 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
Dec 20, 2022



Chain-of-Thought (CoT) prompting can dramatically improve the multi-step reasoning abilities of large language models (LLMs). CoT explicitly encourages the LLM to generate intermediate rationales for solving a problem, by providing a series of reasoning steps in the demonstrations. Despite its success, there is still little understanding of what makes CoT prompting effective and which aspects of the demonstrated reasoning steps contribute to its performance. In this paper, we show that CoT reasoning is possible even with invalid demonstrations - prompting with invalid reasoning steps can achieve over 80-90% of the performance obtained using CoT under various metrics, while still generating coherent lines of reasoning during inference. Further experiments show that other aspects of the rationales, such as being relevant to the query and correctly ordering the reasoning steps, are much more important for effective CoT reasoning. Overall, these findings both deepen our understanding of CoT prompting, and open up new questions regarding LLMs' capability to learn to reason in context.
OmniNeRF: Hybriding Omnidirectional Distance and Radiance fields for Neural Surface Reconstruction
Sep 27, 2022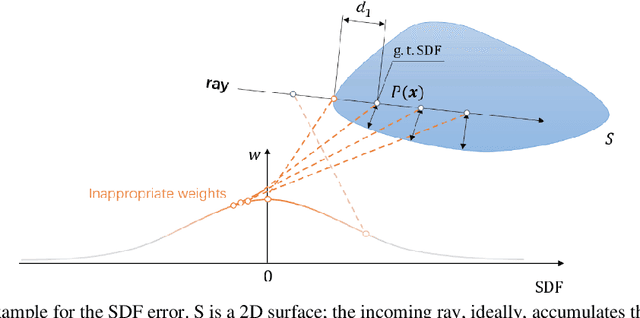

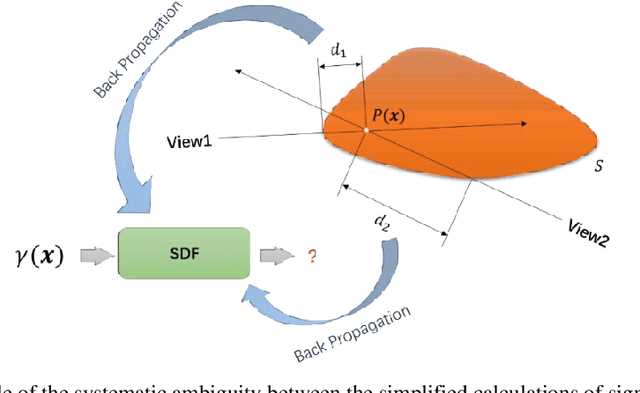
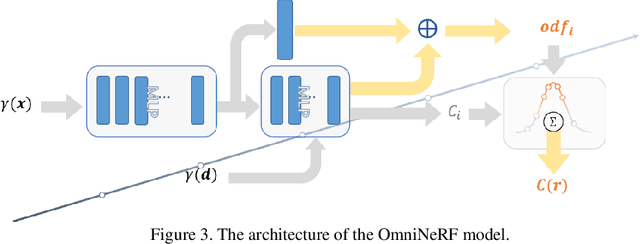
3D reconstruction from images has wide applications in Virtual Reality and Automatic Driving, where the precision requirement is very high. Ground-breaking research in the neural radiance field (NeRF) by utilizing Multi-Layer Perceptions has dramatically improved the representation quality of 3D objects. Some later studies improved NeRF by building truncated signed distance fields (TSDFs) but still suffer from the problem of blurred surfaces in 3D reconstruction. In this work, this surface ambiguity is addressed by proposing a novel way of 3D shape representation, OmniNeRF. It is based on training a hybrid implicit field of Omni-directional Distance Field (ODF) and neural radiance field, replacing the apparent density in NeRF with omnidirectional information. Moreover, we introduce additional supervision on the depth map to further improve reconstruction quality. The proposed method has been proven to effectively deal with NeRF defects at the edges of the surface reconstruction, providing higher quality 3D scene reconstruction results.
Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
Sep 15, 2022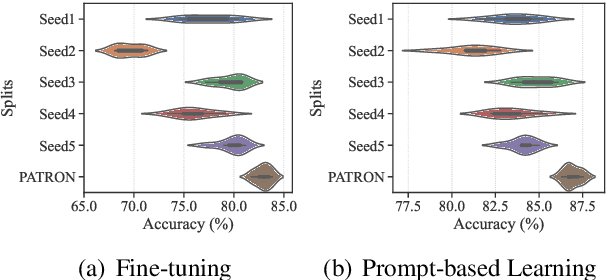
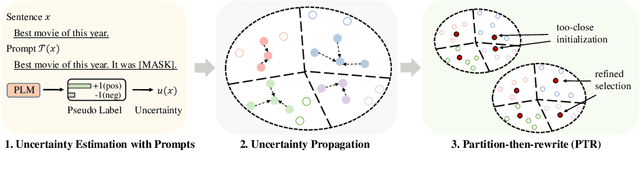

We propose PATRON, a new method that uses prompt-based uncertainty estimation for data selection for pre-trained language model fine-tuning under cold-start scenarios, i.e., no initial labeled data are available. In PATRON, we design (1) a prompt-based uncertainty propagation approach to estimate the importance of data points and (2) a partition-then-rewrite (PTR) strategy to promote sample diversity when querying for annotations. Experiments on six text classification datasets show that PATRON outperforms the strongest cold-start data selection baselines by up to 6.9%. Besides, with 128 labels only, PATRON achieves 91.0% and 92.1% of the fully supervised performance based on vanilla fine-tuning and prompt-based learning respectively. Our implementation of PATRON is available at \url{https://github.com/yueyu1030/Patron}.
Unsupervised Key Event Detection from Massive Text Corpora
Jun 08, 2022
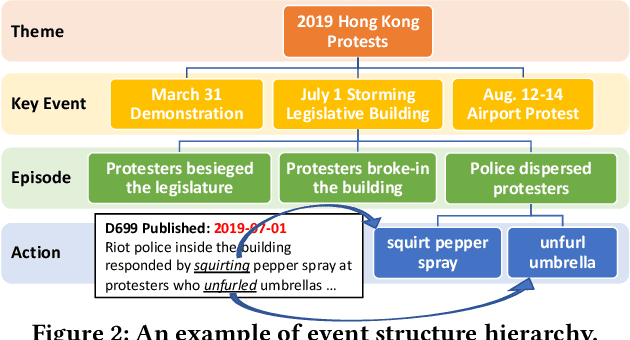
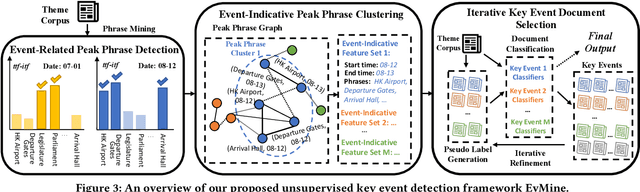
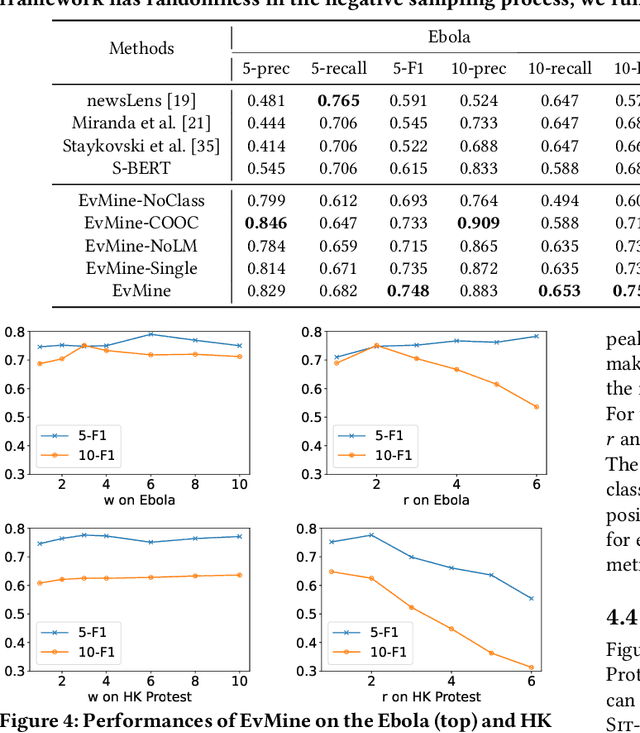
Automated event detection from news corpora is a crucial task towards mining fast-evolving structured knowledge. As real-world events have different granularities, from the top-level themes to key events and then to event mentions corresponding to concrete actions, there are generally two lines of research: (1) theme detection identifies from a news corpus major themes (e.g., "2019 Hong Kong Protests" vs. "2020 U.S. Presidential Election") that have very distinct semantics; and (2) action extraction extracts from one document mention-level actions (e.g., "the police hit the left arm of the protester") that are too fine-grained for comprehending the event. In this paper, we propose a new task, key event detection at the intermediate level, aiming to detect from a news corpus key events (e.g., "HK Airport Protest on Aug. 12-14"), each happening at a particular time/location and focusing on the same topic. This task can bridge event understanding and structuring and is inherently challenging because of the thematic and temporal closeness of key events and the scarcity of labeled data due to the fast-evolving nature of news articles. To address these challenges, we develop