 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Networks for Image and Video Synthesis: Algorithms and Applications
Aug 06, 2020
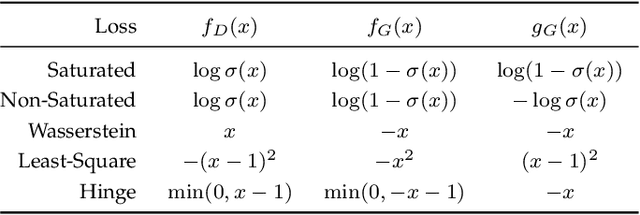

The generative adversarial network (GAN) framework has emerged as a powerful tool for various image and video synthesis tasks, allowing the synthesis of visual content in an unconditional or input-conditional manner. It has enabled the generation of high-resolution photorealistic images and videos, a task that was challenging or impossible with prior methods. It has also led to the creation of many new applications in content creation. In this paper, we provide an overview of GANs with a special focus on algorithms and applications for visual synthesis. We cover several important techniques to stabilize GAN training, which has a reputation for being notoriously difficult. We also discuss its applications to image translation, image processing, video synthesis, and neural rendering.
Cross-Supervised Object Detection
Jun 29, 2020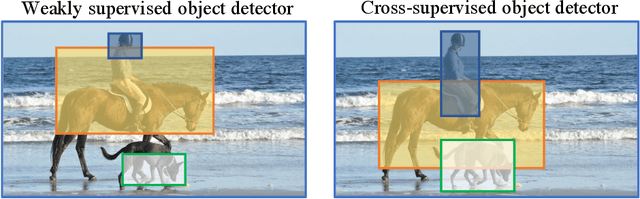
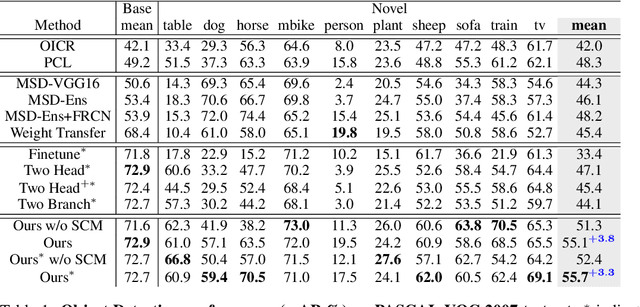
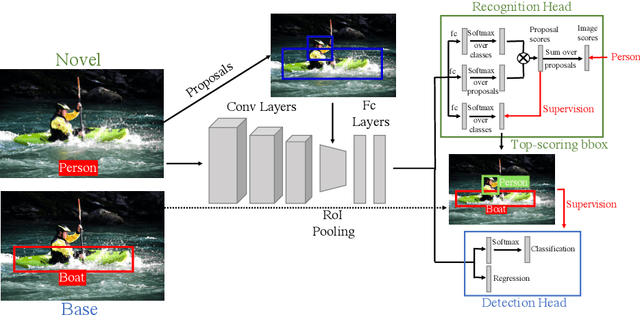
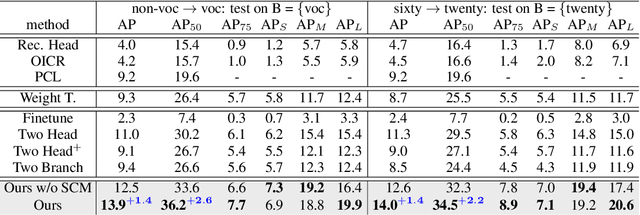
After learning a new object category from image-level annotations (with no object bounding boxes), humans are remarkably good at precisely localizing those objects. However, building good object localizers (i.e., detectors) currently requires expensive instance-level annotations. While some work has been done on learning detectors from weakly labeled samples (with only class labels), these detectors do poorly at localization. In this work, we show how to build better object detectors from weakly labeled images of new categories by leveraging knowledge learned from fully labeled base categories. We call this novel learning paradigm cross-supervised object detection. We propose a unified framework that combines a detection head trained from instance-level annotations and a recognition head learned from image-level annotations, together with a spatial correlation module that bridges the gap between detection and recognition. These contributions enable us to better detect novel objects with image-level annotations in complex multi-object scenes such as the COCO dataset.
