 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionHijack: Supply-Chain PRNG Backdoor Attack on Diffusion Models and Quantum Random Number Defense
May 13, 2026Diffusion models depend on pseudo-random number generators (PRNGs) for latent noise sampling. We present DiffusionHijack, a supply-chain backdoor attack that hijacks the PRNG to deterministically control generated images. A malicious PRNG, injected via compromised packages, forces pixel-perfect reproduction of attacker-chosen content (SSIM = 1.00, N = 100 trials) on Stable Diffusion v1.4, v1.5, and SDXL -- without modifying model weights. The attack is inherently undetectable by existing model auditing and content moderation mechanisms, as it operates entirely outside the neural network computation graph. The attack remains effective under stochastic sampling (eta > 0), bypasses CLIP-based safety checkers (98-100% success), and operates independently of the user's prompt. As a countermeasure, we replace the PRNG with a quantum random number generator (QRNG), which provides information-theoretic unpredictability. Across N = 100 prompt-model combinations, QRNG defense completely neutralizes the attack, reducing output similarity to random baseline levels (SSIM < 0.20 for SD 1.x models, < 0.45 for SDXL). This work exposes a previously overlooked supply-chain vulnerability and offers a hardware-level fundamental mitigation for generative AI systems.
A Self-Evolving Defect Detection Framework for Industrial Photovoltaic Systems
Mar 16, 2026Reliable photovoltaic (PV) power generation requires timely detection of module defects that may reduce energy yield, accelerate degradation, and increase lifecycle operation and maintenance costs during field operation. Electroluminescence (EL) imaging has therefore been widely adopted for PV module inspection. However, automated defect detection in real operational environments remains challenging due to heterogeneous module geometries, low-resolution imaging conditions, subtle defect morphology, long-tailed defect distributions, and continual data shifts introduced by evolving inspection and labeling processes. These factors significantly limit the robustness and long-term maintainability of conventional deep-learning inspection pipelines. To address these challenges, this paper proposes SEPDD, a Self-Evolving Photovoltaic Defect Detection framework designed for evolving industrial PV inspection scenarios. SEPDD integrates automated model optimization with a continual self-evolving learning mechanism, enabling the inspection system to progressively adapt to distribution shifts and newly emerging defect patterns during long-term deployment. Experiments conducted on both a public PV defect benchmark and a private industrial EL dataset demonstrate the effectiveness of the proposed framework. Both datasets exhibit severe class imbalance and significant domain shift. SEPDD achieves a leading mAP50 of 91.4% on the public dataset and 49.5% on the private dataset. It surpasses the autonomous baseline by 14.8% and human experts by 4.7% on the public dataset, and by 4.9% and 2.5%, respectively, on the private dataset.
MHANet: Multi-scale Hybrid Attention Network for Auditory Attention Detection
May 21, 2025



Auditory attention detection (AAD) aims to detect the target speaker in a multi-talker environment from brain signals, such as electroencephalography (EEG), which has made great progress. However, most AAD methods solely utilize attention mechanisms sequentially and overlook valuable multi-scale contextual information within EEG signals, limiting their ability to capture long-short range spatiotemporal dependencies simultaneously. To address these issues, this paper proposes a multi-scale hybrid attention network (MHANet) for AAD, which consists of the multi-scale hybrid attention (MHA) module and the spatiotemporal convolution (STC) module. Specifically, MHA combines channel attention and multi-scale temporal and global attention mechanisms. This effectively extracts multi-scale temporal patterns within EEG signals and captures long-short range spatiotemporal dependencies simultaneously. To further improve the performance of AAD, STC utilizes temporal and spatial convolutions to aggregate expressive spatiotemporal representations. Experimental results show that the proposed MHANet achieves state-of-the-art performance with fewer trainable parameters across three datasets, 3 times lower than that of the most advanced model. Code is available at: https://github.com/fchest/MHANet.
ListenNet: A Lightweight Spatio-Temporal Enhancement Nested Network for Auditory Attention Detection
May 15, 2025