an unsupervised key event detection framework, EvMine, that (1) extracts temporally frequent peak phrases using a novel ttf-itf score, (2) merges peak phrases into event-indicative feature sets by detecting communities from our designed peak phrase graph that captures document co-occurrences, semantic similarities, and temporal closeness signals, and (3) iteratively retrieves documents related to each key event by training a classifier with automatically generated pseudo labels from the event-indicative feature sets and refining the detected key events using the retrieved documents. Extensive experiments and case studies show EvMine outperforms all the baseline methods and its ablations on two real-world news corpora.
TaxoCom: Topic Taxonomy Completion with Hierarchical Discovery of Novel Topic Clusters
Jan 19, 2022
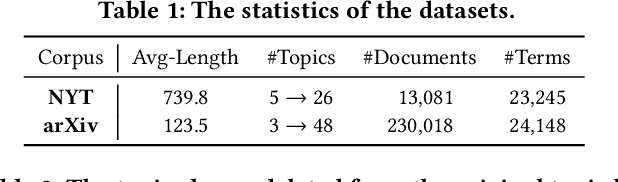
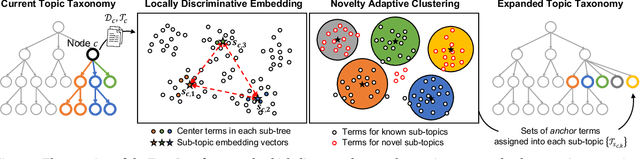
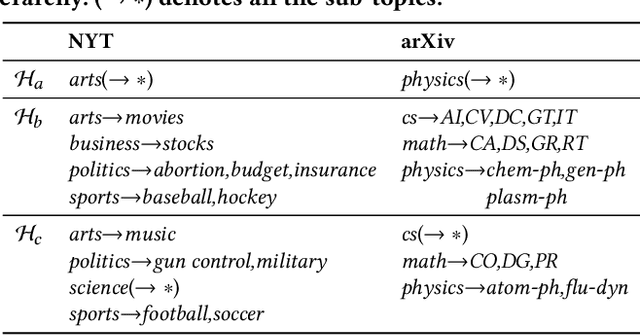
Topic taxonomies, which represent the latent topic (or category) structure of document collections, provide valuable knowledge of contents in many applications such as web search and information filtering. Recently, several unsupervised methods have been developed to automatically construct the topic taxonomy from a text corpus, but it is challenging to generate the desired taxonomy without any prior knowledge. In this paper, we study how to leverage the partial (or incomplete) information about the topic structure as guidance to find out the complete topic taxonomy. We propose a novel framework for topic taxonomy completion, named TaxoCom, which recursively expands the topic taxonomy by discovering novel sub-topic clusters of terms and documents. To effectively identify novel topics within a hierarchical topic structure, TaxoCom devises its embedding and clustering techniques to be closely-linked with each other: (i) locally discriminative embedding optimizes the text embedding space to be discriminative among known (i.e., given) sub-topics, and (ii) novelty adaptive clustering assigns terms into either one of the known sub-topics or novel sub-topics. Our comprehensive experiments on two real-world datasets demonstrate that TaxoCom not only generates the high-quality topic taxonomy in terms of term coherency and topic coverage but also outperforms all other baselines for a downstream task.
