 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse Graining Molecular Dynamics with Graph Neural Networks
Aug 21, 2020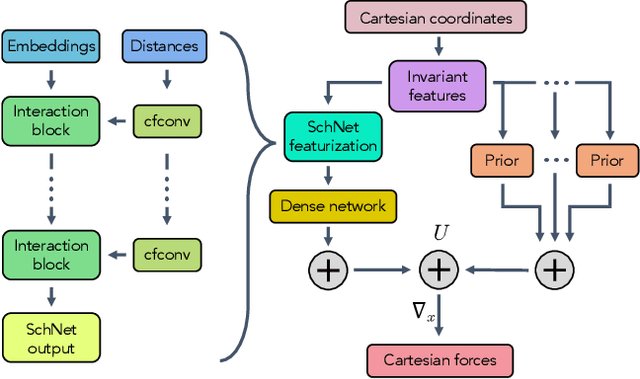
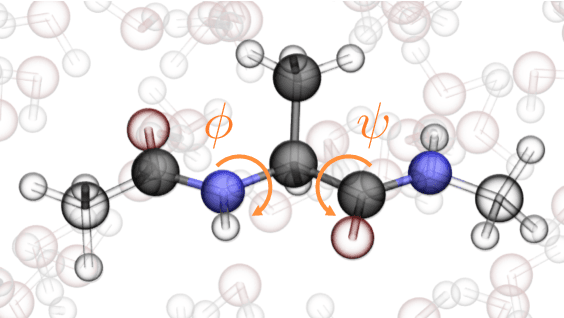
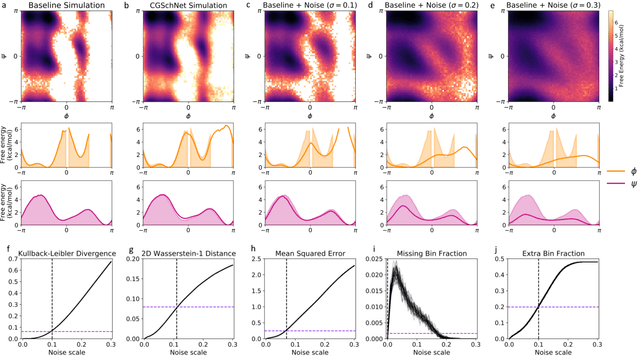
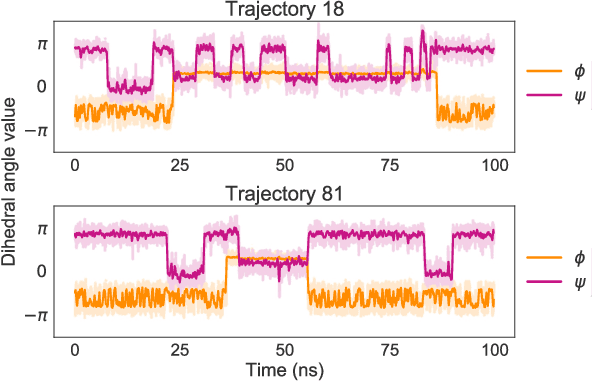
Coarse graining enables the investigation of molecular dynamics for larger systems and at longer timescales than is possible at atomic resolution. However, a coarse graining model must be formulated such that the conclusions we draw from it are consistent with the conclusions we would draw from a model at a finer level of detail. It has been proven that a force matching scheme defines a thermodynamically consistent coarse-grained model for an atomistic system in the variational limit. Wang et al. [ACS Cent. Sci. 5, 755 (2019)] demonstrated that the existence of such a variational limit enables the use of a supervised machine learning framework to generate a coarse-grained force field, which can then be used for simulation in the coarse-grained space. Their framework, however, requires the manual input of molecular features upon which to machine learn the force field. In the present contribution, we build upon the advance of Wang et al.and introduce a hybrid architecture for the machine learning of coarse-grained force fields that learns their own features via a subnetwork that leverages continuous filter convolutions on a graph neural network architecture. We demonstrate that this framework succeeds at reproducing the thermodynamics for small biomolecular systems. Since the learned molecular representations are inherently transferable, the architecture presented here sets the stage for the development of machine-learned, coarse-grained force fields that are transferable across molecular systems.
