 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIVOINE: Instruction Tuning for Open-world Information Extraction
May 24, 2023We consider the problem of Open-world Information Extraction (Open-world IE), which extracts comprehensive entity profiles from unstructured texts. Different from the conventional closed-world setting of Information Extraction (IE), Open-world IE considers a more general situation where entities and relations could be beyond a predefined ontology. More importantly, we seek to develop a large language model (LLM) that is able to perform Open-world IE to extract desirable entity profiles characterized by (possibly fine-grained) natural language instructions. We achieve this by finetuning LLMs using instruction tuning. In particular, we construct INSTRUCTOPENWIKI, a substantial instruction tuning dataset for Open-world IE enriched with a comprehensive corpus, extensive annotations, and diverse instructions. We finetune the pretrained BLOOM models on INSTRUCTOPENWIKI and obtain PIVOINE, an LLM for Open-world IE with strong instruction-following capabilities. Our experiments demonstrate that PIVOINE significantly outperforms traditional closed-world methods and other LLM baselines, displaying impressive generalization capabilities on both unseen instructions and out-of-ontology cases. Consequently, PIVOINE emerges as a promising solution to tackle the open-world challenge in IE effectively.
CEO: Corpus-based Open-Domain Event Ontology Induction
May 22, 2023Existing event-centric NLP models often only apply to the pre-defined ontology, which significantly restricts their generalization capabilities. This paper presents CEO, a novel Corpus-based Event Ontology induction model to relax the restriction imposed by pre-defined event ontologies. Without direct supervision, CEO leverages distant supervision from available summary datasets to detect corpus-wise salient events and exploits external event knowledge to force events within a short distance to have close embeddings. Experiments on three popular event datasets show that the schema induced by CEO has better coverage and higher accuracy than previous methods. Moreover, CEO is the first event ontology induction model that can induce a hierarchical event ontology with meaningful names on eleven open-domain corpora, making the induced schema more trustworthy and easier to be further curated.
Learning Language Representations with Logical Inductive Bias
Feb 19, 2023Transformer architectures have achieved great success in solving natural language tasks, which learn strong language representations from large-scale unlabeled texts. In this paper, we seek to go further beyond and explore a new logical inductive bias for better language representation learning. Logic reasoning is known as a formal methodology to reach answers from given knowledge and facts. Inspired by such a view, we develop a novel neural architecture named FOLNet (First-Order Logic Network), to encode this new inductive bias. We construct a set of neural logic operators as learnable Horn clauses, which are further forward-chained into a fully differentiable neural architecture (FOLNet). Interestingly, we find that the self-attention module in transformers can be composed by two of our neural logic operators, which probably explains their strong reasoning performance. Our proposed FOLNet has the same input and output interfaces as other pretrained models and thus could be pretrained/finetuned by using similar losses. It also allows FOLNet to be used in a plug-and-play manner when replacing other pretrained models. With our logical inductive bias, the same set of ``logic deduction skills'' learned through pretraining are expected to be equally capable of solving diverse downstream tasks. For this reason, FOLNet learns language representations that have much stronger transfer capabilities. Experimental results on several language understanding tasks show that our pretrained FOLNet model outperforms the existing strong transformer-based approaches.
ZeroKBC: A Comprehensive Benchmark for Zero-Shot Knowledge Base Completion
Dec 06, 2022Knowledge base completion (KBC) aims to predict the missing links in knowledge graphs. Previous KBC tasks and approaches mainly focus on the setting where all test entities and relations have appeared in the training set. However, there has been limited research on the zero-shot KBC settings, where we need to deal with unseen entities and relations that emerge in a constantly growing knowledge base. In this work, we systematically examine different possible scenarios of zero-shot KBC and develop a comprehensive benchmark, ZeroKBC, that covers these scenarios with diverse types of knowledge sources. Our systematic analysis reveals several missing yet important zero-shot KBC settings. Experimental results show that canonical and state-of-the-art KBC systems cannot achieve satisfactory performance on this challenging benchmark. By analyzing the strength and weaknesses of these systems on solving ZeroKBC, we further present several important observations and promising future directions.