Corpus-based Open-Domain Event Type Induction
Sep 07, 2021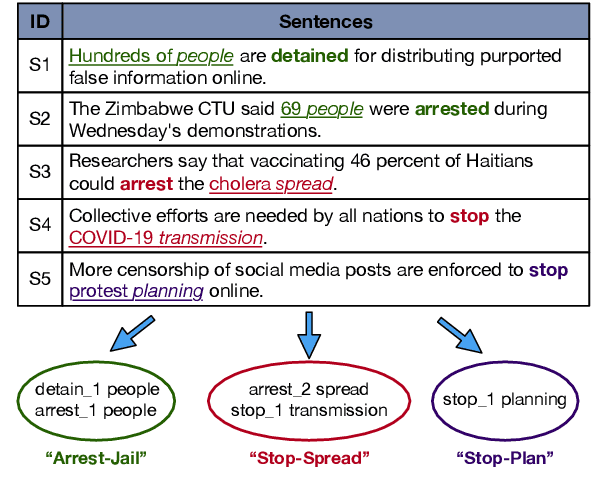

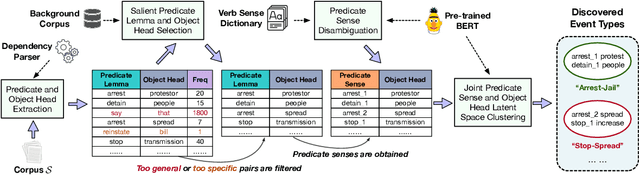
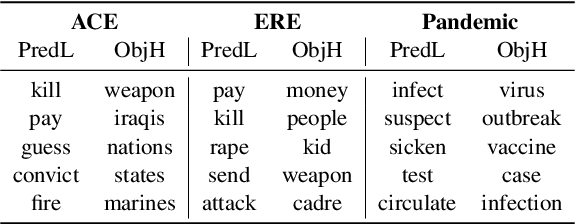
Traditional event extraction methods require predefined event types and their corresponding annotations to learn event extractors. These prerequisites are often hard to be satisfied in real-world applications. This work presents a corpus-based open-domain event type induction method that automatically discovers a set of event types from a given corpus. As events of the same type could be expressed in multiple ways, we propose to represent each event type as a cluster of <predicate sense, object head> pairs. Specifically, our method (1) selects salient predicates and object heads, (2) disambiguates predicate senses using only a verb sense dictionary, and (3) obtains event types by jointly embedding and clustering <predicate sense, object head> pairs in a latent spherical space. Our experiments, on three datasets from different domains, show our method can discover salient and high-quality event types, according to both automatic and human evaluations.
Eider: Evidence-enhanced Document-level Relation Extraction
Jun 16, 2021
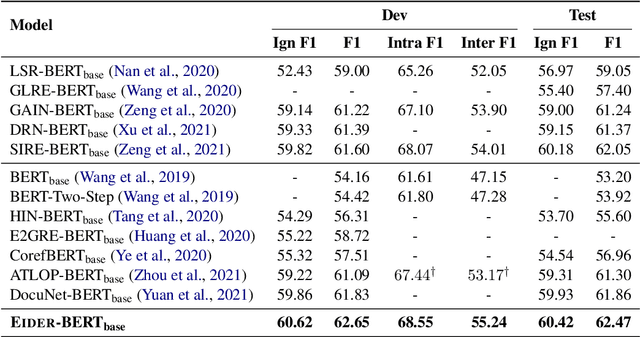
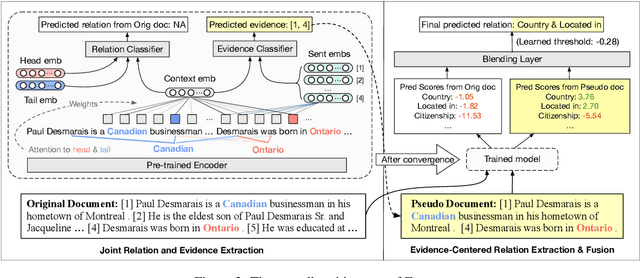

Document-level relation extraction (DocRE) aims at extracting the semantic relations among entity pairs in a document. In DocRE, a subset of the sentences in a document, called the evidence sentences, might be sufficient for predicting the relation between a specific entity pair. To make better use of the evidence sentences, in this paper, we propose a three-stage evidence-enhanced DocRE framework consisting of joint relation and evidence extraction, evidence-centered relation extraction (RE), and fusion of extraction results. We first jointly train an RE model with a simple and memory-efficient evidence extraction model. Then, we construct pseudo documents based on the extracted evidence sentences and run the RE model again. Finally, we fuse the extraction results of the first two stages using a blending layer and make a final prediction. Extensive experiments show that our proposed framework achieves state-of-the-art performance on the DocRED dataset, outperforming the second-best method by 0.76/0.82 Ign F1/F1. In particular, our method significantly improves the performance on inter-sentence relations by 1.23 Inter F1.