Ensemble Learning of Coarse-Grained Molecular Dynamics Force Fields with a Kernel Approach
May 04, 2020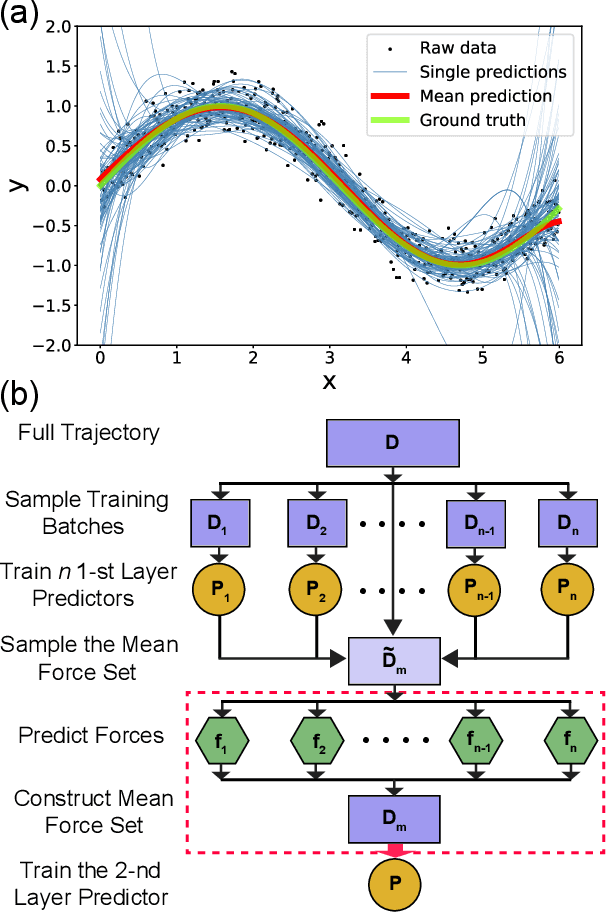
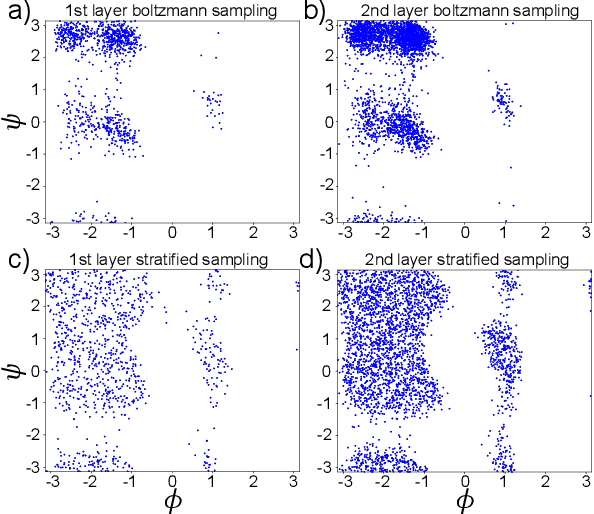
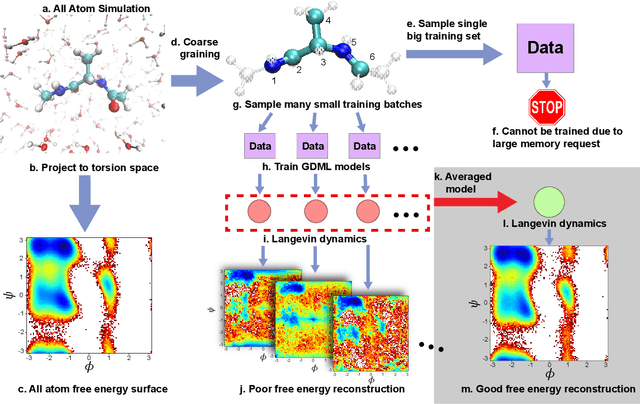
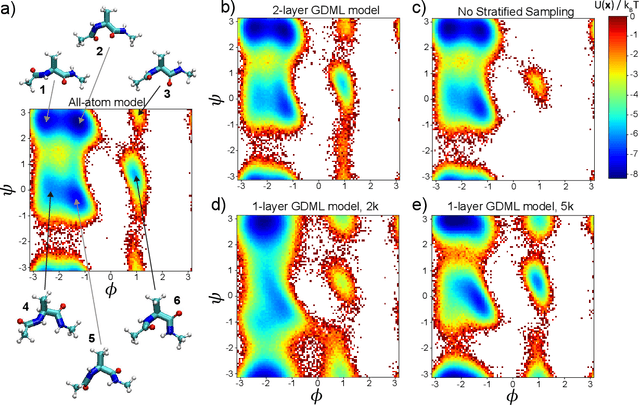
Gradient-domain machine learning (GDML) is an accurate and efficient approach to learn a molecular potential and associated force field based on the kernel ridge regression algorithm. Here, we demonstrate its application to learn an effective coarse-grained (CG) model from all-atom simulation data in a sample efficient manner. The coarse-grained force field is learned by following the thermodynamic consistency principle, here by minimizing the error between the predicted coarse-grained force and the all-atom mean force in the coarse-grained coordinates. Solving this problem by GDML directly is impossible because coarse-graining requires averaging over many training data points, resulting in impractical memory requirements for storing the kernel matrices. In this work, we propose a data-efficient and memory-saving alternative. Using ensemble learning and stratified sampling, we propose a 2-layer training scheme that enables GDML to learn an effective coarse-grained model. We illustrate our method on a simple biomolecular system, alanine dipeptide, by reconstructing the free energy landscape of a coarse-grained variant of this molecule. Our novel GDML training scheme yields a smaller free energy error than neural networks when the training set is small, and a comparably high accuracy when the training set is sufficiently large.