Knowledge-in-Context: Towards Knowledgeable Semi-Parametric Language Models
Oct 28, 2022Fully-parametric language models generally require a huge number of model parameters to store the necessary knowledge for solving multiple natural language tasks in zero/few-shot settings. In addition, it is hard to adapt to the evolving world knowledge without the costly model re-training. In this paper, we develop a novel semi-parametric language model architecture, Knowledge-in-Context (KiC), which empowers a parametric text-to-text language model with a knowledge-rich external memory. Specifically, the external memory contains six different types of knowledge: entity, dictionary, commonsense, event, script, and causality knowledge. For each input instance, the KiC model adaptively selects a knowledge type and retrieves the most helpful pieces of knowledge. The input instance along with its knowledge augmentation is fed into a text-to-text model (e.g., T5) to generate the output answer, where both the input and the output are in natural language forms after prompting. Interestingly, we find that KiC can be identified as a special mixture-of-experts (MoE) model, where the knowledge selector plays the role of a router that is used to determine the sequence-to-expert assignment in MoE. This key observation inspires us to develop a novel algorithm for training KiC with an instance-adaptive knowledge selector. As a knowledge-rich semi-parametric language model, KiC only needs a much smaller parametric part to achieve superior zero-shot performance on unseen tasks. By evaluating on 40+ different tasks, we show that KiC_Large with 770M parameters easily outperforms large language models (LMs) that are 4-39x larger by a large margin. We also demonstrate that KiC exhibits emergent abilities at a much smaller model scale compared to the fully-parametric models.
Explanations from Large Language Models Make Small Reasoners Better
Oct 13, 2022
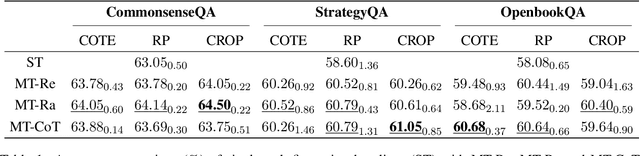
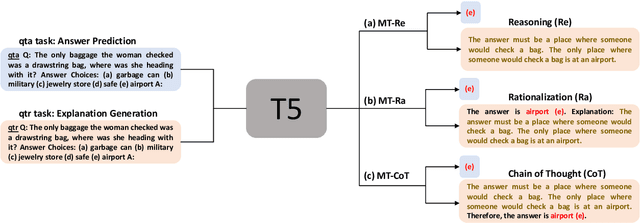
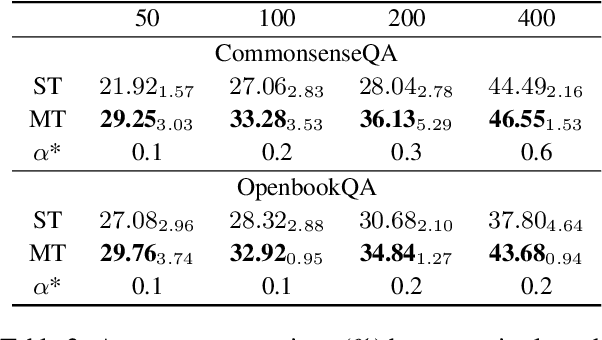
Integrating free-text explanations to in-context learning of large language models (LLM) is shown to elicit strong reasoning capabilities along with reasonable explanations. In this paper, we consider the problem of leveraging the explanations generated by LLM to improve the training of small reasoners, which are more favorable in real-production deployment due to their low cost. We systematically explore three explanation generation approaches from LLM and utilize a multi-task learning framework to facilitate small models to acquire strong reasoning power together with explanation generation capabilities. Experiments on multiple reasoning tasks show that our method can consistently and significantly outperform finetuning baselines across different settings, and even perform better than finetuning/prompting a 60x larger GPT-3 (175B) model by up to 9.5% in accuracy. As a side benefit, human evaluation further shows that our method can generate high-quality explanations to justify its predictions, moving towards the goal of explainable AI.
