 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Multimodal Reasoning with MCTS-Automated Structured Thinking
Feb 04, 2025



Multimodal large language models (MLLMs) exhibit impressive capabilities but still face challenges in complex visual reasoning. While recent efforts attempt to enhance MLLMs' reasoning by incorporating OpenAI o1-like structured thinking through explicit search structures or teacher-guided distillation, they often struggle to balance performance and efficiency. A critical limitation is their heavy reliance on extensive data and search spaces, resulting in low-efficiency implicit insight extraction and data utilization. To address this, we propose AStar, an Automated Structured thinking paradigm for multimodal reasoning via Monte Carlo Tree Search (MCTS). AStar automatically derives high-level cognitive reasoning patterns from limited data using MCTS-powered hierarchical structures. Building on these explicit patterns, we design a unified reasoning framework that seamlessly integrates models' internal reasoning capabilities and external reasoning guidelines, enabling efficient inference with minimal tree iterations. This novel paradigm strikes a compelling balance between performance and efficiency. Extensive experiments demonstrate AStar's effectiveness, achieving superior accuracy (54.0$\%$) on the MathVerse benchmark with a 7B backbone, surpassing GPT-4o (50.2$\%$) while maintaining substantial data and computational efficiency.
DReSS: Data-driven Regularized Structured Streamlining for Large Language Models
Jan 29, 2025