RC-DARTS: Resource Constrained Differentiable Architecture Search
Dec 30, 2019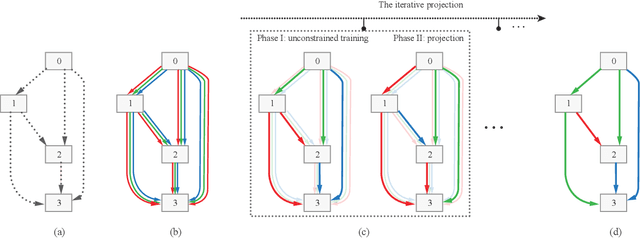
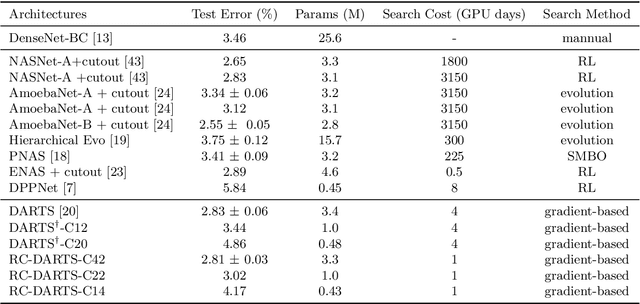
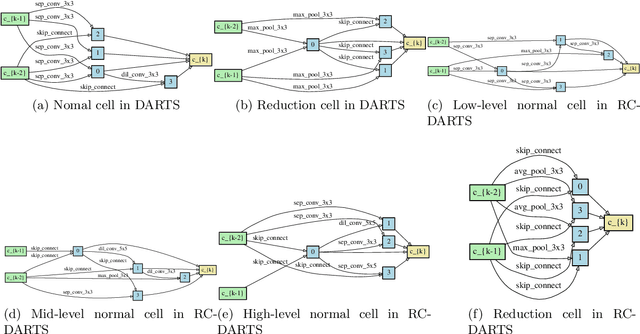
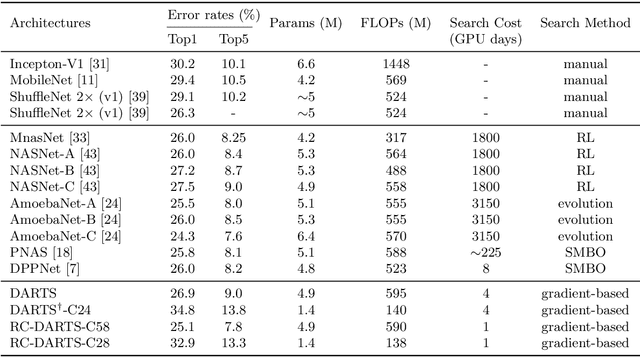
Recent advances show that Neural Architectural Search (NAS) method is able to find state-of-the-art image classification deep architectures. In this paper, we consider the one-shot NAS problem for resource constrained applications. This problem is of great interest because it is critical to choose different architectures according to task complexity when the resource is constrained. Previous techniques are either too slow for one-shot learning or does not take the resource constraint into consideration. In this paper, we propose the resource constrained differentiable architecture search (RC-DARTS) method to learn architectures that are significantly smaller and faster while achieving comparable accuracy. Specifically, we propose to formulate the RC-DARTS task as a constrained optimization problem by adding the resource constraint. An iterative projection method is proposed to solve the given constrained optimization problem. We also propose a multi-level search strategy to enable layers at different depths to adaptively learn different types of neural architectures. Through extensive experiments on the Cifar10 and ImageNet datasets, we show that the RC-DARTS method learns lightweight neural architectures which have smaller model size and lower computational complexity while achieving comparable or better performances than the state-of-the-art methods.
