 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch What You Want: Barrier Panelty NAS for Mixed Precision Quantization
Jul 20, 2020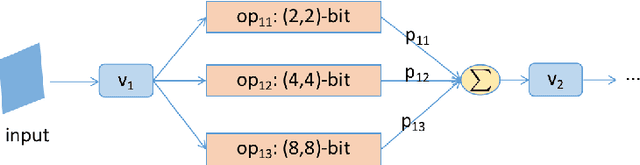
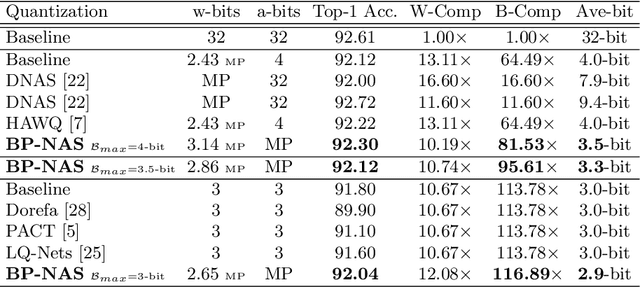
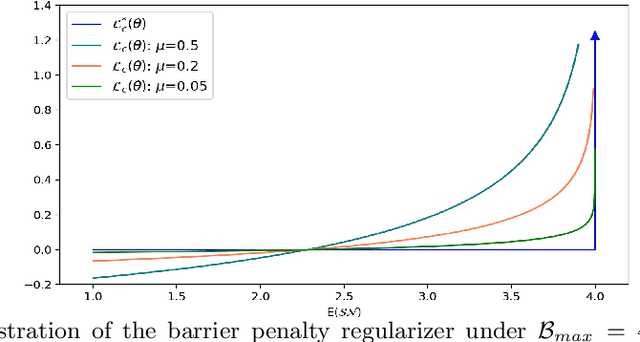
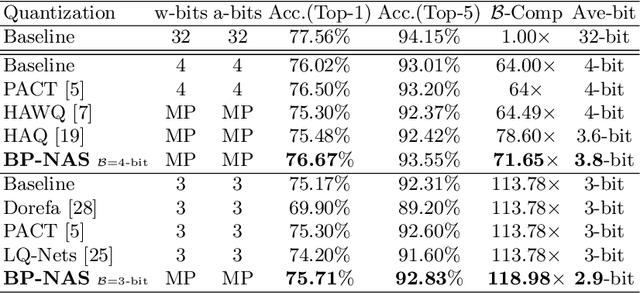
Emergent hardwares can support mixed precision CNN models inference that assign different bitwidths for different layers. Learning to find an optimal mixed precision model that can preserve accuracy and satisfy the specific constraints on model size and computation is extremely challenge due to the difficult in training a mixed precision model and the huge space of all possible bit quantizations. In this paper, we propose a novel soft Barrier Penalty based NAS (BP-NAS) for mixed precision quantization, which ensures all the searched models are inside the valid domain defined by the complexity constraint, thus could return an optimal model under the given constraint by conducting search only one time. The proposed soft Barrier Penalty is differentiable and can impose very large losses to those models outside the valid domain while almost no punishment for models inside the valid domain, thus constraining the search only in the feasible domain. In addition, a differentiable Prob-1 regularizer is proposed to ensure learning with NAS is reasonable. A distribution reshaping training strategy is also used to make training more stable. BP-NAS sets new state of the arts on both classification (Cifar-10, ImageNet) and detection (COCO), surpassing all the efficient mixed precision methods designed manually and automatically. Particularly, BP-NAS achieves higher mAP (up to 2.7\% mAP improvement) together with lower bit computation cost compared with the existing best mixed precision model on COCO detection.
