 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARCHI-TTS: A flow-matching-based Text-to-Speech Model with Self-supervised Semantic Aligner and Accelerated Inference
Feb 05, 2026Although diffusion-based, non-autoregressive text-to-speech (TTS) systems have demonstrated impressive zero-shot synthesis capabilities, their efficacy is still hindered by two key challenges: the difficulty of text-speech alignment modeling and the high computational overhead of the iterative denoising process. To address these limitations, we propose ARCHI-TTS that features a dedicated semantic aligner to ensure robust temporal and semantic consistency between text and audio. To overcome high computational inference costs, ARCHI-TTS employs an efficient inference strategy that reuses encoder features across denoising steps, drastically accelerating synthesis without performance degradation. An auxiliary CTC loss applied to the condition encoder further enhances the semantic understanding. Experimental results demonstrate that ARCHI-TTS achieves a WER of 1.98% on LibriSpeech-PC test-clean, and 1.47%/1.42% on SeedTTS test-en/test-zh with a high inference efficiency, consistently outperforming recent state-of-the-art TTS systems.
Environment-Aware Adaptive Pruning with Interleaved Inference Orchestration for Vision-Language-Action Models
Jan 31, 2026While Vision-Language-Action (VLA) models hold promise in embodied intelligence, their large parameter counts lead to substantial inference latency that hinders real-time manipulation, motivating parameter sparsification. However, as the environment evolves during VLA execution, the optimal sparsity patterns change accordingly. Static pruning lacks the adaptability required for environment dynamics, whereas fixed-interval dynamic layer pruning suffers from coarse granularity and high retraining overheads. To bridge this gap, we propose EcoVLA, a training-free, plug-and-play adaptive pruning framework that supports orthogonal combination with existing VLA acceleration methods. EcoVLA comprises two components: Environment-aware Adaptive Pruning (EAP) and Interleaved Inference Orchestration ($I^2O$). EAP is a lightweight adaptive channel pruning method that incorporates the temporal consistency of the physical environment to update sparsity patterns. $I^2O$ leverages the FLOPs bubbles inherent in VLA inference to schedule the pruning method in parallel, ensuring negligible impact on latency. Evaluated on diverse VLA models and benchmarks, EcoVLA delivers state-of-the-art performance, achieving up to 1.60$\times$ speedup with only a 0.4% drop in success rate, and further reaches 2.18$\times$ speedup with only a 0.5% degradation when combined with token pruning. We further validate the effectiveness of EcoVLA on real-world robots.
BookNet: Book Image Rectification via Cross-Page Attention Network
Jan 29, 2026Book image rectification presents unique challenges in document image processing due to complex geometric distortions from binding constraints, where left and right pages exhibit distinctly asymmetric curvature patterns. However, existing single-page document image rectification methods fail to capture the coupled geometric relationships between adjacent pages in books. In this work, we introduce BookNet, the first end-to-end deep learning framework specifically designed for dual-page book image rectification. BookNet adopts a dual-branch architecture with cross-page attention mechanisms, enabling it to estimate warping flows for both individual pages and the complete book spread, explicitly modeling how left and right pages influence each other. Moreover, to address the absence of specialized datasets, we present Book3D, a large-scale synthetic dataset for training, and Book100, a comprehensive real-world benchmark for evaluation. Extensive experiments demonstrate that BookNet outperforms existing state-of-the-art methods on book image rectification. Code and dataset will be made publicly available.