Adversarial Examples Improve Image Recognition
Nov 21, 2019
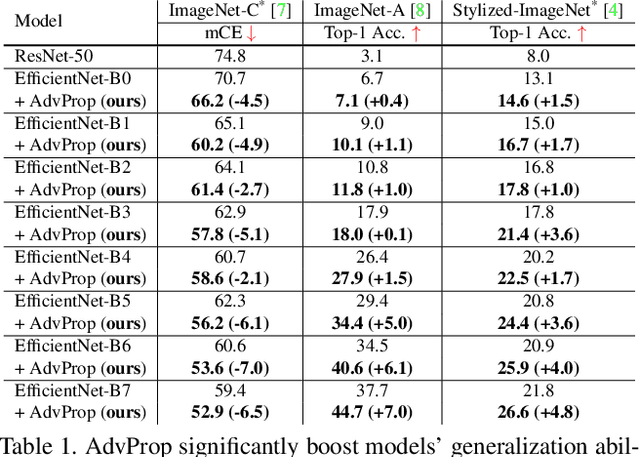
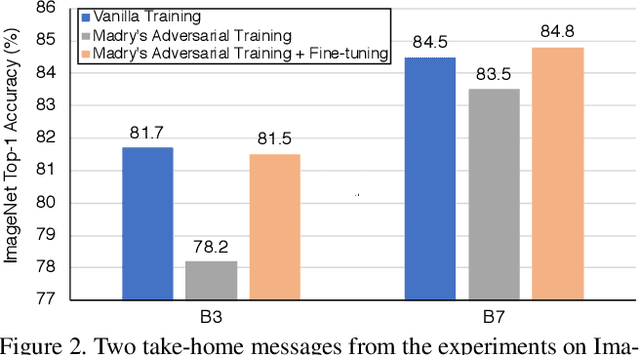
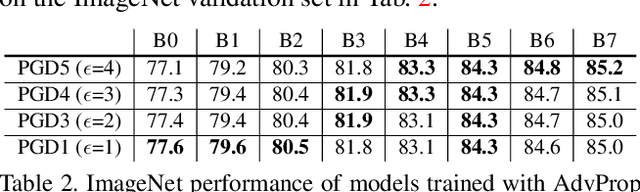
Adversarial examples are commonly viewed as a threat to ConvNets. Here we present an opposite perspective: adversarial examples can be used to improve image recognition models if harnessed in the right manner. We propose AdvProp, an enhanced adversarial training scheme which treats adversarial examples as additional examples, to prevent overfitting. Key to our method is the usage of a separate auxiliary batch norm for adversarial examples, as they have different underlying distributions to normal examples. We show that AdvProp improves a wide range of models on various image recognition tasks and performs better when the models are bigger. For instance, by applying AdvProp to the latest EfficientNet-B7 [28] on ImageNet, we achieve significant improvements on ImageNet (+0.7%), ImageNet-C (+6.5%), ImageNet-A (+7.0%), Stylized-ImageNet (+4.8%). With an enhanced EfficientNet-B8, our method achieves the state-of-the-art 85.5% ImageNet top-1 accuracy without extra data. This result even surpasses the best model in [20] which is trained with 3.5B Instagram images (~3000X more than ImageNet) and ~9.4X more parameters. Models are available at https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet.