Join-Chain Network: A Logical Reasoning View of the Multi-head Attention in Transformer
Oct 07, 2022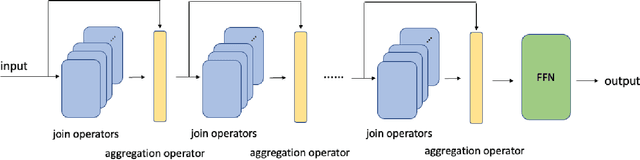
Developing neural architectures that are capable of logical reasoning has become increasingly important for a wide range of applications (e.g., natural language processing). Towards this grand objective, we propose a symbolic reasoning architecture that chains many join operators together to model output logical expressions. In particular, we demonstrate that such an ensemble of join-chains can express a broad subset of ''tree-structured'' first-order logical expressions, named FOET, which is particularly useful for modeling natural languages. To endow it with differentiable learning capability, we closely examine various neural operators for approximating the symbolic join-chains. Interestingly, we find that the widely used multi-head self-attention module in transformer can be understood as a special neural operator that implements the union bound of the join operator in probabilistic predicate space. Our analysis not only provides a new perspective on the mechanism of the pretrained models such as BERT for natural language understanding but also suggests several important future improvement directions.
Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks
Oct 01, 2022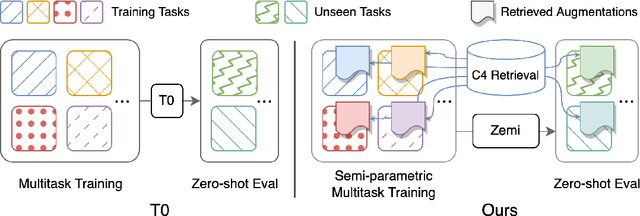
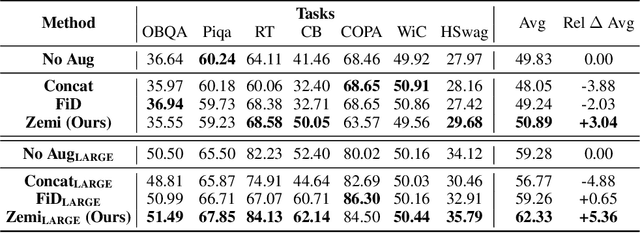
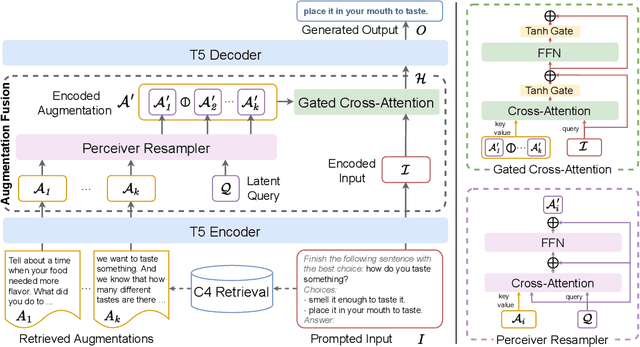
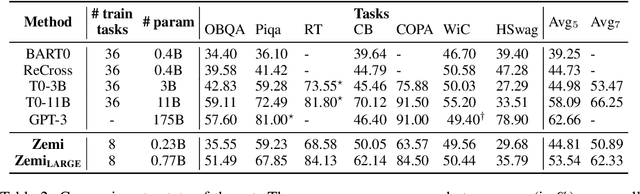
Although large language models have achieved impressive zero-shot ability, the huge model size generally incurs high cost. Recently, semi-parametric language models, which augment a smaller language model with an external retriever, have demonstrated promising language modeling capabilities. However, it remains unclear whether such semi-parametric language models can perform competitively well as their fully-parametric counterparts on zero-shot generalization to downstream tasks. In this work, we introduce $\text{Zemi}$, a zero-shot semi-parametric language model. To our best knowledge, this is the first semi-parametric language model that can demonstrate strong zero-shot performance on a wide range of held-out unseen tasks. We train $\text{Zemi}$ with a novel semi-parametric multitask prompted training paradigm, which shows significant improvement compared with the parametric multitask training as proposed by T0. Specifically, we augment the multitask training and zero-shot evaluation with retrieval from a large-scale task-agnostic unlabeled corpus. In order to incorporate multiple potentially noisy retrieved augmentations, we further propose a novel $\text{augmentation fusion}$ module leveraging perceiver resampler and gated cross-attention. Notably, our proposed $\text{Zemi}_\text{LARGE}$ outperforms T0-3B by 16% on all seven evaluation tasks while being 3.9x smaller in model size.
