (TOPS), a novel algorithm that solves risk-averse problems by learning from (possibly non-consecutive) transitions instead of only consecutive trajectories. By using an actor-critic scheme with an overparameterized two-layer neural network, our algorithm finds a globally optimal policy at a sublinear rate with proximal policy optimization and natural policy gradient, with effectiveness comparable to the state-of-the-art convergence rate of risk-neutral policy-search methods. The algorithm is evaluated on challenging Mujoco robot simulation tasks under the mean-variance evaluation metric. Both theoretical analysis and experimental results demonstrate a state-of-the-art level of risk-averse policy search methods.
TDM: Trustworthy Decision-Making via Interpretability Enhancement
Aug 13, 2021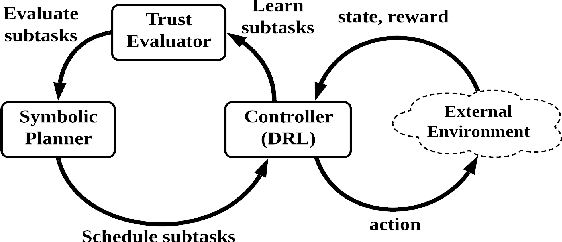
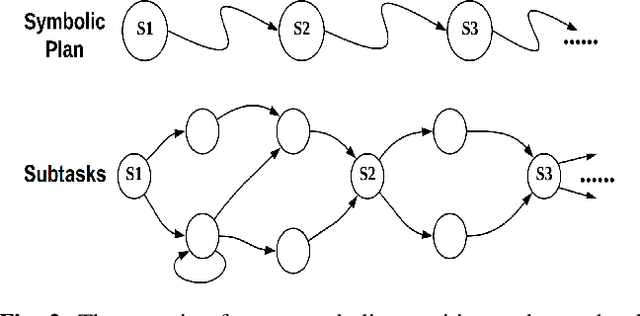
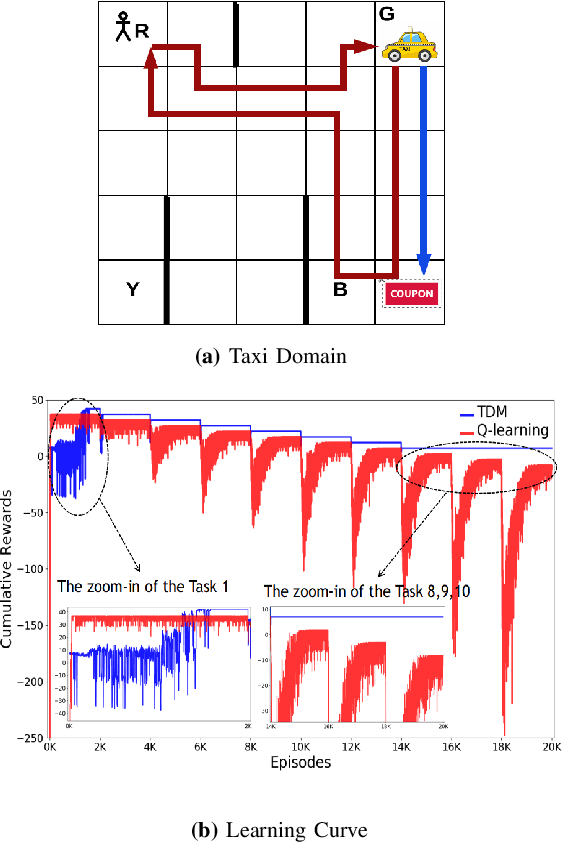
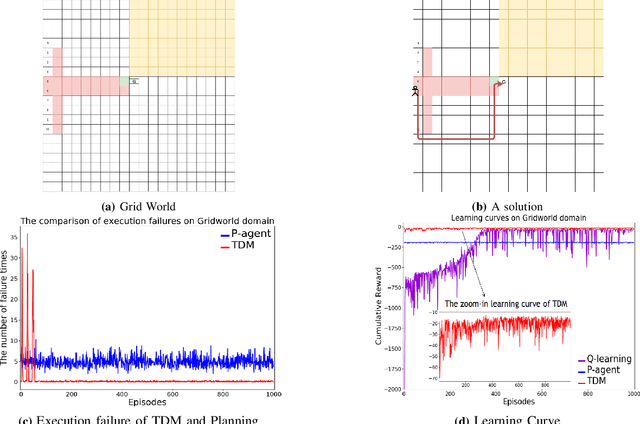
Human-robot interactive decision-making is increasingly becoming ubiquitous, and trust is an influential factor in determining the reliance on autonomy. However, it is not reasonable to trust systems that are beyond our comprehension, and typical machine learning and data-driven decision-making are black-box paradigms that impede interpretability. Therefore, it is critical to establish computational trustworthy decision-making mechanisms enhanced by interpretability-aware strategies. To this end, we propose a Trustworthy Decision-Making (TDM) framework, which integrates symbolic planning into sequential decision-making. The framework learns interpretable subtasks that result in a complex, higher-level composite task that can be formally evaluated using the proposed trust metric. TDM enables the subtask-level interpretability by design and converges to an optimal symbolic plan from the learned subtasks. Moreover, a TDM-based algorithm is introduced to demonstrate the unification of symbolic planning with other sequential-decision making algorithms, reaping the benefits of both. Experimental results validate the effectiveness of trust-score-based planning while improving the interpretability of subtasks.