LISN: Language-Instructed Social Navigation with VLM-based Controller Modulating
Dec 10, 2025Towards human-robot coexistence, socially aware navigation is significant for mobile robots. Yet existing studies on this area focus mainly on path efficiency and pedestrian collision avoidance, which are essential but represent only a fraction of social navigation. Beyond these basics, robots must also comply with user instructions, aligning their actions to task goals and social norms expressed by humans. In this work, we present LISN-Bench, the first simulation-based benchmark for language-instructed social navigation. Built on Rosnav-Arena 3.0, it is the first standardized social navigation benchmark to incorporate instruction following and scene understanding across diverse contexts. To address this task, we further propose Social-Nav-Modulator, a fast-slow hierarchical system where a VLM agent modulates costmaps and controller parameters. Decoupling low-level action generation from the slower VLM loop reduces reliance on high-frequency VLM inference while improving dynamic avoidance and perception adaptability. Our method achieves an average success rate of 91.3%, which is greater than 63% than the most competitive baseline, with most of the improvements observed in challenging tasks such as following a person in a crowd and navigating while strictly avoiding instruction-forbidden regions. The project website is at: https://social-nav.github.io/LISN-project/
CLEAR: Continuous Latent Autoregressive Modeling for High-quality and Low-latency Speech Synthesis
Aug 26, 2025Autoregressive (AR) language models have emerged as powerful solutions for zero-shot text-to-speech (TTS) synthesis, capable of generating natural speech from a few seconds of audio prompts. However, conventional AR-based TTS systems relying on discrete audio tokens face the challenge of lossy compression during tokenization, requiring longer discrete token sequences to capture the same information as continuous ones, which adds inference latency and complicates AR modeling. To address this challenge, this paper proposes the Continuous Latent Autoregressive model (CLEAR), a unified zero-shot TTS framework that directly models continuous audio representations. More specifically, CLEAR introduces an enhanced variational autoencoder with shortcut connections, which achieves a high compression ratio to map waveforms into compact continuous latents. A lightweight MLP-based rectified flow head that operates independently for each hidden state is presented to model the continuous latent probability distribution, and trained jointly with the AR model within a single-stage framework. Experiments show that the proposed zero-shot CLEAR TTS can synthesize high-quality speech with low latency. Compared to state-of-the-art (SOTA) TTS models, CLEAR delivers competitive performance in robustness, speaker similarity and naturalness, while offering a lower real-time factor (RTF). In particular, CLEAR achieves SOTA results on the LibriSpeech test-clean dataset, with a word error rate of 1.88\% and an RTF of 0.29. Moreover, CLEAR facilitates streaming speech synthesis with a first-frame delay of 96ms, while maintaining high-quality speech synthesis.
VLMPlanner: Integrating Visual Language Models with Motion Planning
Jul 27, 2025Integrating large language models (LLMs) into autonomous driving motion planning has recently emerged as a promising direction, offering enhanced interpretability, better controllability, and improved generalization in rare and long-tail scenarios. However, existing methods often rely on abstracted perception or map-based inputs, missing crucial visual context, such as fine-grained road cues, accident aftermath, or unexpected obstacles, which are essential for robust decision-making in complex driving environments. To bridge this gap, we propose VLMPlanner, a hybrid framework that combines a learning-based real-time