TPNet: Trajectory Proposal Network for Motion Prediction
Apr 26, 2020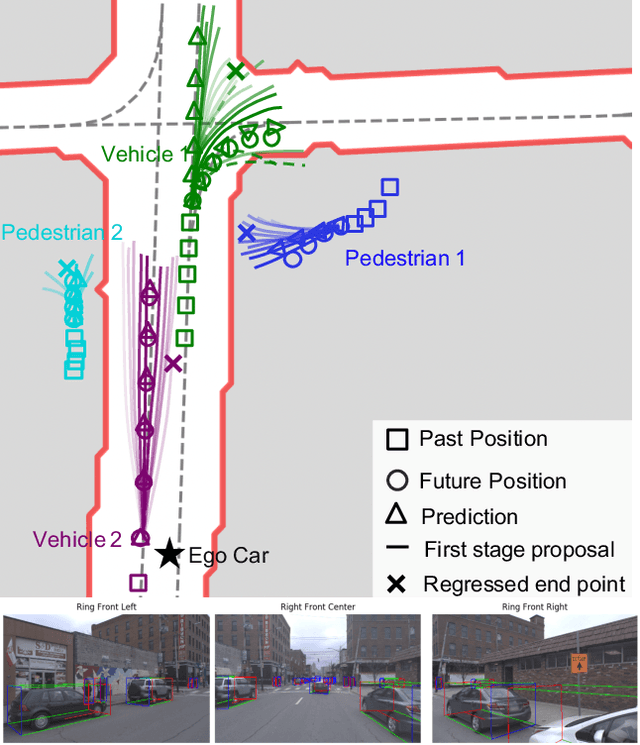
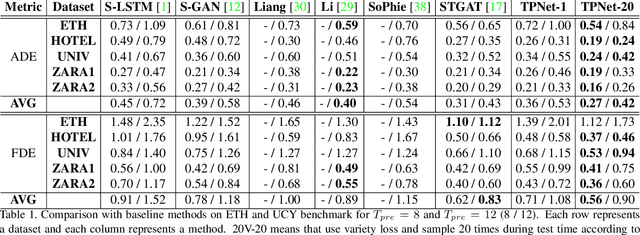
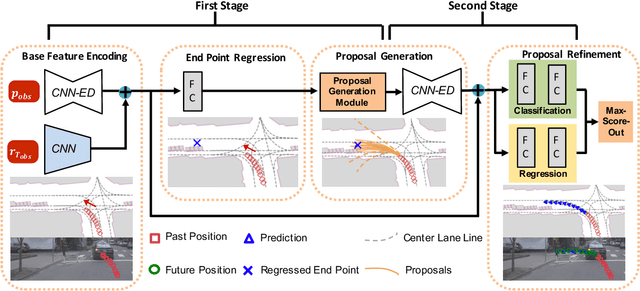
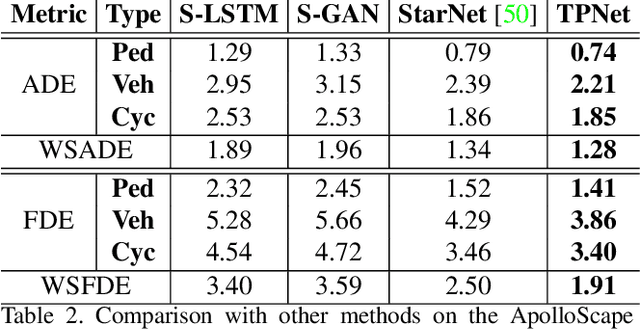
Making accurate motion prediction of the surrounding traffic agents such as pedestrians, vehicles, and cyclists is crucial for autonomous driving. Recent data-driven motion prediction methods have attempted to learn to directly regress the exact future position or its distribution from massive amount of trajectory data. However, it remains difficult for these methods to provide multimodal predictions as well as integrate physical constraints such as traffic rules and movable areas. In this work we propose a novel two-stage motion prediction framework, Trajectory Proposal Network (TPNet). TPNet first generates a candidate set of future trajectories as hypothesis proposals, then makes the final predictions by classifying and refining the proposals which meets the physical constraints. By steering the proposal generation process, safe and multimodal predictions are realized. Thus this framework effectively mitigates the complexity of motion prediction problem while ensuring the multimodal output. Experiments on four large-scale trajectory prediction datasets, i.e. the ETH, UCY, Apollo and Argoverse datasets, show that TPNet achieves the state-of-the-art results both quantitatively and qualitatively.