Variance-Reduced Off-Policy Memory-Efficient Policy Search
Sep 14, 2020
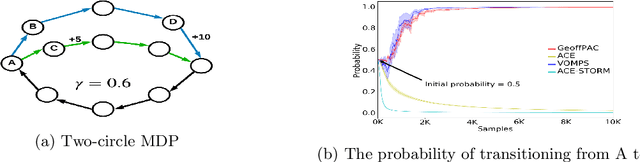
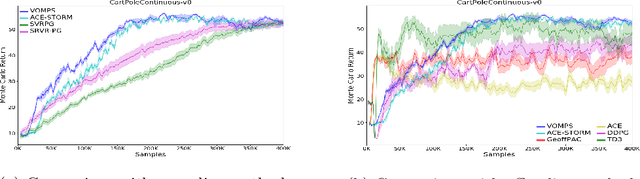
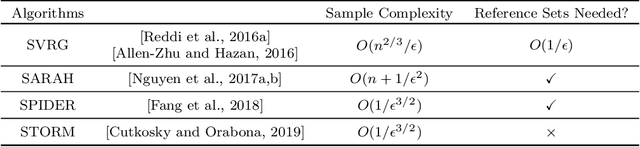
Off-policy policy optimization is a challenging problem in reinforcement learning (RL). The algorithms designed for this problem often suffer from high variance in their estimators, which results in poor sample efficiency, and have issues with convergence. A few variance-reduced on-policy policy gradient algorithms have been recently proposed that use methods from stochastic optimization to reduce the variance of the gradient estimate in the REINFORCE algorithm. However, these algorithms are not designed for the off-policy setting and are memory-inefficient, since they need to collect and store a large ``reference'' batch of samples from time to time. To achieve variance-reduced off-policy-stable policy optimization, we propose an algorithm family that is memory-efficient, stochastically variance-reduced, and capable of learning from off-policy samples. Empirical studies validate the effectiveness of the proposed approaches.