Neural Sparse Representation for Image Restoration
Jun 08, 2020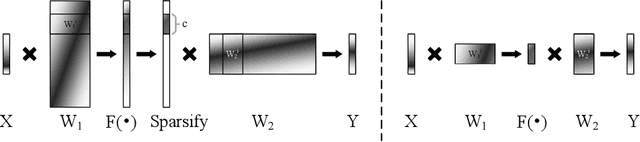
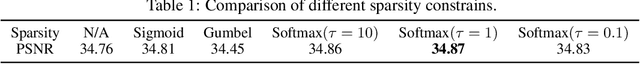

Inspired by the robustness and efficiency of sparse representation in sparse coding based image restoration models, we investigate the sparsity of neurons in deep networks. Our method structurally enforces sparsity constraints upon hidden neurons. The sparsity constraints are favorable for gradient-based learning algorithms and attachable to convolution layers in various networks. Sparsity in neurons enables computation saving by only operating on non-zero components without hurting accuracy. Meanwhile, our method can magnify representation dimensionality and model capacity with negligible additional computation cost. Experiments show that sparse representation is crucial in deep neural networks for multiple image restoration tasks, including image super-resolution, image denoising, and image compression artifacts removal. Code is available at https://github.com/ychfan/nsr
Pyramid Attention Networks for Image Restoration
Jun 03, 2020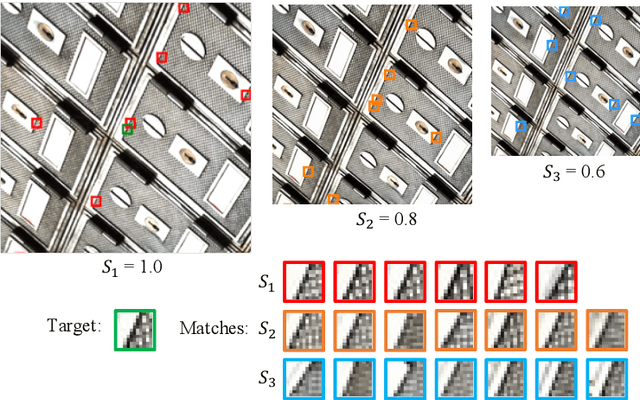
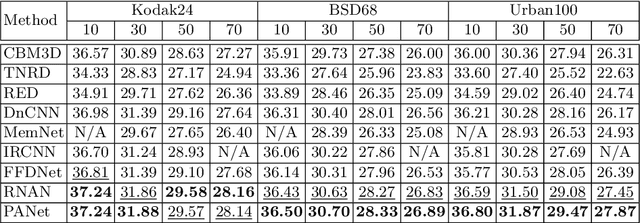
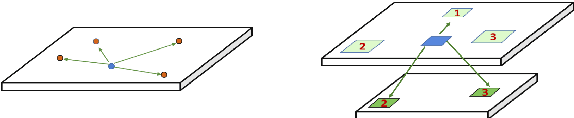
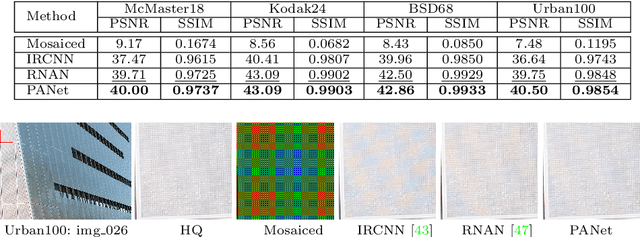
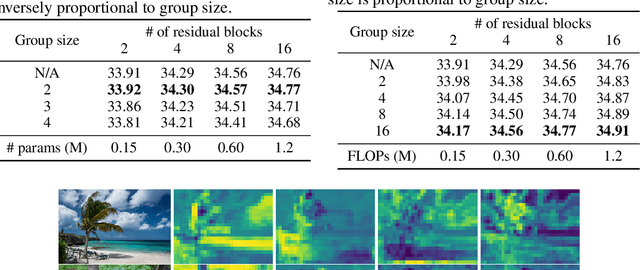
Self-similarity refers to the image prior widely used in image restoration algorithms that small but similar patterns tend to occur at different locations and scales. However, recent advanced deep convolutional neural network based methods for image restoration do not take full advantage of self-similarities by relying on self-attention neural modules that only process information at the same scale. To solve this problem, we present a novel Pyramid Attention module for image restoration, which captures long-range feature correspondences from a multi-scale feature pyramid. Inspired by the fact that corruptions, such as noise or compression artifacts, drop