Blessing of Class Diversity in Pre-training
Sep 12, 2022
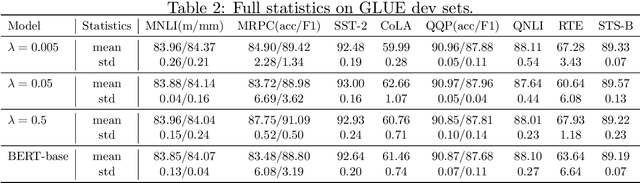
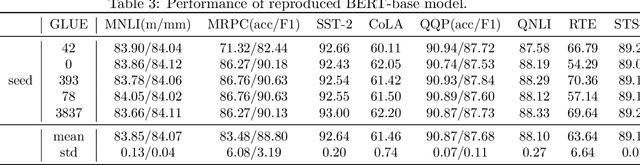
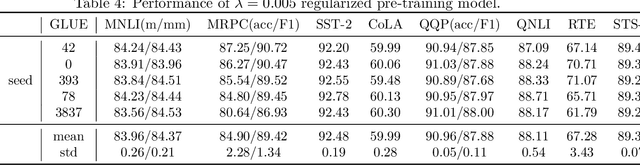
This paper presents a new statistical analysis aiming to explain the recent superior achievements of the pre-training techniques in natural language processing (NLP). We prove that when the classes of the pre-training task (e.g., different words in the masked language model task) are sufficiently diverse, in the sense that the least singular value of the last linear layer in pre-training (denoted as $\tilde{\nu}$) is large, then pre-training can significantly improve the sample efficiency of downstream tasks. Specially, we show the transfer learning excess risk enjoys an $O\left(\frac{1}{\tilde{\nu} \sqrt{n}}\right)$ rate, in contrast to the $O\left(\frac{1}{\sqrt{m}}\right)$ rate in the standard supervised learning. Here, $n$ is the number of pre-training data and $m$ is the number of data in the downstream task, and typically $n \gg m$. Our proof relies on a vector-form Rademacher complexity chain rule for disassembling composite function classes and a modified self-concordance condition. These techniques can be of independent interest.
C-MORE: Pretraining to Answer Open-Domain Questions by Consulting Millions of References
Mar 22, 2022
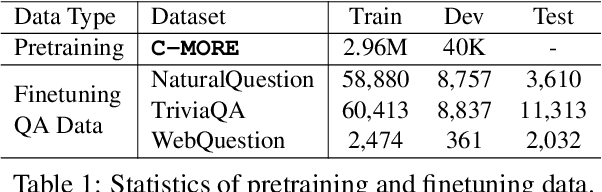
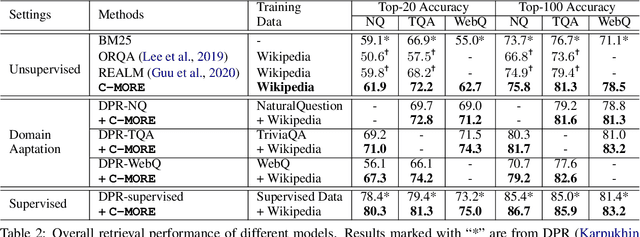
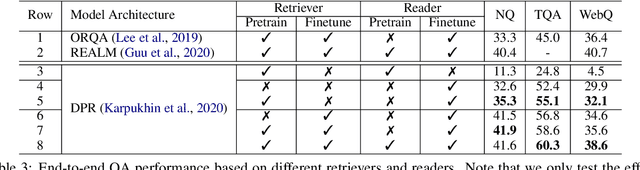
We consider the problem of pretraining a two-stage open-domain question answering (QA) system (retriever + reader) with strong transfer capabilities. The key challenge is how to construct a large amount of high-quality question-answer-context triplets without task-specific annotations. Specifically, the triplets should align well with downstream tasks by: (i) covering a wide range of domains (for open-domain applications), (ii) linking a question to its semantically relevant context with supporting evidence (for training the retriever), and (iii) identifying the correct answer in the context (for training the reader). Previous pretraining approaches generally fall short of one or more of these requirements. In this work, we automatically construct a large-scale corpus that meets all three criteria by consulting millions of references cited within Wikipedia. The well-aligned pretraining signals benefit both the retriever and the reader significantly. Our pretrained retriever leads to 2%-10% absolute gains in top-20 accuracy. And with our pretrained reader, the entire system improves by up to 4% in exact match.