Uncertainty-Aware Consistency Regularization for Cross-Domain Semantic Segmentation
Apr 19, 2020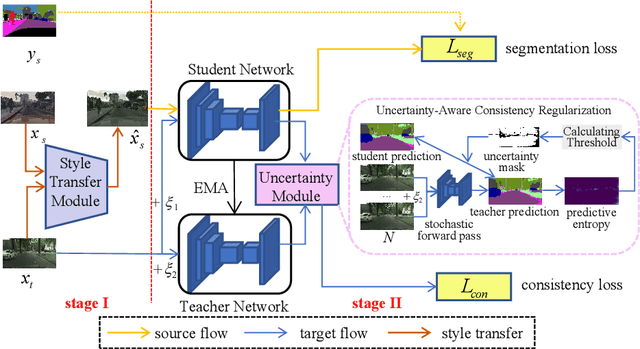
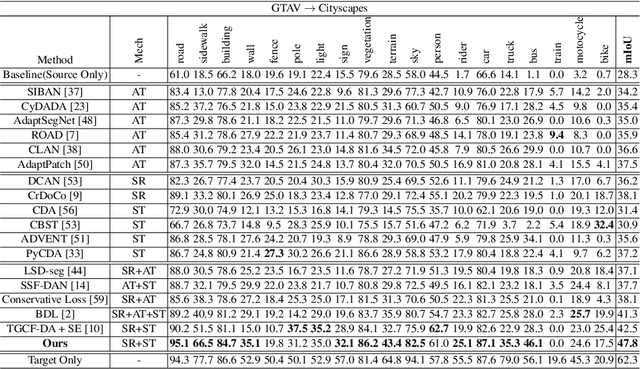
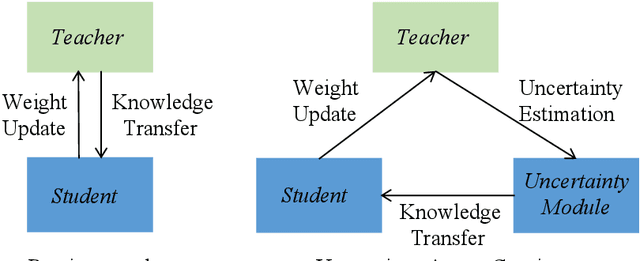
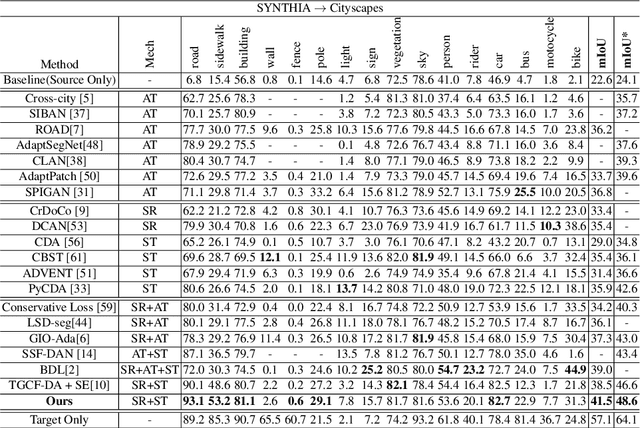
Unsupervised domain adaptation (UDA) aims to adapt existing models of the source domain to a new target domain with only unlabeled data. The main challenge to UDA lies in how to reduce the domain gap between the source domain and the target domain. Existing approaches of cross-domain semantic segmentation usually employ a consistency regularization on the target prediction of student model and teacher model respectively under different perturbations. However, previous works do not consider the reliability of the predicted target samples, which could harm the learning process by generating unreasonable guidance for the student model. In this paper, we propose an uncertainty-aware consistency regularization method to tackle this issue for semantic segmentation. By exploiting the latent uncertainty information of the target samples, more meaningful and reliable knowledge from the teacher model would be transferred to the student model. The experimental evaluation has shown that the proposed method outperforms the state-of-the-art methods by around $3\% \sim 5\%$ improvement on two domain adaptation benchmarks, i.e. GTAV $\rightarrow $ Cityscapes and SYNTHIA $\rightarrow $ Cityscapes.
Semi-Supervised Semantic Segmentation via Dynamic Self-Training and Class-Balanced Curriculum
Apr 18, 2020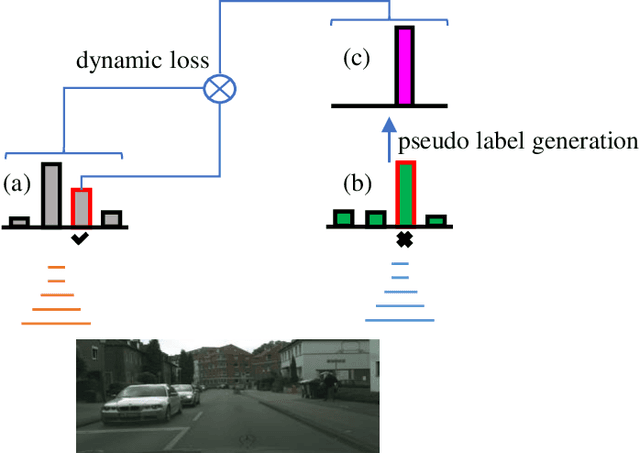

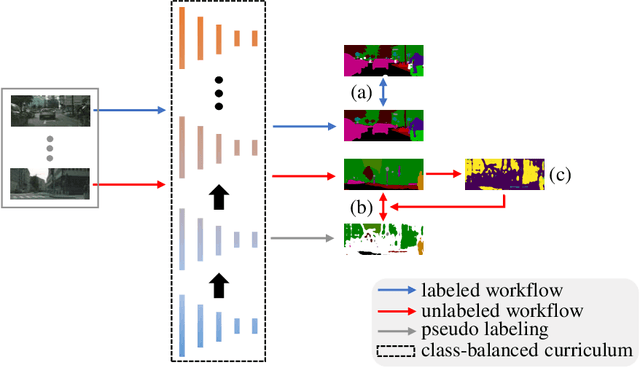
In this work, we propose a novel and concise approach for semi-supervised semantic segmentation. The major challenge of this task lies in how to exploit unlabeled data efficiently and thoroughly. Previous state-of-the-art methods utilize unlabeled data by GAN-based self-training or consistency regularization. However, these methods either suffer from noisy self-supervision and class-imbalance, resulting in a low unlabeled data utilization rate, or do not consider the apparent link between self-training and consistency regularization. Our method, Dynamic Self-Training and Class-Balanced Curriculum (DST-CBC), exploits inter-model disagreement by prediction confidence to construct a dynamic loss robust against pseudo label noise, enabling it to extend pseudo