planner with a vision-language model (VLM) capable of reasoning over raw images. The VLM processes multi-view images to capture rich, detailed visual information and leverages its common-sense reasoning capabilities to guide the real-time planner in generating robust and safe trajectories. Furthermore, we develop the Context-Adaptive Inference Gate (CAI-Gate) mechanism that enables the VLM to mimic human driving behavior by dynamically adjusting its inference frequency based on scene complexity, thereby achieving an optimal balance between planning performance and computational efficiency. We evaluate our approach on the large-scale, challenging nuPlan benchmark, with comprehensive experimental results demonstrating superior planning performance in scenarios with intricate road conditions and dynamic elements. Code will be available.
MOPSA: Mixture of Prompt-Experts Based Speaker Adaptation for Elderly Speech Recognition
May 30, 2025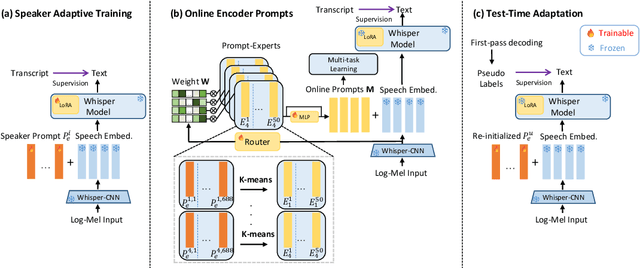
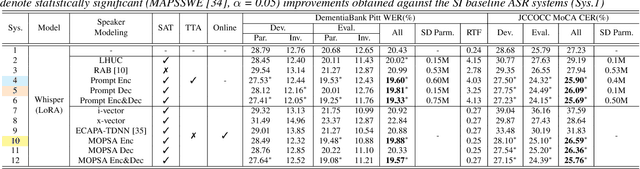
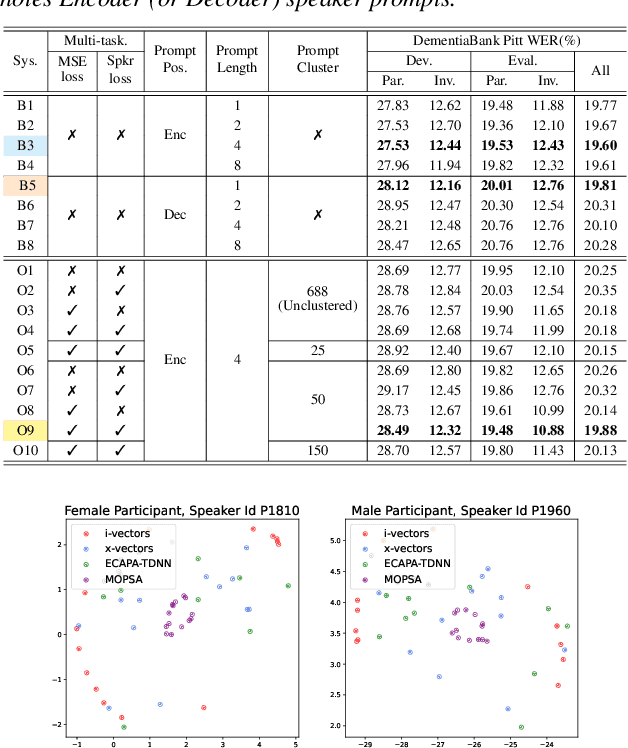
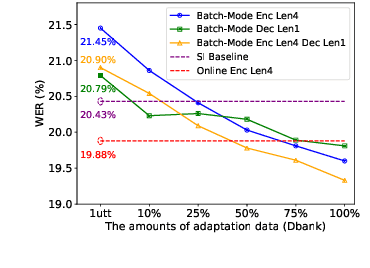
This paper proposes a novel Mixture of Prompt-Experts based Speaker Adaptation approach (MOPSA) for elderly speech recognition. It allows zero-shot, real-time adaptation to unseen speakers, and leverages domain knowledge tailored to elderly speakers. Top-K most distinctive speaker prompt clusters derived using K-means serve as experts. A router network is trained to dynamically combine clustered prompt-experts. Acoustic and language level variability among elderly speakers are modelled using separate encoder and decoder prompts for Whisper. Experiments on the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets suggest that online MOPSA adaptation outperforms the speaker-independent (SI) model by statistically significant word error rate (WER) or character error rate (CER) reductions of 0.86% and 1.47% absolute (4.21% and 5.40% relative). Real-time factor (RTF) speed-up ratios of up to 16.12 times are obtained over offline batch-mode adaptation.
SpatialSplat: Efficient Semantic 3D from Sparse Unposed Images
May 29, 2025A major breakthrough in 3D reconstruction is the feedforward paradigm to generate pixel-wise 3D points or Gaussian primitives from sparse, unposed images. To further incorporate semantics while avoiding the significant memory and storage costs of high-dimensional semantic features, existing methods extend this paradigm by associating each primitive with a compressed semantic feature vector. However, these methods have two major limitations: (a) the naively compressed feature compromises expressiveness, affecting the model's ability to capture fine-grained semantics, and (b) the pixel-wise primitive prediction introduces redundancy in overlapping areas, causing unnecessary memory overhead. To this end, we introduce \textbf{SpatialSplat}, a feedforward framework that produces redundancy-aware Gaussians and capitalizes on a dual-field semantic representation. Particularly, with the insight that primitives within the same instance exhibit high semantic consistency, we decompose the semantic representation into a coarse feature field that encodes uncompressed semantics with minimal primitives, and a fine-grained yet low-dimensional feature field that captures detailed inter-instance relationships. Moreover, we propose a selective Gaussian mechanism, which retains only essential Gaussians in the scene, effectively eliminating redundant primitives. Our proposed Spatialsplat learns accurate semantic information and detailed instances prior with more compact 3D Gaussians, making semantic 3D reconstruction more applicable. We conduct extensive experiments to evaluate our method, demonstrating a remarkable 60\% reduction in scene representation parameters while achieving superior performance over state-of-the-art methods. The code will be made available for future investigation.