drastically at coarser image scales, our attention module is designed to be able to borrow clean signals from their "clean" correspondences at the coarser levels. The proposed pyramid attention module is a generic building block that can be flexibly integrated into various neural architectures. Its effectiveness is validated through extensive experiments on multiple image restoration tasks: image denoising, demosaicing, compression artifact reduction, and super resolution. Without any bells and whistles, our PANet (pyramid attention module with simple network backbones) can produce state-of-the-art results with superior accuracy and visual quality. Our code will be available at https://github.com/SHI-Labs/Pyramid-Attention-Networks
Dynamic Sparsity Neural Networks for Automatic Speech Recognition
May 16, 2020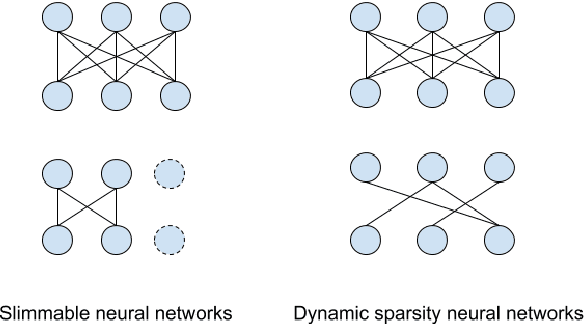
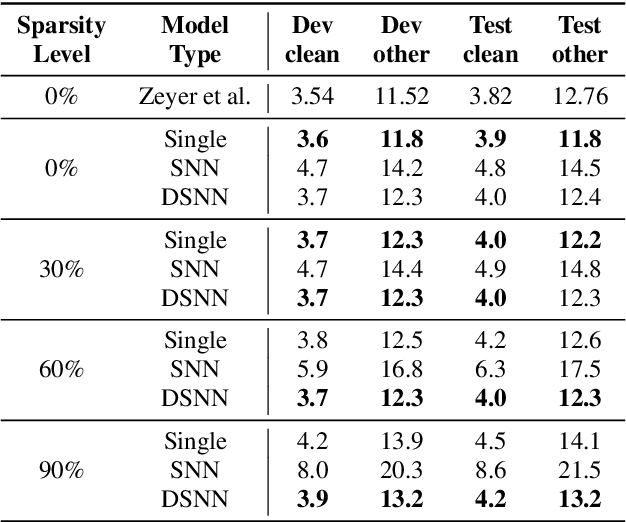
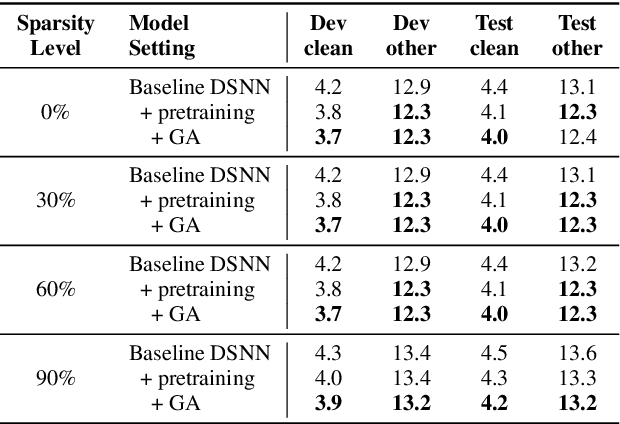
In automatic speech recognition (ASR), model pruning is a widely adopted technique that reduces model size and latency to deploy neural network models on edge devices with resource constraints. However, in order to optimize for hardware with different resource specifications and for applications that have various latency requirements, models with varying sparsity levels usually need to be trained and deployed separately. In this paper, generalizing from slimmable neural networks, we present dynamic sparsity neural networks (DSNN) that, once trained, can instantly switch to execute at any given sparsity level at run-time. We show the efficacy of such models on ASR through comprehensive experiments and demonstrate that the performance of a dynamic sparsity model is on par with, and in some cases exceeds, the performance of individually trained single sparsity networks. A trained DSNN model can therefore greatly ease the training process and simplifies deployment in diverse scenarios with resource constraints.
Conformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020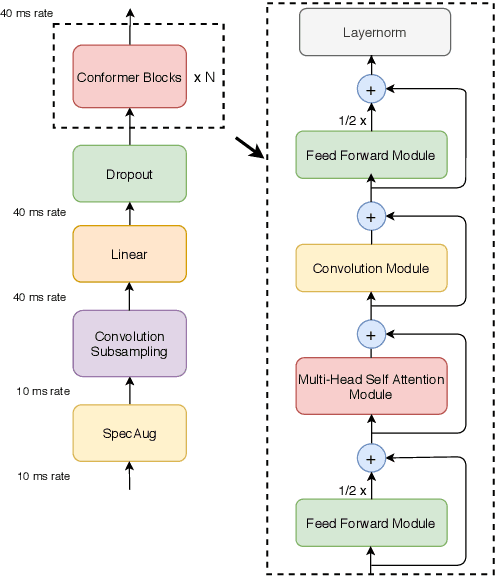
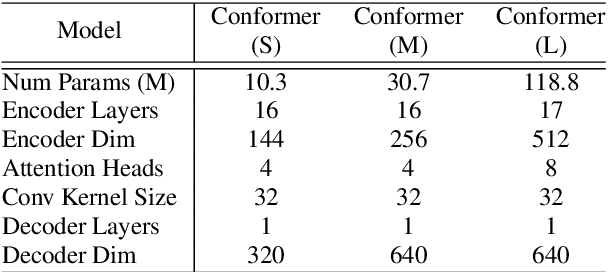

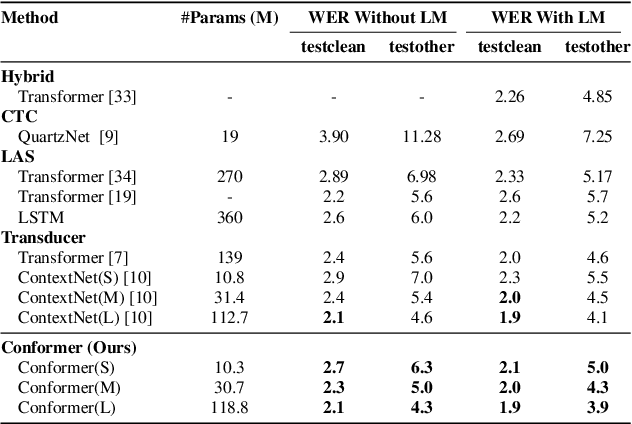
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 16, 2020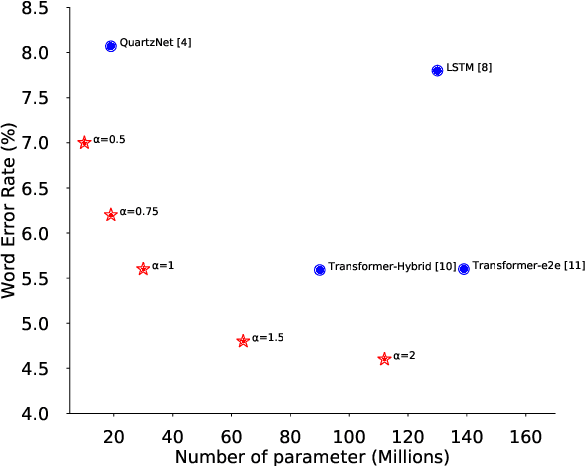
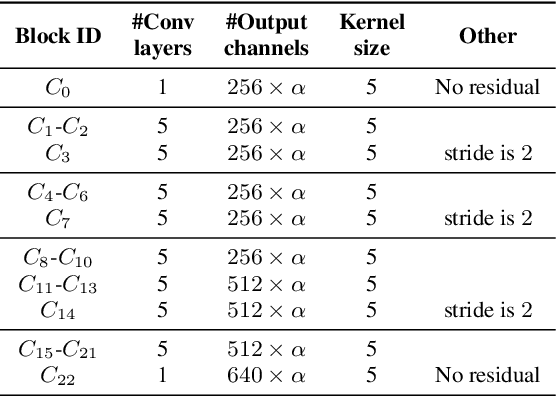
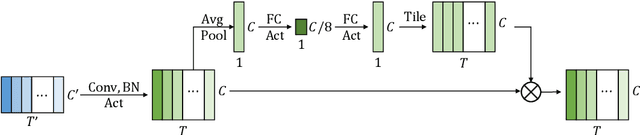