Training ELECTRA Augmented with Multi-word Selection
May 31, 2021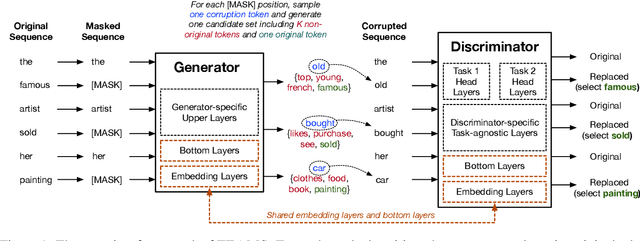
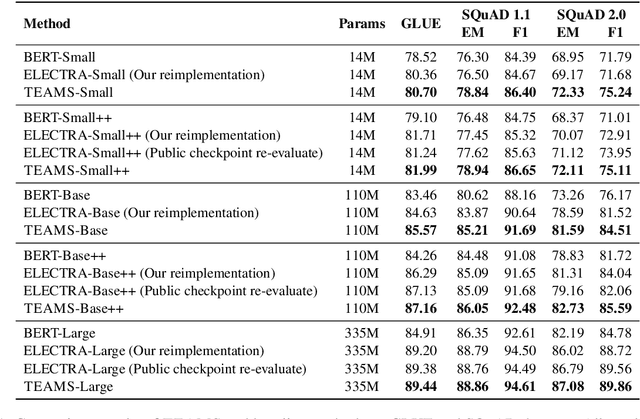
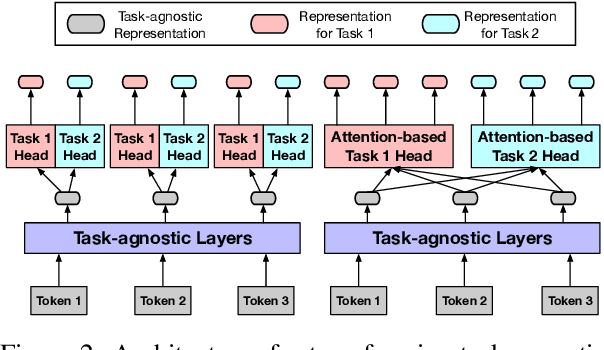
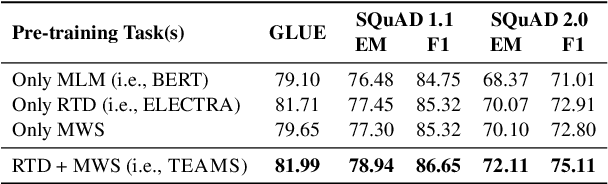
Pre-trained text encoders such as BERT and its variants have recently achieved state-of-the-art performances on many NLP tasks. While being effective, these pre-training methods typically demand massive computation resources. To accelerate pre-training, ELECTRA trains a discriminator that predicts whether each input token is replaced by a generator. However, this new task, as a binary classification, is less semantically informative. In this study, we present a new text encoder pre-training method that improves ELECTRA based on multi-task learning. Specifically, we train the discriminator to simultaneously detect replaced tokens and select original tokens from candidate sets. We further develop two techniques to effectively combine all pre-training tasks: (1) using attention-based networks for task-specific heads, and (2) sharing bottom layers of the generator and the discriminator. Extensive experiments on GLUE and SQuAD datasets demonstrate both the effectiveness and the efficiency of our proposed method.