labeling to a class-balanced curriculum learning process. While we further show that our method implicitly includes consistency regularization. Thus, DST-CBC not only exploits unlabeled data efficiently, but also thoroughly utilizes $all$ unlabeled data. Without using adversarial training or any kind of modification to the network architecture, DST-CBC outperforms existing methods on different datasets across all labeled ratios, bringing semi-supervised learning yet another step closer to match the performance of fully-supervised learning for semantic segmentation. Our code and data splits are available at: https://github.com/voldemortX/DST-CBC .
AdaStereo: A Simple and Efficient Approach for Adaptive Stereo Matching
Apr 09, 2020
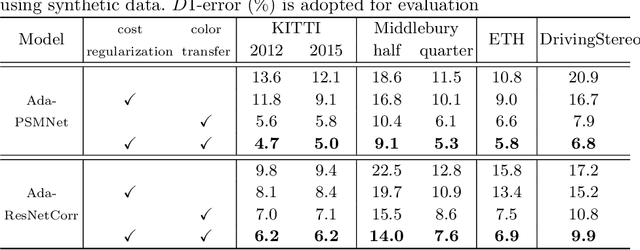
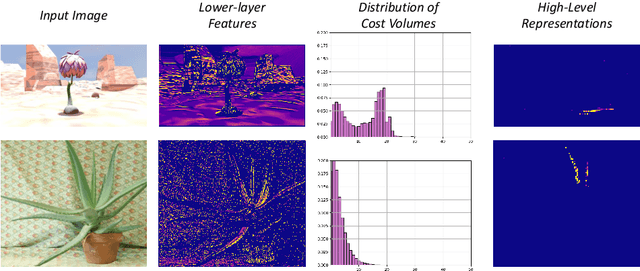
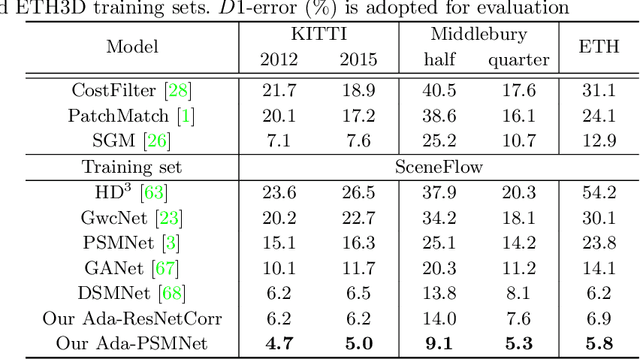
In this paper, we attempt to solve the domain adaptation problem for deep stereo matching networks. Instead of resorting to black-box structures or layers to find implicit connections across domains, we focus on investigating adaptation gaps for stereo matching. By visual inspections and extensive experiments, we conclude that low-level aligning is crucial for adaptive stereo matching, since main gaps across domains lie in the inconsistent input color and cost volume distributions. Correspondingly, we design a bottom-up domain adaptation method, in which two particular approaches are proposed, i.e. color transfer and cost regularization, that can be easily integrated into existing stereo matching models. The color transfer enables transferring a large amount of synthetic data to the same color spaces with target domains during training. The cost regularization can further constrain both the lower-layer features and cost volumes to domain-invariant distributions. Although our proposed strategies are simple and have no parameters to learn, they do improve the generalization ability of existing disparity networks by a large margin. We conduct experiments across multiple datasets, including Scene Flow, KITTI, Middlebury, ETH3D and DrivingStereo. Without whistles and bells, our synthetic-data pretrained models achieve state-of-the-art cross-domain performance compared to previous domain-invariant methods, even outperform state-of-the-art disparity networks fine-tuned with target domain ground-truths on multiple stereo matching benchmarks.