Machine Learning of coarse-grained Molecular Dynamics Force Fields
Dec 08, 2018
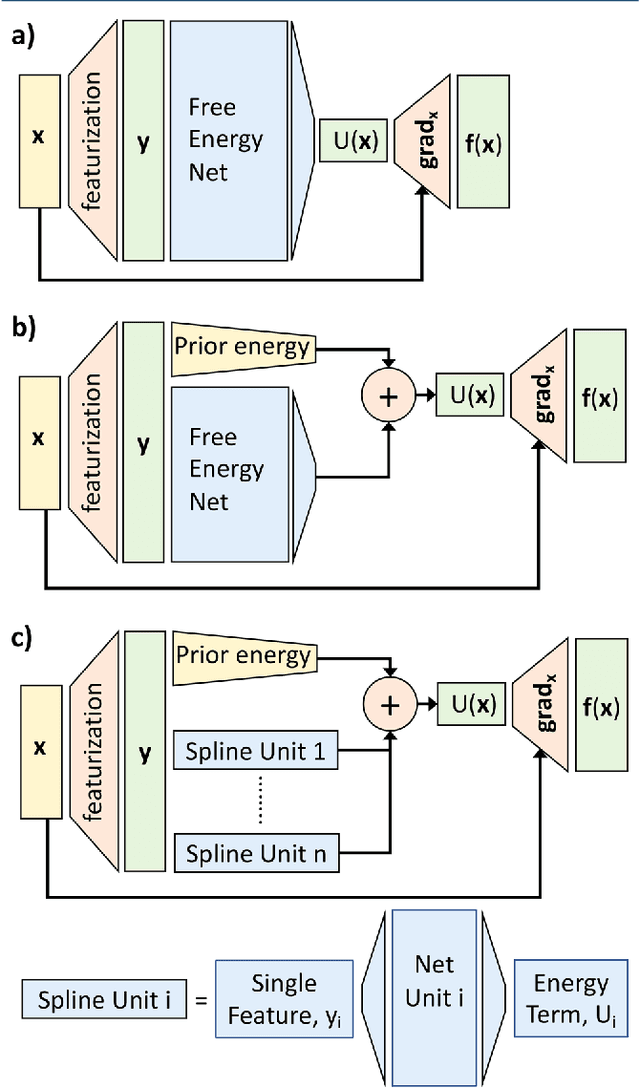
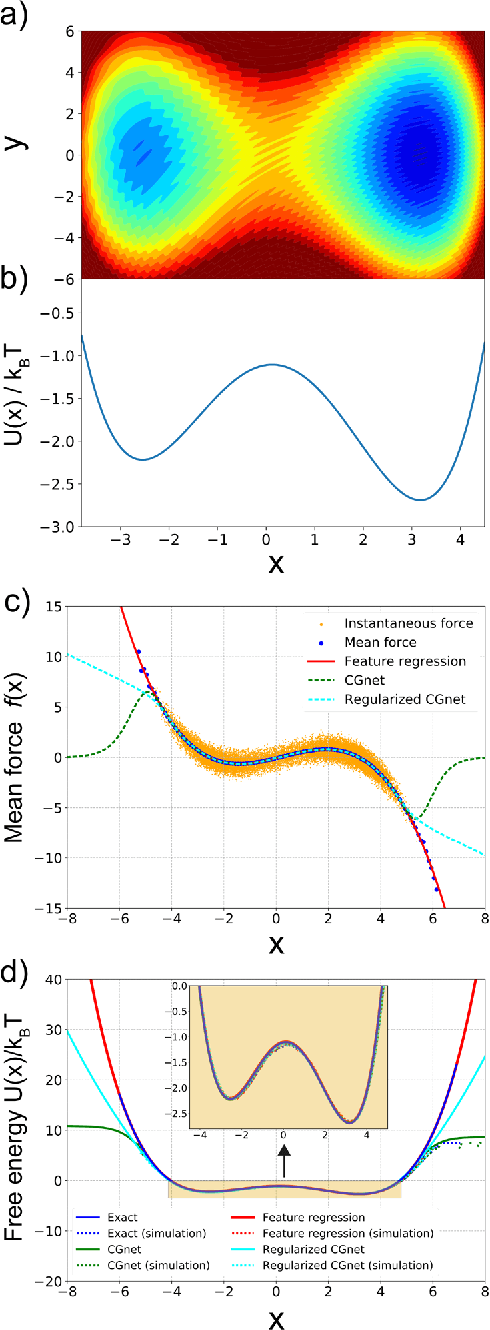
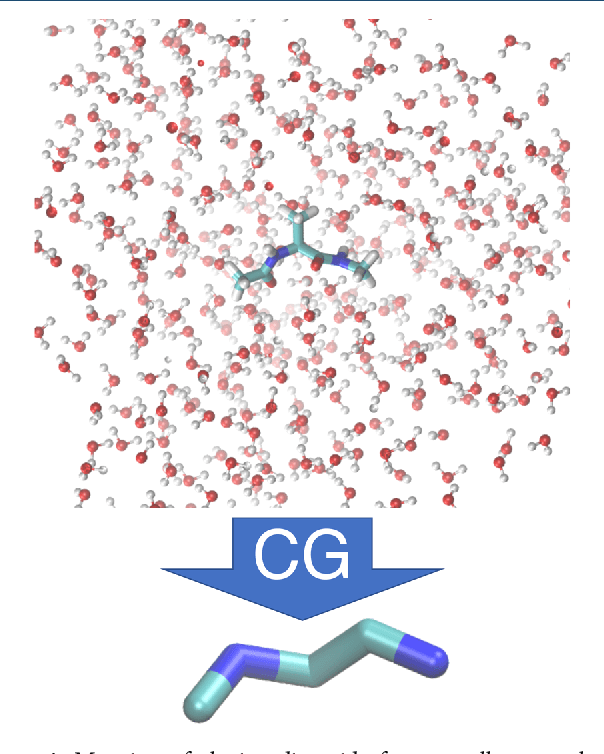
Atomistic or ab-initio molecular dynamics simulations are widely used to predict thermodynamics and kinetics and relate them to molecular structure. A common approach to go beyond the time- and lengthscales accessible with such computationally expensive simulations is the definition of coarse-grained molecular models. Existing coarse-graining approaches define an effective interaction potential to match defined properties of high-resolution models or experimental data. In this paper we reformulate coarse-graining as a supervised machine learning problem. We use statistical learning theory to decompose the coarse-graining error and cross-validation to select to compare the performance of different models. We introduce CGnets, a deep learning approach, that learn coarse-grained free energy functions and can be trained by the force matching scheme. CGnets maintain all physically relevant invariances and allow to incorporate prior physics knowledge to avoid sampling of unphysical structures. We demonstrate that CGnets outperform the results of classical coarse-graining methods, as they are able to capture the multi-body terms that emerge from the dimensionality reduction.