Stable and Efficient Policy Evaluation
Jun 06, 2020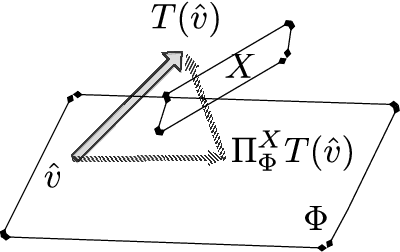
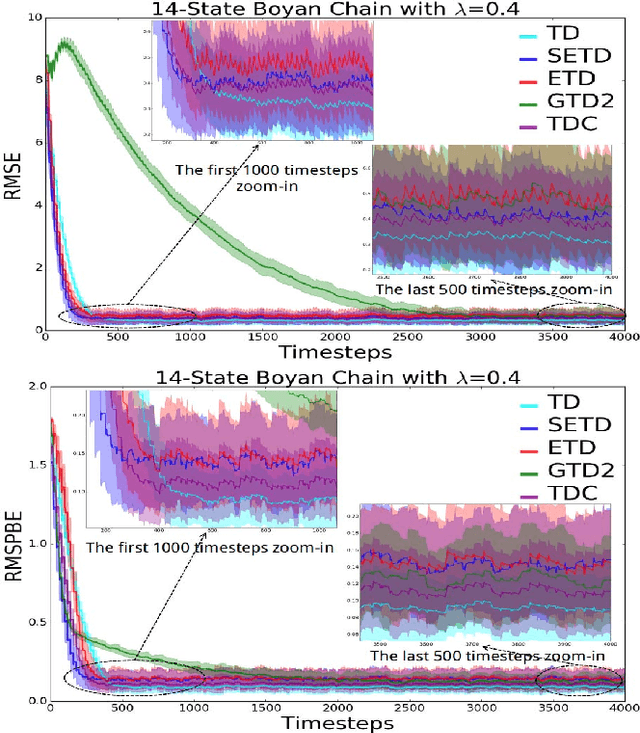
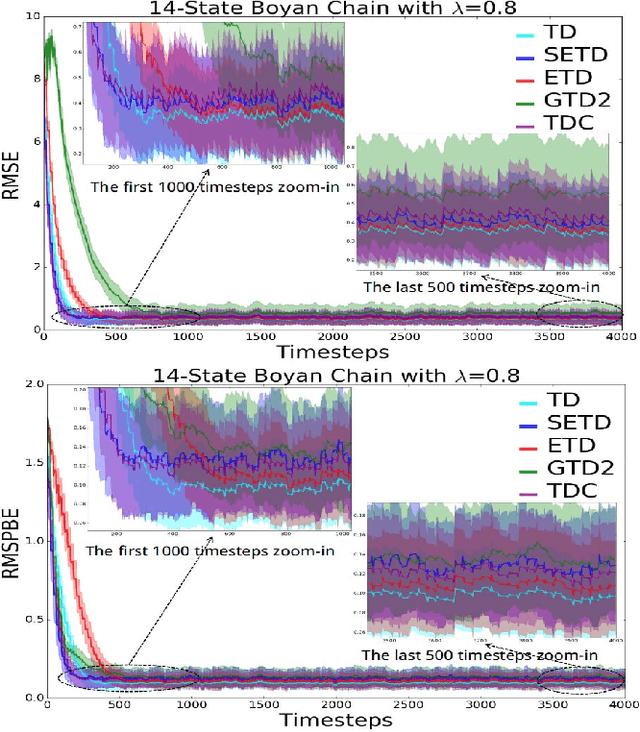
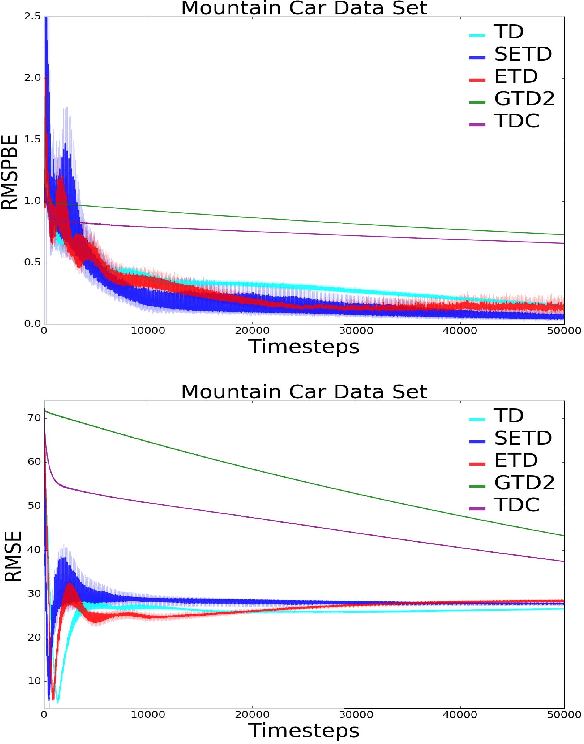
Policy evaluation algorithms are essential to reinforcement learning due to their ability to predict the performance of a policy. However, there are two long-standing issues lying in this prediction problem that need to be tackled: off-policy stability and on-policy efficiency. The conventional temporal difference (TD) algorithm is known to perform very well in the on-policy setting, yet is not off-policy stable. On the other hand, the gradient TD and emphatic TD algorithms are off-policy stable, but are not on-policy efficient. This paper introduces novel algorithms that are both off-policy stable and on-policy efficient by using the oblique projection method. The empirical experimental results on various domains validate the effectiveness of the proposed approach.