Temporal Pyramid Network for Action Recognition
Apr 07, 2020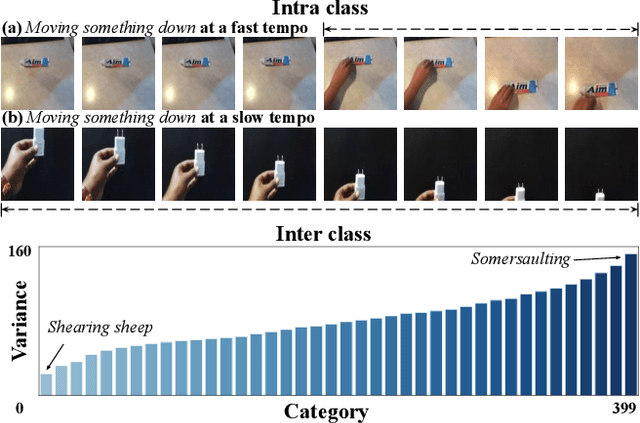
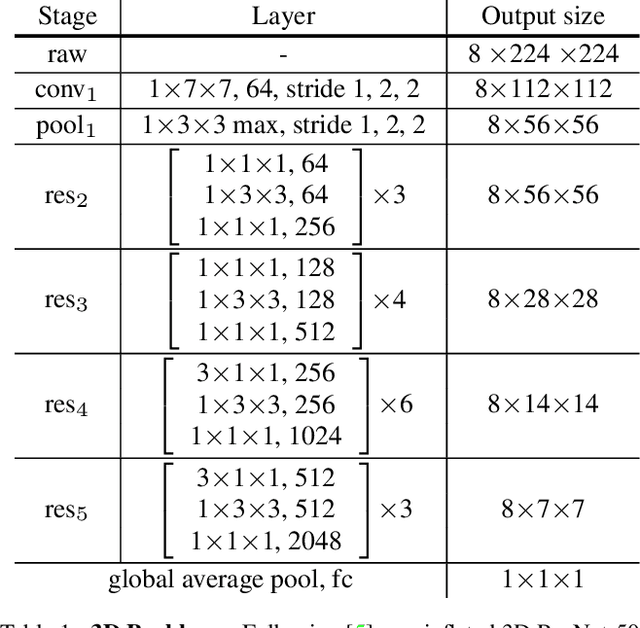
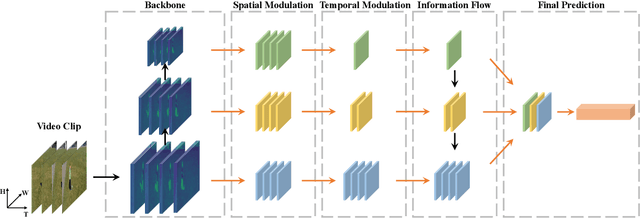
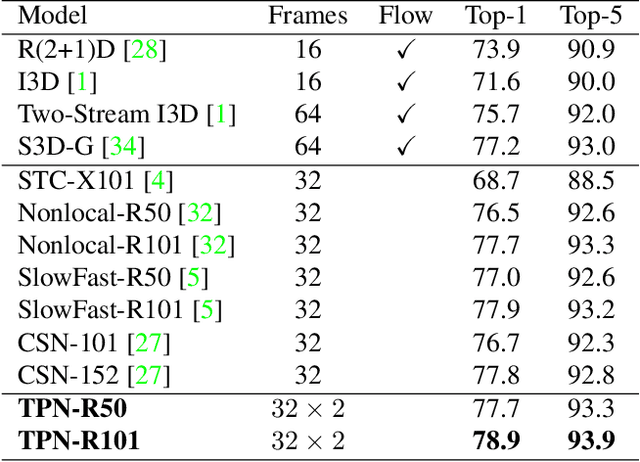
Visual tempo characterizes the dynamics and the temporal scale of an action. Modeling such visual tempos of different actions facilitates their recognition. Previous works often capture the visual tempo through sampling raw videos at multiple rates and constructing an input-level frame pyramid, which usually requires a costly multi-branch network to handle. In this work we propose a generic Temporal Pyramid Network (TPN) at the feature-level, which can be flexibly integrated into 2D or 3D backbone networks in a plug-and-play manner. Two essential components of TPN, the source of features and the fusion of features, form a feature hierarchy for the backbone so that it can capture action instances at various tempos. TPN also shows consistent improvements over other challenging baselines on several action recognition datasets. Specifically, when equipped with TPN, the 3D ResNet-50 with dense sampling obtains a 2% gain on the validation set of Kinetics-400. A further analysis also reveals that TPN gains most of its improvements on action classes that have large variances in their visual tempos, validating the effectiveness of TPN.
