 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Semantic Segmentation via Dynamic Self-Training and Class-Balanced Curriculum
Paper and Code
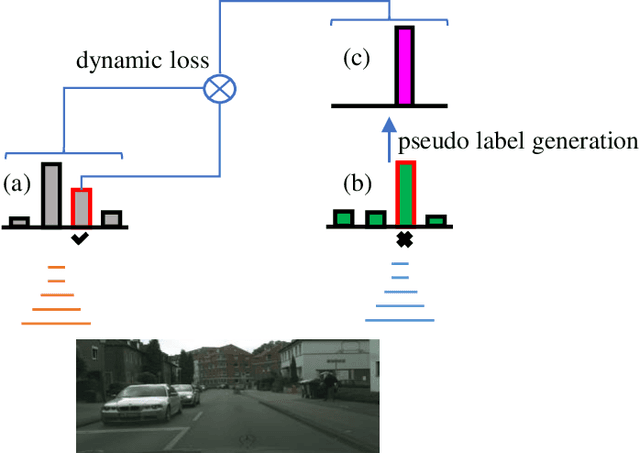

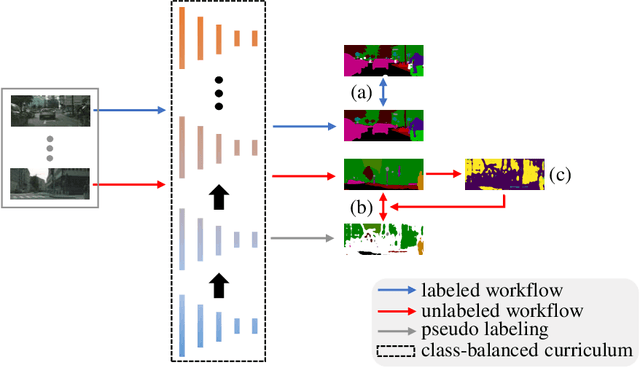
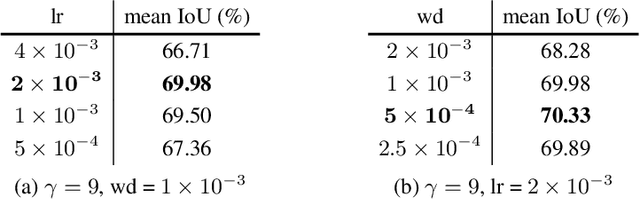
In this work, we propose a novel and concise approach for semi-supervised semantic segmentation. The major challenge of this task lies in how to exploit unlabeled data efficiently and thoroughly. Previous state-of-the-art methods utilize unlabeled data by GAN-based self-training or consistency regularization. However, these methods either suffer from noisy self-supervision and class-imbalance, resulting in a low unlabeled data utilization rate, or do not consider the apparent link between self-training and consistency regularization. Our method, Dynamic Self-Training and Class-Balanced Curriculum (DST-CBC), exploits inter-model disagreement by prediction confidence to construct a dynamic loss robust against pseudo label noise, enabling it to extend pseudo labeling to a class-balanced curriculum learning process. While we further show that our method implicitly includes consistency regularization. Thus, DST-CBC not only exploits unlabeled data efficiently, but also thoroughly utilizes $all$ unlabeled data. Without using adversarial training or any kind of modification to the network architecture, DST-CBC outperforms existing methods on different datasets across all labeled ratios, bringing semi-supervised learning yet another step closer to match the performance of fully-supervised learning for semantic segmentation. Our code and data splits are available at: https://github.com/voldemortX/DST-CBC .