Who Should Go First? A Self-Supervised Concept Sorting Model for Improving Taxonomy Expansion
Apr 10, 2021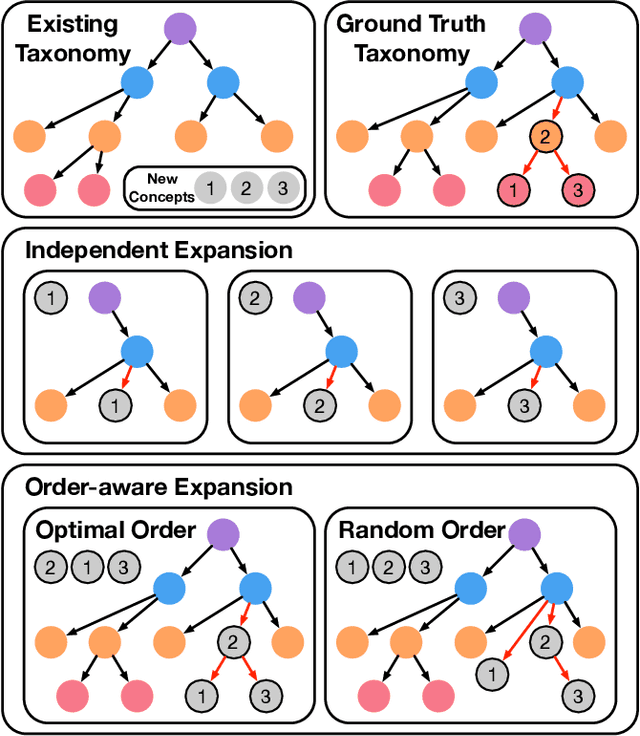
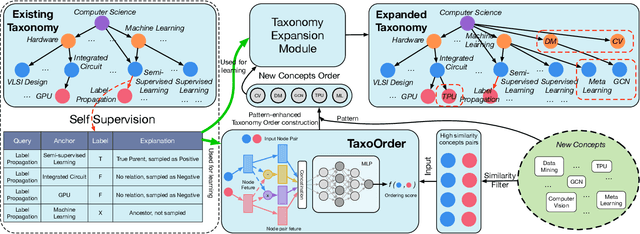
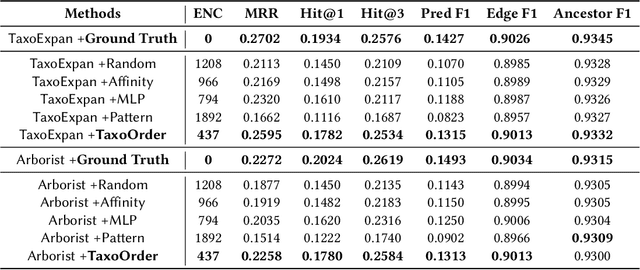
Taxonomies have been widely used in various machine learning and text mining systems to organize knowledge and facilitate downstream tasks. One critical challenge is that, as data and business scope grow in real applications, existing taxonomies need to be expanded to incorporate new concepts. Previous works on taxonomy expansion process the new concepts independently and simultaneously, ignoring the potential relationships among them and the appropriate order of inserting operations. However, in reality, the new concepts tend to be mutually correlated and form local hypernym-hyponym structures. In such a scenario, ignoring the dependencies of new concepts and the order of insertion may trigger error propagation. For example, existing taxonomy expansion systems may insert hyponyms to existing taxonomies before their hypernym, leading to sub-optimal expanded taxonomies. To complement existing taxonomy expansion systems, we propose TaxoOrder, a novel self-supervised framework that simultaneously discovers the local hypernym-hyponym structure among new concepts and decides the order of insertion. TaxoOrder can be directly plugged into any taxonomy expansion system and improve the quality of expanded taxonomies. Experiments on the real-world dataset validate the effectiveness of TaxoOrder to enhance taxonomy expansion systems, leading to better-resulting taxonomies with comparison to baselines under various evaluation metrics.