SSN: Shape Signature Networks for Multi-class Object Detection from Point Clouds
Apr 06, 2020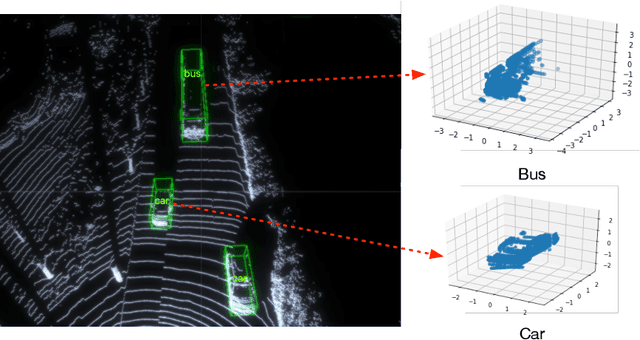
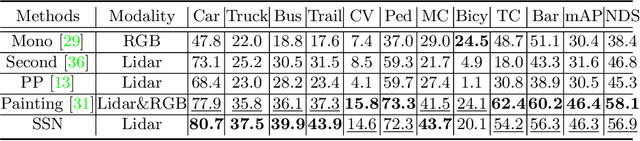
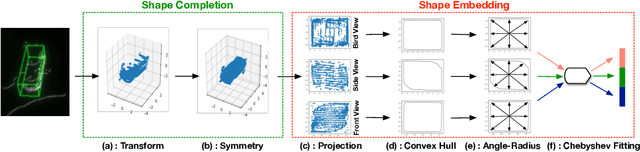
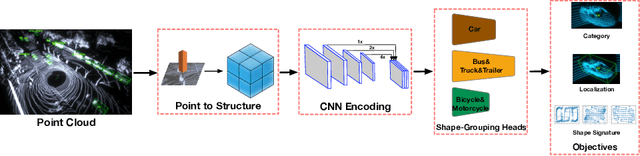
Multi-class 3D object detection aims to localize and classify objects of multiple categories from point clouds. Due to the nature of point clouds, i.e. unstructured, sparse and noisy, some features benefit-ting multi-class discrimination are underexploited, such as shape information. In this paper, we propose a novel 3D shape signature to explore the shape information from point clouds. By incorporating operations of symmetry, convex hull and chebyshev fitting, the proposed shape sig-nature is not only compact and effective but also robust to the noise, which serves as a soft constraint to improve the feature capability of multi-class discrimination. Based on the proposed shape signature, we develop the shape signature networks (SSN) for 3D object detection, which consist of pyramid feature encoding part, shape-aware grouping heads and explicit shape encoding objective. Experiments show that the proposed method performs remarkably better than existing methods on two large-scale datasets. Furthermore, our shape signature can act as a plug-and-play component and ablation study shows its effectiveness and good scalability
DSNAS: Direct Neural Architecture Search without Parameter Retraining
Feb 21, 2020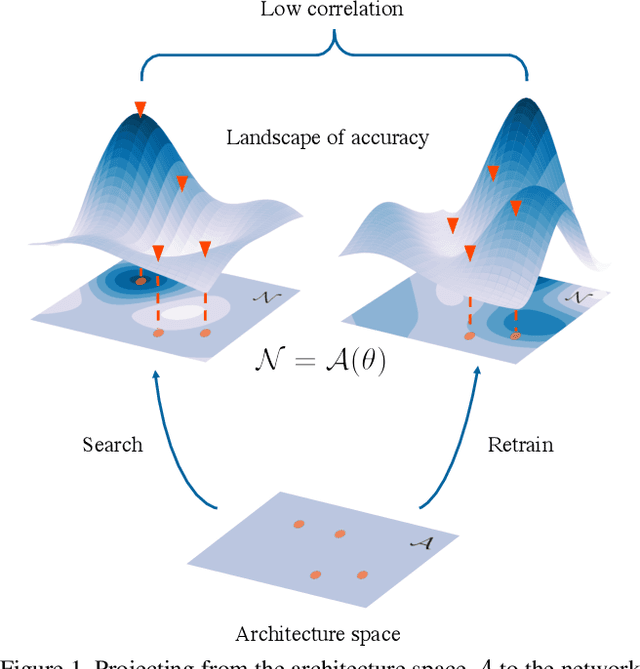

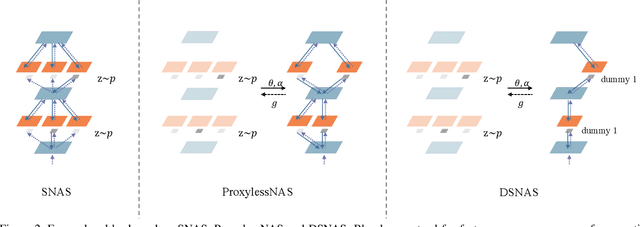
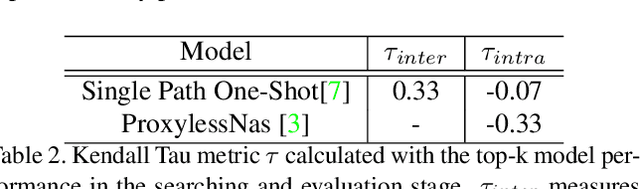
If NAS methods are solutions, what is the problem? Most existing NAS methods require two-stage parameter optimization. However, performance of the same architecture in the two stages correlates poorly. In this work, we propose a new problem definition for NAS, task-specific end-to-end, based on this observation. We argue that given a computer vision task for which a NAS method is expected, this definition can reduce the vaguely-defined NAS evaluation to i) accuracy of this task and ii) the total computation