Auditory attention detection (AAD) aims to identify the direction of the attended speaker in multi-speaker environments from brain signals, such as Electroencephalography (EEG) signals. However, existing EEG-based AAD methods overlook the spatio-temporal dependencies of EEG signals, limiting their decoding and generalization abilities. To address these issues, this paper proposes a Lightweight Spatio-Temporal Enhancement Nested Network (ListenNet) for AAD. The ListenNet has three key components: Spatio-temporal Dependency Encoder (STDE), Multi-scale Temporal Enhancement (MSTE), and Cross-Nested Attention (CNA). The STDE reconstructs dependencies between consecutive time windows across channels, improving the robustness of dynamic pattern extraction. The MSTE captures temporal features at multiple scales to represent both fine-grained and long-range temporal patterns. In addition, the CNA integrates hierarchical features more effectively through novel dynamic attention mechanisms to capture deep spatio-temporal correlations. Experimental results on three public datasets demonstrate the superiority of ListenNet over state-of-the-art methods in both subject-dependent and challenging subject-independent settings, while reducing the trainable parameter count by approximately 7 times. Code is available at:https://github.com/fchest/ListenNet.
DARNet: Dual Attention Refinement Network with Spatiotemporal Construction for Auditory Attention Detection
Oct 15, 2024



At a cocktail party, humans exhibit an impressive ability to direct their attention. The auditory attention detection (AAD) approach seeks to identify the attended speaker by analyzing brain signals, such as EEG signals. However, current AAD algorithms overlook the spatial distribution information within EEG signals and lack the ability to capture long-range latent dependencies, limiting the model's ability to decode brain activity. To address these issues, this paper proposes a dual attention refinement network with spatiotemporal construction for AAD, named DARNet, which consists of the spatiotemporal construction module, dual attention refinement module, and feature fusion \& classifier module. Specifically, the spatiotemporal construction module aims to construct more expressive spatiotemporal feature representations, by capturing the spatial distribution characteristics of EEG signals. The dual attention refinement module aims to extract different levels of temporal patterns in EEG signals and enhance the model's ability to capture long-range latent dependencies. The feature fusion \& classifier module aims to aggregate temporal patterns and dependencies from different levels and obtain the final classification results. The experimental results indicate that compared to the state-of-the-art models, DARNet achieves an average classification accuracy improvement of 5.9\% for 0.1s, 4.6\% for 1s, and 3.9\% for 2s on the DTU dataset. While maintaining excellent classification performance, DARNet significantly reduces the number of required parameters. Compared to the state-of-the-art models, DARNet reduces the parameter count by 91\%. Code is available at: https://github.com/fchest/DARNet.git.
Efficient and Scalable Structure Learning for Bayesian Networks: Algorithms and Applications
Dec 07, 2020


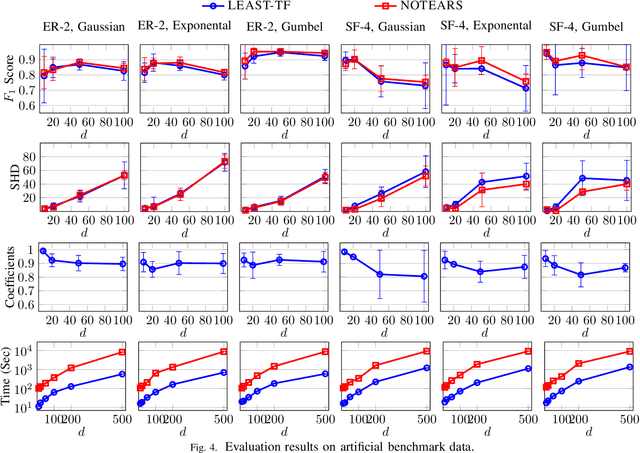
Structure Learning for Bayesian network (BN) is an important problem with extensive research. It plays central roles in a wide variety of applications in Alibaba Group. However, existing structure learning algorithms suffer from considerable limitations in real world applications due to their low efficiency and poor scalability. To resolve this, we propose a new structure learning algorithm LEAST, which comprehensively fulfills our business requirements as it attains high accuracy, efficiency and scalability at the same time. The core idea of LEAST is to formulate the structure learning into a continuous constrained optimization problem, with a novel differentiable constraint function measuring the acyclicity of the resulting graph. Unlike with existing work, our constraint function is built on the spectral radius of the graph and could be evaluated in near linear time w.r.t. the graph node size. Based on it, LEAST can be efficiently implemented with low storage overhead. According to our benchmark evaluation, LEAST runs 1 to 2 orders of magnitude faster than state of the art method with comparable accuracy, and it is able to scale on BNs with up to hundreds of thousands of variables. In our production environment, LEAST is deployed and serves for more than 20 applications with thousands of executions per day. We describe a concrete scenario in a ticket booking service in Alibaba, where LEAST is applied to build a near real-time automatic anomaly detection and root error cause analysis system. We also show that LEAST unlocks the possibility of applying BN structure learning in new areas, such as large-scale gene expression data analysis and explainable recommendation system.