A Human-Centered Data-Driven Planner-Actor-Critic Architecture via Logic Programming
Sep 18, 2019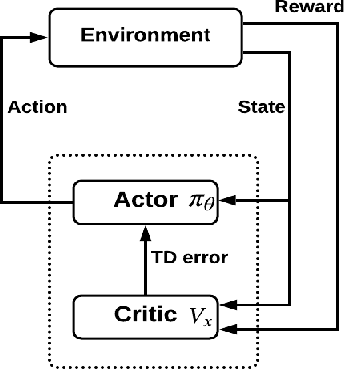
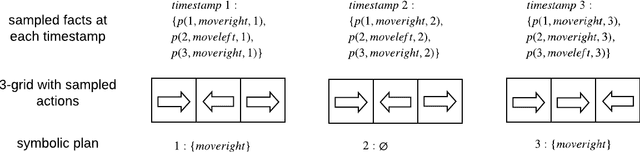
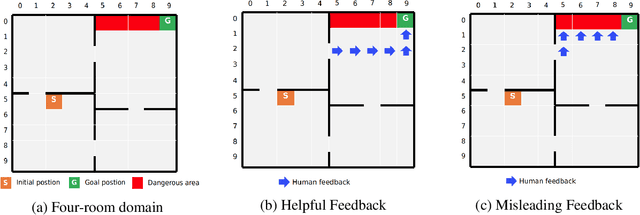
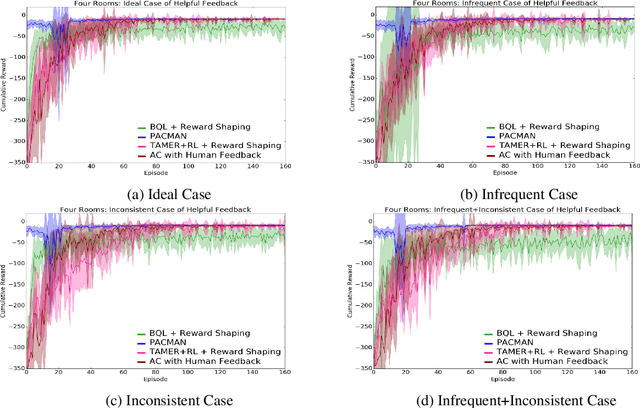
Recent successes of Reinforcement Learning (RL) allow an agent to learn policies that surpass human experts but suffers from being time-hungry and data-hungry. By contrast, human learning is significantly faster because prior and general knowledge and multiple information resources are utilized. In this paper, we propose a Planner-Actor-Critic architecture for huMAN-centered planning and learning (PACMAN), where an agent uses its prior, high-level, deterministic symbolic knowledge to plan for goal-directed actions, and also integrates the Actor-Critic algorithm of RL to fine-tune its behavior towards both environmental rewards and human feedback. This work is the first unified framework where knowledge-based planning, RL, and human teaching jointly contribute to the policy learning of an agent. Our experiments demonstrate that PACMAN leads to a significant jump-start at the early stage of learning, converges rapidly and with small variance, and is robust to inconsistent, infrequent, and misleading feedback.