consumed to finally obtain a model with satisfying accuracy. Seeing that most existing methods do not solve this problem directly, we propose DSNAS, an efficient differentiable NAS framework that simultaneously optimizes architecture and parameters with a low-biased Monte Carlo estimate. Child networks derived from DSNAS can be deployed directly without parameter retraining. Comparing with two-stage methods, DSNAS successfully discovers networks with comparable accuracy (74.4%) on ImageNet in 420 GPU hours, reducing the total time by more than 34%.
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
Dec 31, 2019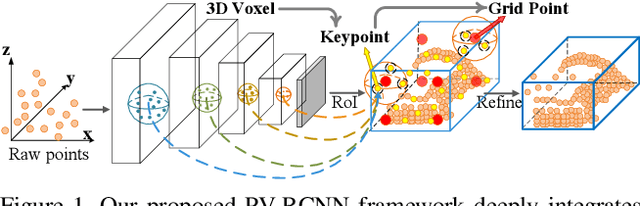
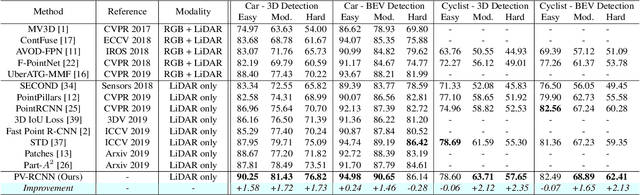
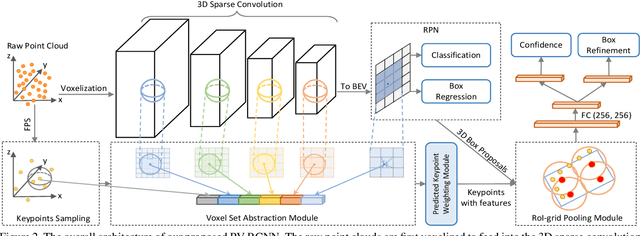
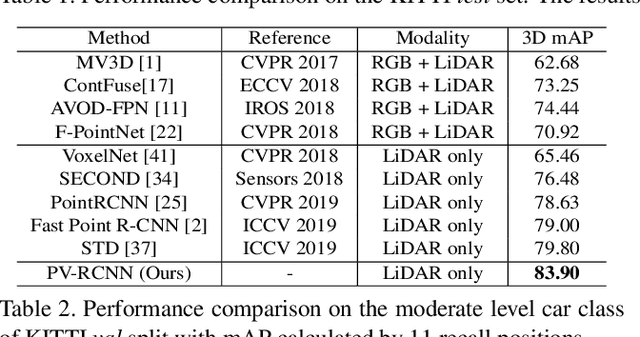
We present a novel and high-performance 3D object detection framework, named PointVoxel-RCNN (PV-RCNN), for accurate 3D object detection from point clouds. Our proposed method deeply integrates both 3D voxel Convolutional Neural Network (CNN) and PointNet-based set abstraction to learn more discriminative point cloud features. It takes advantages of efficient learning and high-quality proposals of the 3D voxel CNN and the flexible receptive fields of the PointNet-based networks. Specifically, the proposed framework summarizes the 3D scene with a 3D voxel CNN into a small set of keypoints via a novel voxel set abstraction module to save follow-up computations and also to encode representative scene features. Given the high-quality 3D proposals generated by the voxel CNN, the RoI-grid pooling is proposed to abstract proposal-specific features from the keypoints to the RoI-grid points via keypoint set abstraction with multiple receptive fields. Compared with conventional pooling operations, the RoI-grid feature points encode much richer context information for accurately estimating object confidences and locations. Extensive experiments on both the KITTI dataset and the Waymo Open dataset show that our proposed PV-RCNN surpasses state-of-the-art 3D detection methods with remarkable margins by using only point clouds.