Taxonomy Completion via Triplet Matching Network
Jan 07, 2021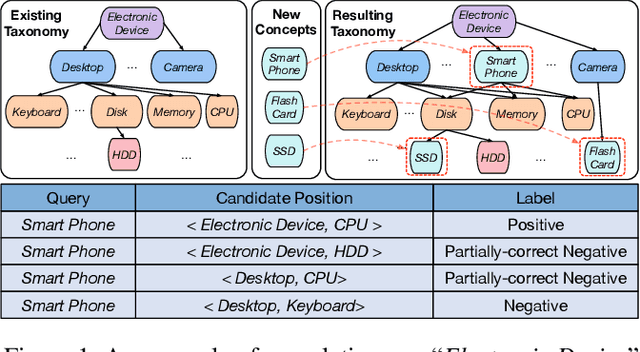
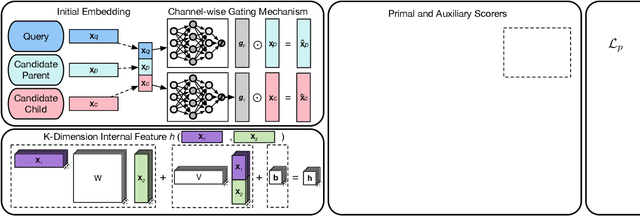
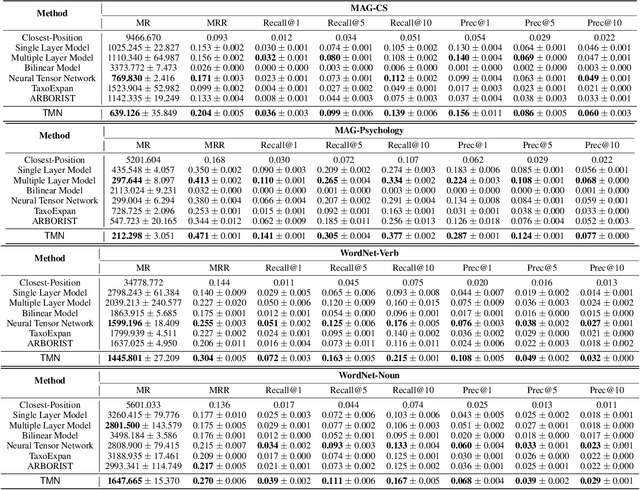
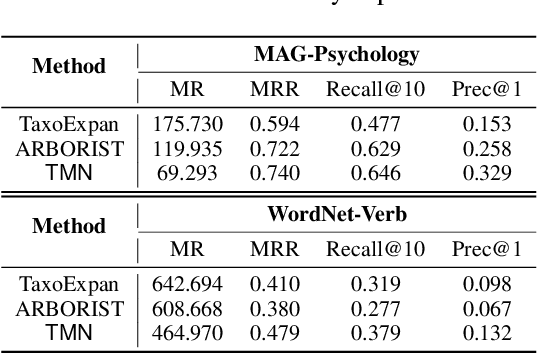
Automatically constructing taxonomy finds many applications in e-commerce and web search. One critical challenge is as data and business scope grow in real applications, new concepts are emerging and needed to be added to the existing taxonomy. Previous approaches focus on the taxonomy expansion, i.e. finding an appropriate hypernym concept from the taxonomy for a new query concept. In this paper, we formulate a new task, "taxonomy completion", by discovering both the hypernym and hyponym concepts for a query. We propose Triplet Matching Network (TMN), to find the appropriate <hypernym, hyponym> pairs for a given query concept. TMN consists of one primal scorer and multiple auxiliary scorers. These auxiliary scorers capture various fine-grained signals (e.g., query to hypernym or query to hyponym semantics), and the primal scorer makes a holistic prediction on <query, hypernym, hyponym> triplet based on the internal feature representations of all auxiliary scorers. Also, an innovative channel-wise gating mechanism that retains task-specific information in concept representations is introduced to further boost model performance. Experiments on four real-world large-scale datasets show that TMN achieves the best performance on both taxonomy completion task and the previous taxonomy expansion task, outperforming existing methods.