NOTE-RCNN: NOise Tolerant Ensemble RCNN for Semi-Supervised Object Detection
Dec 01, 2018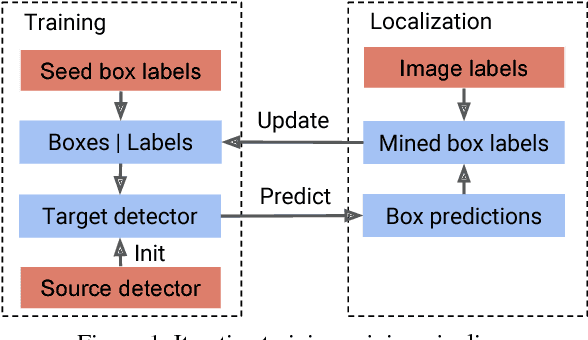
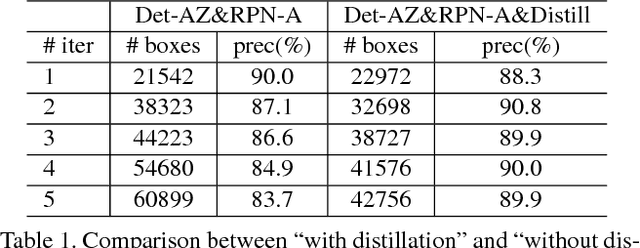

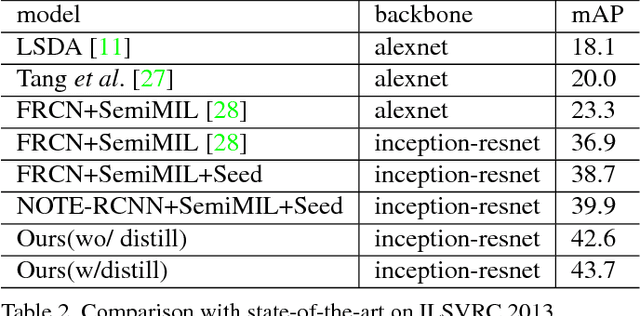
The labeling cost of large number of bounding boxes is one of the main challenges for training modern object detectors. To reduce the dependence on expensive bounding box annotations, we propose a new semi-supervised object detection formulation, in which a few seed box level annotations and a large scale of image level annotations are used to train the detector. We adopt a training-mining framework, which is widely used in weakly supervised object detection tasks. However, the mining process inherently introduces various kinds of labelling noises: false negatives, false positives and inaccurate boundaries, which can be harmful for training the standard object detectors (e.g. Faster RCNN). We propose a novel NOise Tolerant Ensemble RCNN (NOTE-RCNN) object detector to handle such noisy labels. Comparing to standard Faster RCNN, it contains three highlights: an ensemble of two classification heads and a distillation head to avoid overfitting on noisy labels and improve the mining precision, masking the negative sample loss in box predictor to avoid the harm of false negative labels, and training box regression head only on seed annotations to eliminate the harm from inaccurate boundaries of mined bounding boxes. We evaluate the methods on ILSVRC 2013 and MSCOCO 2017 dataset; we observe that the detection accuracy consistently improves as we iterate between mining and training steps, and state-of-the-art performance is achieved.
Training Generative Adversarial Networks via Primal-Dual Subgradient Methods: A Lagrangian Perspective on GAN
Feb 06, 2018
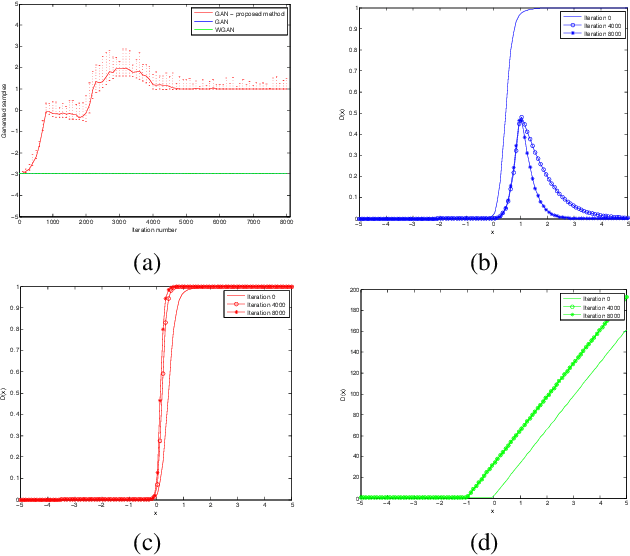

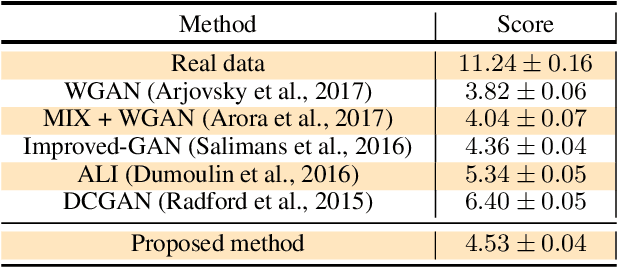
We relate the minimax game of generative adversarial networks (GANs) to finding the saddle points of the Lagrangian function for a convex optimization problem, where the discriminator outputs and the distribution of generator outputs play the roles of primal variables and dual variables, respectively. This formulation shows the connection between the standard GAN training process and the primal-dual subgradient methods for convex optimization. The inherent connection does not only provide a theoretical convergence proof for training GANs in the function space, but also inspires a novel objective function for training. The modified objective function forces the distribution of generator outputs to be updated along the direction according to the primal-dual subgradient methods. A toy example shows that the proposed method is able to resolve mode collapse, which in this case cannot be avoided by the standard GAN or Wasserstein GAN. Experiments on both Gaussian mixture synthetic data and real-world image datasets demonstrate the performance of the proposed method on generating diverse samples.