Large language models (LLMs) have achieved significant progress across various domains, but their increasing scale results in high computational and memory costs. Recent studies have revealed that LLMs exhibit sparsity, providing the potential to reduce model size through pruning techniques. However, existing pruning methods typically follow a prune-then-finetune paradigm. Since the pruned components still contain valuable information, their direct removal often leads to irreversible performance degradation, imposing a substantial computational burden to recover performance during finetuning. In this paper, we propose a novel paradigm that first applies regularization, then prunes, and finally finetunes. Based on this paradigm, we introduce DReSS, a simple and effective Data-driven Regularized Structured Streamlining method for LLMs. By leveraging a small amount of data to regularize the components to be pruned, DReSS explicitly transfers the important information to the remaining parts of the model in advance. Compared to direct pruning, this can reduce the information loss caused by parameter removal, thereby enhancing its language modeling capabilities. Experimental results demonstrate that DReSS significantly outperforms existing pruning methods even under extreme pruning ratios, significantly reducing latency and increasing throughput.
MTPareto: A MultiModal Targeted Pareto Framework for Fake News Detection
Jan 12, 2025Multimodal fake news detection is essential for maintaining the authenticity of Internet multimedia information. Significant differences in form and content of multimodal information lead to intensified optimization conflicts, hindering effective model training as well as reducing the effectiveness of existing fusion methods for bimodal. To address this problem, we propose the MTPareto framework to optimize multimodal fusion, using a Targeted Pareto(TPareto) optimization algorithm for fusion-level-specific objective learning with a certain focus. Based on the designed hierarchical fusion network, the algorithm defines three fusion levels with corresponding losses and implements all-modal-oriented Pareto gradient integration for each. This approach accomplishes superior multimodal fusion by utilizing the information obtained from intermediate fusion to provide positive effects to the entire process. Experiment results on FakeSV and FVC datasets show that the proposed framework outperforms baselines and the TPareto optimization algorithm achieves 2.40% and 1.89% accuracy improvement respectively.
BSDB-Net: Band-Split Dual-Branch Network with Selective State Spaces Mechanism for Monaural Speech Enhancement
Dec 26, 2024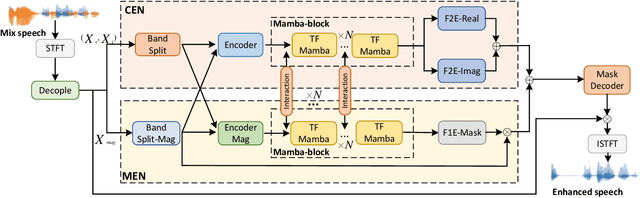
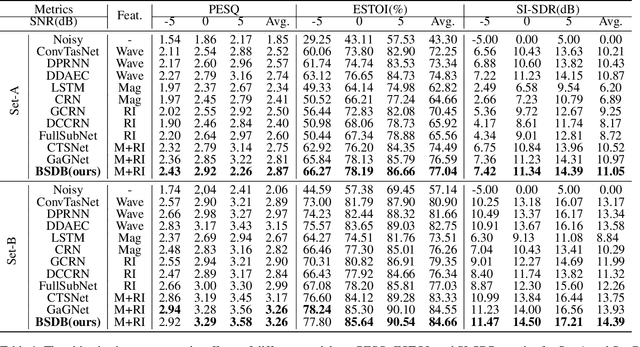
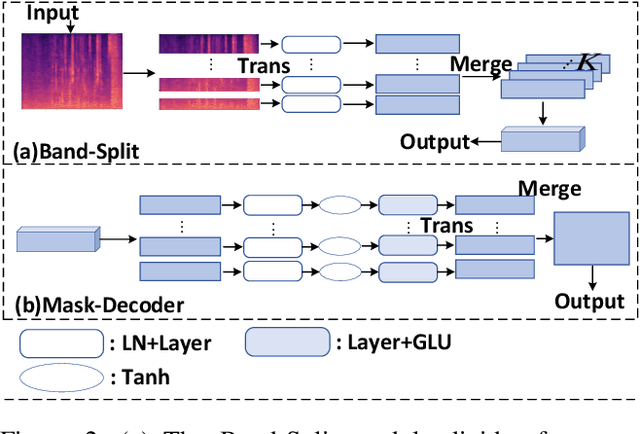
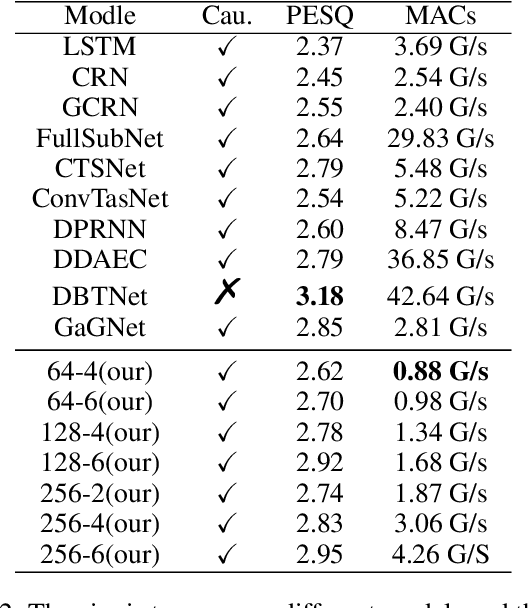
Although the complex spectrum-based speech enhancement(SE) methods have achieved significant performance, coupling amplitude and phase can lead to a compensation effect, where amplitude information is sacrificed to compensate for the phase that is harmful to SE. In addition, to further improve the performance of SE, many modules are stacked onto SE, resulting in increased model complexity that limits the application of SE. To address these problems, we proposed a dual-path network based on compressed frequency using Mamba. First, we extract amplitude and phase information through parallel dual branches. This approach leverages structured complex spectra to implicitly capture phase information and solves the compensation effect by decoupling amplitude and phase, and the network incorporates an interaction module to suppress unnecessary parts and recover missing components from the other branch. Second, to reduce network complexity, the network introduces a band-split strategy to compress the frequency dimension. To further reduce complexity while maintaining good performance, we designed a Mamba-based module that models the time and frequency dimensions under linear complexity. Finally, compared to baselines, our model achieves an average 8.3 times reduction in computational complexity while maintaining superior performance. Furthermore, it achieves a 25 times reduction in complexity compared to transformer-based models.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024



Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
Reject Threshold Adaptation for Open-Set Model Attribution of Deepfake Audio
Dec 02, 2024



Open environment oriented open set model attribution of deepfake audio is an emerging research topic, aiming to identify the generation models of deepfake audio. Most previous work requires manually setting a rejection threshold for unknown classes to compare with predicted probabilities. However, models often overfit training instances and generate overly confident predictions. Moreover, thresholds that effectively distinguish unknown categories in the current dataset may not be suitable for identifying known and unknown categories in another data distribution. To address the issues, we propose a novel framework for open set model attribution of deepfake audio with rejection threshold adaptation (ReTA). Specifically, the reconstruction error learning module trains by combining the representation of system fingerprints with labels corresponding to either the target class or a randomly chosen other class label. This process generates matching and non-matching reconstructed samples, establishing the reconstruction error distributions for each class and laying the foundation for the reject threshold calculation module. The reject threshold calculation module utilizes gaussian probability estimation to fit the distributions of matching and non-matching reconstruction errors. It then computes adaptive reject thresholds for all classes through probability minimization criteria. The experimental results demonstrate the effectiveness of ReTA in improving the open set model attributes of deepfake audio.
Beyond Examples: High-level Automated Reasoning Paradigm in In-Context Learning via MCTS
Nov 27, 2024In-context Learning (ICL) enables large language models (LLMs) to tackle downstream tasks through sophisticated prompting and high-quality demonstrations. However, this traditional ICL paradigm shows limitations when facing complex mathematical reasoning tasks, primarily due to its heavy dependence on example quality and the necessity for human intervention in challenging scenarios. To address these limitations, this paper presents HiAR-ICL, a \textbf{Hi}gh-level \textbf{A}utomated \textbf{R}easoning paradigm in \textbf{ICL} that shifts focus from specific examples to abstract thinking patterns, extending the conventional concept of context in ICL. HiAR-ICL introduces five atomic reasoning actions as fundamental components for constructing chain-structured patterns. Using Monte Carlo Tree Search, we explore reasoning paths and construct thought cards to guide subsequent inference. We then develop a cognitive complexity framework that dynamically matches problems with appropriate thought cards. Experimental results demonstrate HiAR-ICL's effectiveness, achieving state-of-the-art accuracy (79.6$\%$) on the MATH benchmark with Qwen2.5-7B-Instruct, surpassing GPT-4o (76.6$\%$) and Claude 3.5 (71.1$\%$).
LetsTalk: Latent Diffusion Transformer for Talking Video Synthesis
Nov 24, 2024