* In Proceedings ICLP 2019, arXiv:1909.07646. arXiv admin note: significant text overlap with arXiv:1906.07268
PACMAN: A Planner-Actor-Critic Architecture for Human-Centered Planning and Learning
Aug 01, 2019
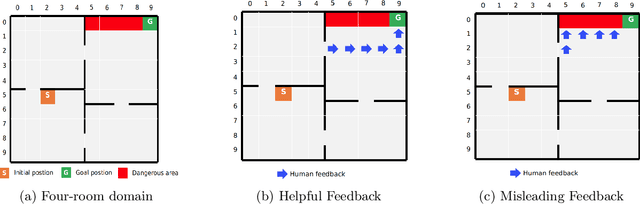
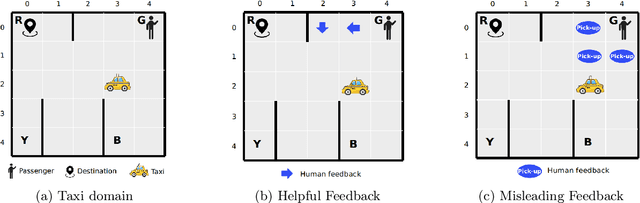
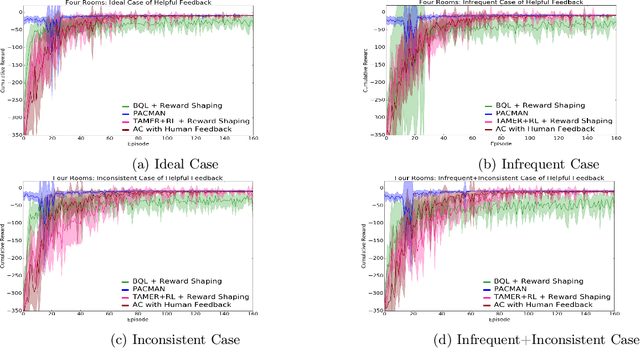
Conventional reinforcement learning (RL) allows an agent to learn policies via environmental rewards only, with a long and slow learning curve at the beginning stage. On the contrary, human learning is usually much faster because prior and general knowledge and multiple information resources are utilized. In this paper, we propose a \textbf{P}lanner-\textbf{A}ctor-\textbf{C}ritic architecture for hu\textbf{MAN}-centered planning and learning (\textbf{PACMAN}), where an agent uses its prior, high-level, deterministic symbolic knowledge to plan for goal-directed actions, while integrates Actor-Critic algorithm of RL to fine-tune its behaviors towards both environmental rewards and human feedback. This is the first unified framework where knowledge-based planning, RL, and human teaching jointly contribute to the policy learning of an agent. Our experiments demonstrate that PACMAN leads to a significant jump start at the early stage of learning, converges rapidly and with small variance, and is robust to inconsistent, infrequent and misleading feedback.
Knowledge-Based Sequential Decision-Making Under Uncertainty
May 16, 2019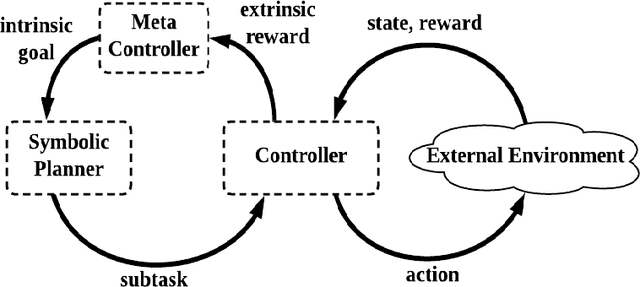
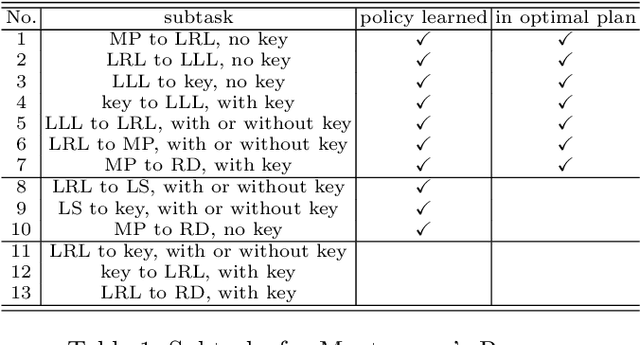
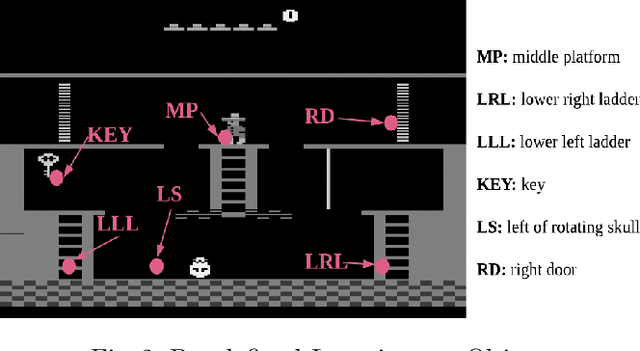
Deep reinforcement learning (DRL) algorithms have achieved great success on sequential decision-making problems, yet is criticized for the lack of data-efficiency and explainability. Especially, explainability of subtasks is critical in hierarchical decision-making since it enhances the transparency of black-box-style DRL methods and helps the RL practitioners to understand the high-level behavior of the system better. To improve the data-efficiency and explainability of DRL, declarative knowledge is introduced in this work and a novel algorithm is proposed by integrating DRL with symbolic planning. Experimental analysis on publicly available benchmarks validates the explainability of the subtasks and shows that our method can outperform the state-of-the-art approach in terms of data-efficiency.