Fully Convolutional Attention Networks for Fine-Grained Recognition
Mar 21, 2017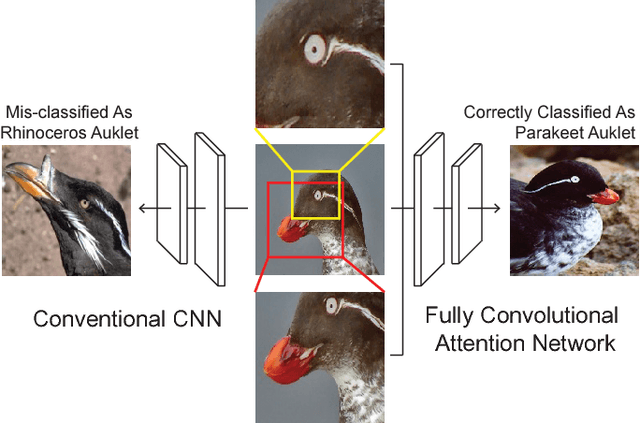
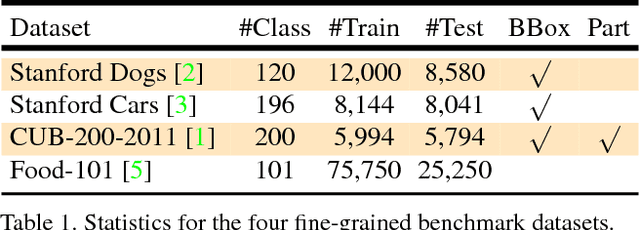

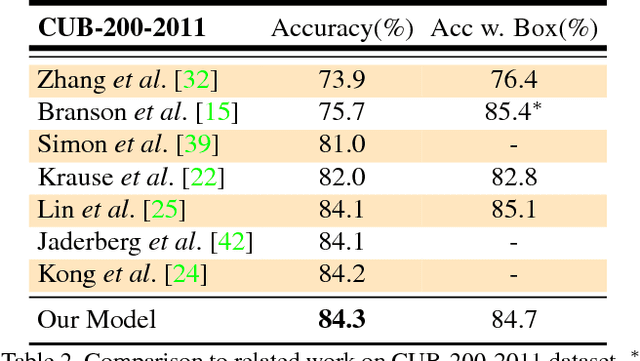
Fine-grained recognition is challenging due to its subtle local inter-class differences versus large intra-class variations such as poses. A key to address this problem is to localize discriminative parts to extract pose-invariant features. However, ground-truth part annotations can be expensive to acquire. Moreover, it is hard to define parts for many fine-grained classes. This work introduces Fully Convolutional Attention Networks (FCANs), a reinforcement learning framework to optimally glimpse local discriminative regions adaptive to different fine-grained domains. Compared to previous methods, our approach enjoys three advantages: 1) the weakly-supervised reinforcement learning procedure requires no expensive part annotations; 2) the fully-convolutional architecture speeds up both training and testing; 3) the greedy reward strategy accelerates the convergence of the learning. We demonstrate the effectiveness of our method with extensive experiments on four challenging fine-grained benchmark datasets, including CUB-200-2011, Stanford Dogs, Stanford Cars and Food-101.