Portrait image animation using audio has rapidly advanced, enabling the creation of increasingly realistic and expressive animated faces. The challenges of this multimodality-guided video generation task involve fusing various modalities while ensuring consistency in timing and portrait. We further seek to produce vivid talking heads. To address these challenges, we present LetsTalk (LatEnt Diffusion TranSformer for Talking Video Synthesis), a diffusion transformer that incorporates modular temporal and spatial attention mechanisms to merge multimodality and enhance spatial-temporal consistency. To handle multimodal conditions, we first summarize three fusion schemes, ranging from shallow to deep fusion compactness, and thoroughly explore their impact and applicability. Then we propose a suitable solution according to the modality differences of image, audio, and video generation. For portrait, we utilize a deep fusion scheme (Symbiotic Fusion) to ensure portrait consistency. For audio, we implement a shallow fusion scheme (Direct Fusion) to achieve audio-animation alignment while preserving diversity. Our extensive experiments demonstrate that our approach generates temporally coherent and realistic videos with enhanced diversity and liveliness.
DARNet: Dual Attention Refinement Network with Spatiotemporal Construction for Auditory Attention Detection
Oct 15, 2024



At a cocktail party, humans exhibit an impressive ability to direct their attention. The auditory attention detection (AAD) approach seeks to identify the attended speaker by analyzing brain signals, such as EEG signals. However, current AAD algorithms overlook the spatial distribution information within EEG signals and lack the ability to capture long-range latent dependencies, limiting the model's ability to decode brain activity. To address these issues, this paper proposes a dual attention refinement network with spatiotemporal construction for AAD, named DARNet, which consists of the spatiotemporal construction module, dual attention refinement module, and feature fusion \& classifier module. Specifically, the spatiotemporal construction module aims to construct more expressive spatiotemporal feature representations, by capturing the spatial distribution characteristics of EEG signals. The dual attention refinement module aims to extract different levels of temporal patterns in EEG signals and enhance the model's ability to capture long-range latent dependencies. The feature fusion \& classifier module aims to aggregate temporal patterns and dependencies from different levels and obtain the final classification results. The experimental results indicate that compared to the state-of-the-art models, DARNet achieves an average classification accuracy improvement of 5.9\% for 0.1s, 4.6\% for 1s, and 3.9\% for 2s on the DTU dataset. While maintaining excellent classification performance, DARNet significantly reduces the number of required parameters. Compared to the state-of-the-art models, DARNet reduces the parameter count by 91\%. Code is available at: https://github.com/fchest/DARNet.git.
Mixture of Experts Fusion for Fake Audio Detection Using Frozen wav2vec 2.0
Sep 18, 2024



Speech synthesis technology has posed a serious threat to speaker verification systems. Currently, the most effective fake audio detection methods utilize pretrained models, and integrating features from various layers of pretrained model further enhances detection performance. However, most of the previously proposed fusion methods require fine-tuning the pretrained models, resulting in excessively long training times and hindering model iteration when facing new speech synthesis technology. To address this issue, this paper proposes a feature fusion method based on the Mixture of Experts, which extracts and integrates features relevant to fake audio detection from layer features, guided by a gating network based on the last layer feature, while freezing the pretrained model. Experiments conducted on the ASVspoof2019 and ASVspoof2021 datasets demonstrate that the proposed method achieves competitive performance compared to those requiring fine-tuning.