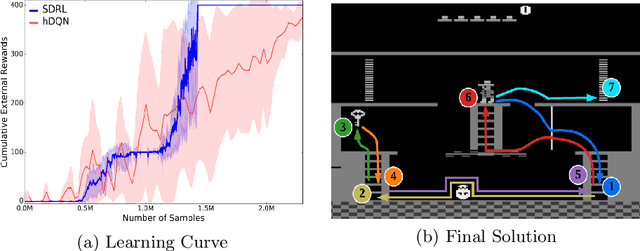
SDRL: Interpretable and Data-efficient Deep Reinforcement Learning Leveraging Symbolic Planning
Nov 05, 2018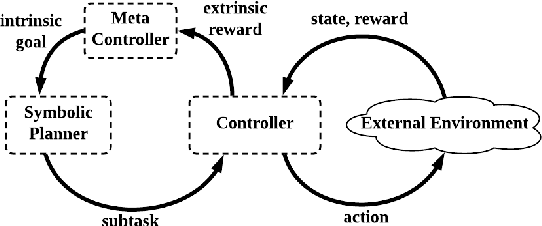

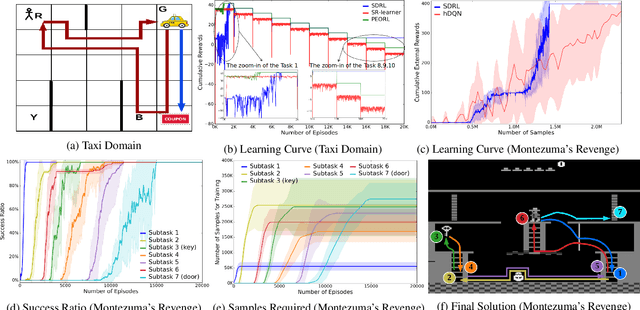
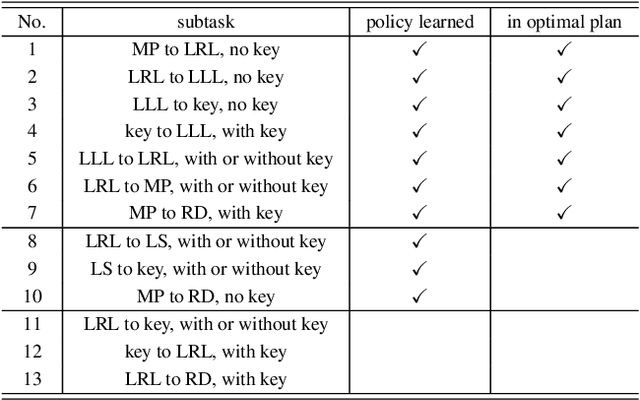
Deep reinforcement learning (DRL) has gained great success by learning directly from high-dimensional sensory inputs, yet is notorious for the lack of interpretability. Interpretability of the subtasks is critical in hierarchical decision-making as it increases the transparency of black-box-style DRL approach and helps the RL practitioners to understand the high-level behavior of the system better. In this paper, we introduce symbolic planning into DRL and propose a framework of Symbolic Deep Reinforcement Learning (SDRL) that can handle both high-dimensional sensory inputs and symbolic planning. The task-level interpretability is enabled by relating symbolic actions to options.This framework features a planner -- controller -- meta-controller architecture, which takes charge of subtask scheduling, data-driven subtask learning, and subtask evaluation, respectively. The three components cross-fertilize each other and eventually converge to an optimal symbolic plan along with the learned subtasks, bringing together the advantages of long-term planning capability with symbolic knowledge and end-to-end reinforcement learning directly from a high-dimensional sensory input. Experimental results validate the interpretability of subtasks, along with improved data efficiency compared with state-of-the-art approaches.