On-the-fly Routing for Zero-shot MoE Speaker Adaptation of Speech Foundation Models for Dysarthric Speech Recognition
May 28, 2025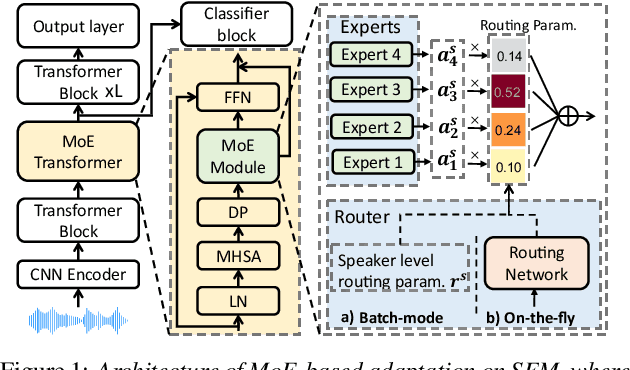
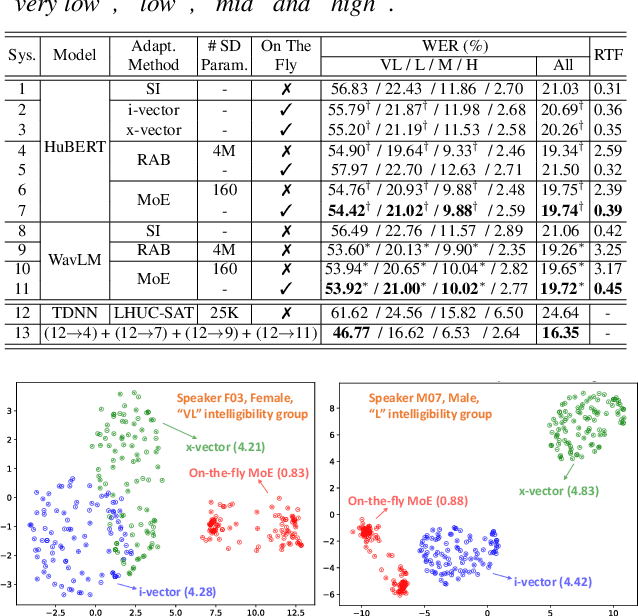
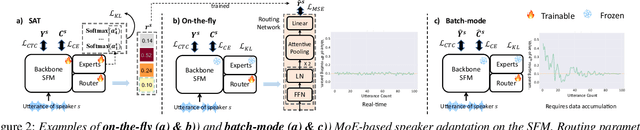

This paper proposes a novel MoE-based speaker adaptation framework for foundation models based dysarthric speech recognition. This approach enables zero-shot adaptation and real-time processing while incorporating domain knowledge. Speech impairment severity and gender conditioned adapter experts are dynamically combined using on-the-fly predicted speaker-dependent routing parameters. KL-divergence is used to further enforce diversity among experts and their generalization to unseen speakers. Experimental results on the UASpeech corpus suggest that on-the-fly MoE-based adaptation produces statistically significant WER reductions of up to 1.34% absolute (6.36% relative) over the unadapted baseline HuBERT/WavLM models. Consistent WER reductions of up to 2.55% absolute (11.44% relative) and RTF speedups of up to 7 times are obtained over batch-mode adaptation across varying speaker-level data quantities. The lowest published WER of 16.35% (46.77% on very low intelligibility) is obtained.
Hierarchical Masked Autoregressive Models with Low-Resolution Token Pivots
May 26, 2025Autoregressive models have emerged as a powerful generative paradigm for visual generation. The current de-facto standard of next token prediction commonly operates over a single-scale sequence of dense image tokens, and is incapable of utilizing global context especially for early tokens prediction. In this paper, we introduce a new autoregressive design to model a hierarchy from a few low-resolution image tokens to the typical dense image tokens, and delve into a thorough hierarchical dependency across multi-scale image tokens. Technically, we present a Hierarchical Masked Autoregressive models (Hi-MAR) that pivot on low-resolution image tokens to trigger hierarchical autoregressive modeling in a multi-phase manner. Hi-MAR learns to predict a few image tokens in low resolution, functioning as intermediary pivots to reflect global structure, in the first phase. Such pivots act as the additional guidance to strengthen the next autoregressive modeling phase by shaping global structural awareness of typical dense image tokens. A new Diffusion Transformer head is further devised to amplify the global context among all tokens for mask token prediction. Extensive evaluations on both class-conditional and text-to-image generation tasks demonstrate that Hi-MAR outperforms typical AR baselines, while requiring fewer computational costs. Code is available at https://github.com/HiDream-ai/himar.