Learning Depth-Guided Convolutions for Monocular 3D Object Detection
Dec 13, 2019
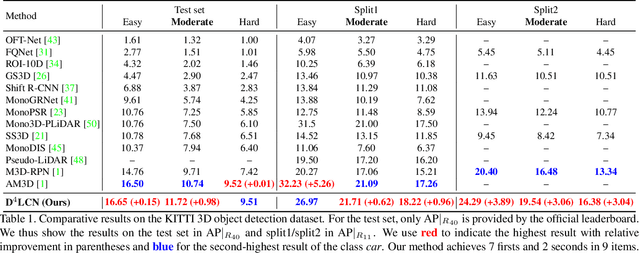
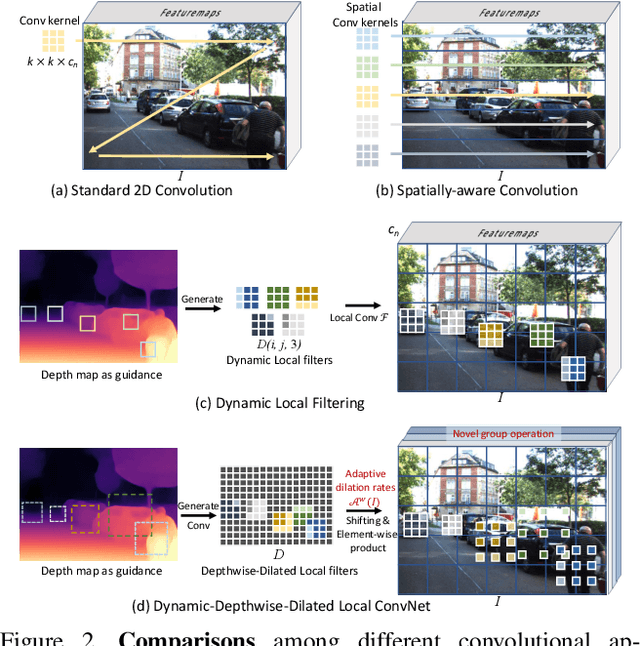
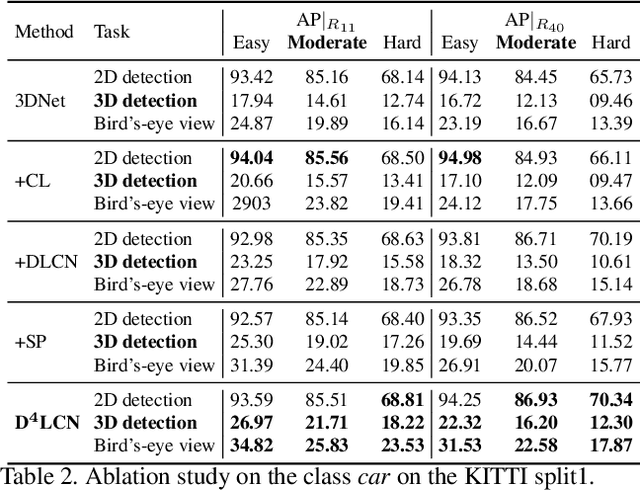
3D object detection from a single image without LiDAR is a challenging task due to the lack of accurate depth information. Conventional 2D convolutions are unsuitable for this task because they fail to capture local object and its scale information, which are vital for 3D object detection. To better represent 3D structure, prior arts typically transform depth maps estimated from 2D images into a pseudo-LiDAR representation, and then apply existing 3D point-cloud based object detectors. However, their results depend heavily on the accuracy of the estimated depth maps, resulting in suboptimal performance. In this work, instead of using pseudo-LiDAR representation, we improve the fundamental 2D fully convolutions by proposing a new local convolutional network (LCN), termed Depth-guided Dynamic-Depthwise-Dilated LCN (D$^4$LCN), where the filters and their receptive fields can be automatically learned from image-based depth maps, making different pixels of different images have different filters. D$^4$LCN overcomes the limitation of conventional 2D convolutions and narrows the gap between image representation and 3D point cloud representation. Extensive experiments show that D$^4$LCN outperforms existing works by large margins. For example, the relative improvement of D$^4$LCN against the state-of-the-art on KITTI is 9.1\% in the moderate setting. The code is available at https://github.com/dingmyu/D4LCN.