Attention to Scale: Scale-aware Semantic Image Segmentation
Jun 02, 2016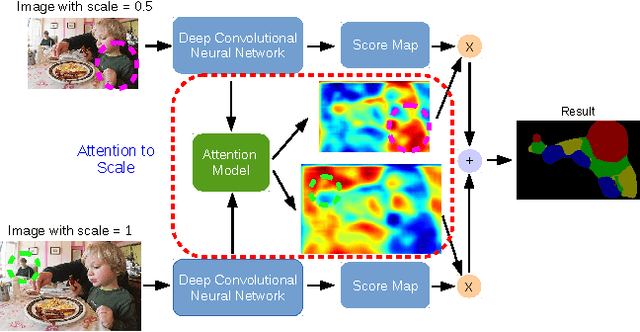
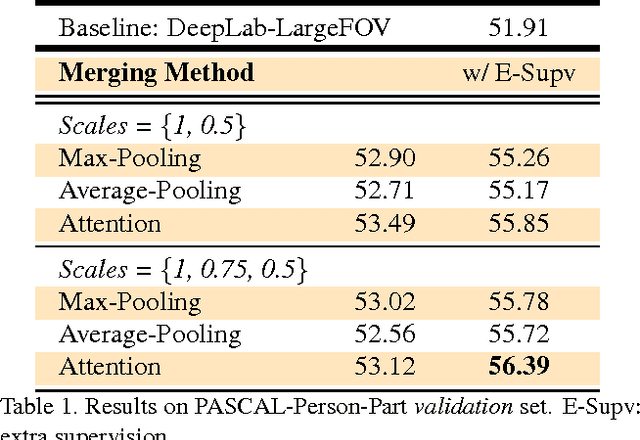
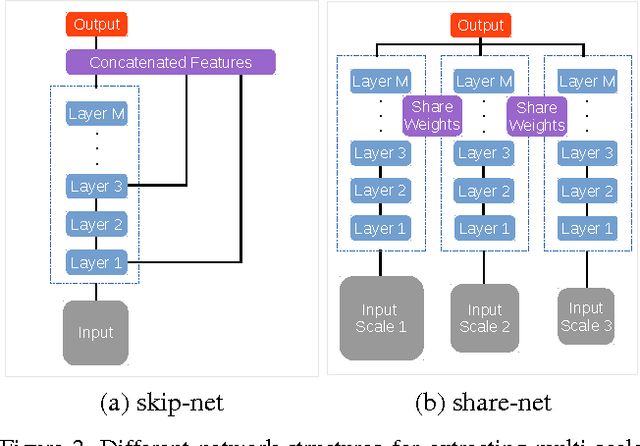

Incorporating multi-scale features in fully convolutional neural networks (FCNs) has been a key element to achieving state-of-the-art performance on semantic image segmentation. One common way to extract multi-scale features is to feed multiple resized input images to a shared deep network and then merge the resulting features for pixelwise classification. In this work, we propose an attention mechanism that learns to softly weight the multi-scale features at each pixel location. We adapt a state-of-the-art semantic image segmentation model, which we jointly train with multi-scale input images and the attention model. The proposed attention model not only outperforms average- and max-pooling, but allows us to diagnostically visualize the importance of features at different positions and scales. Moreover, we show that adding extra supervision to the output at each scale is essential to achieving excellent performance when merging multi-scale features. We demonstrate the effectiveness of our model with extensive experiments on three challenging datasets, including PASCAL-Person-Part, PASCAL VOC 2012 and a subset of MS-COCO 2014.
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition
May 23, 2016
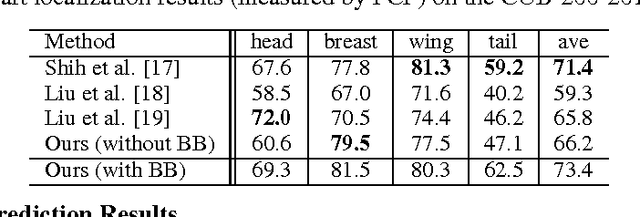
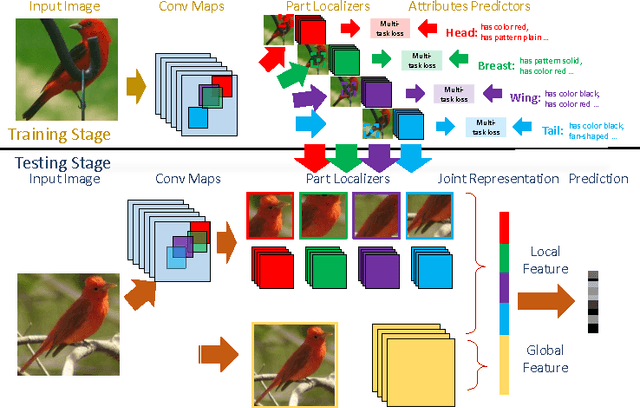
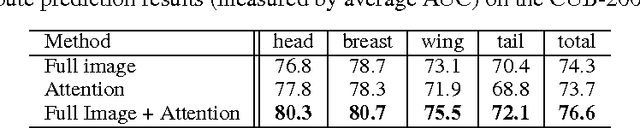
A key challenge in fine-grained recognition is how to find and represent discriminative local regions. Recent attention models are capable of learning discriminative region localizers only from category labels with reinforcement learning. However, not utilizing any explicit part information, they are not able to accurately find multiple distinctive regions. In this work, we introduce an attribute-guided attention localization scheme where the local region localizers are learned under the guidance of part attribute descriptions. By designing a novel reward strategy, we are able to learn to locate regions that are spatially and semantically distinctive with reinforcement learning algorithm. The attribute labeling requirement of the scheme is more amenable than the accurate part location annotation required by traditional part-based fine-grained recognition methods. Experimental results on the CUB-200-2011 dataset demonstrate the superiority of the proposed scheme on both fine-grained recognition and attribute recognition.