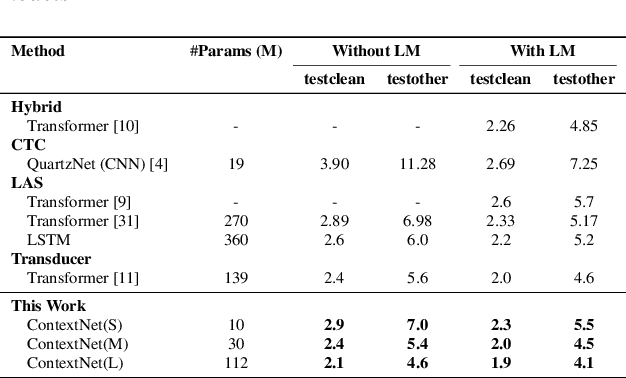
Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1%/4.6% without external language model (LM), 1.9%/4.1% with LM and 2.9%/7.0% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0%/4.6% with LM and 3.9%/11.3% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Mar 24, 2020
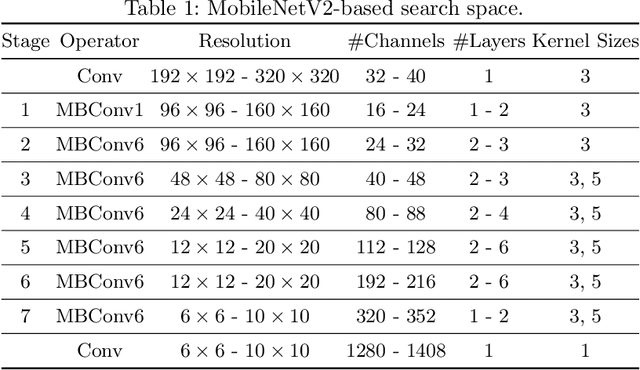
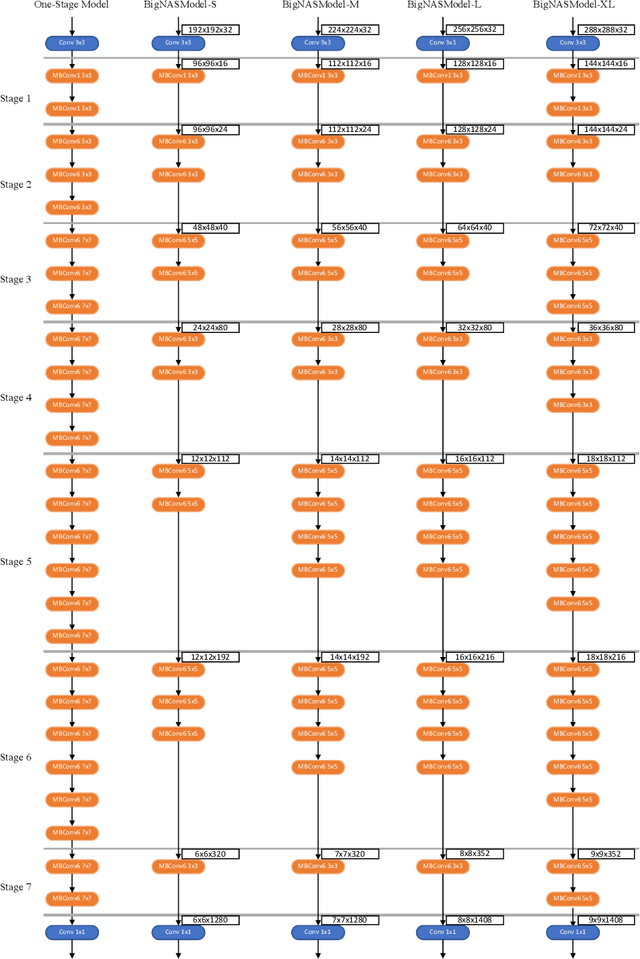
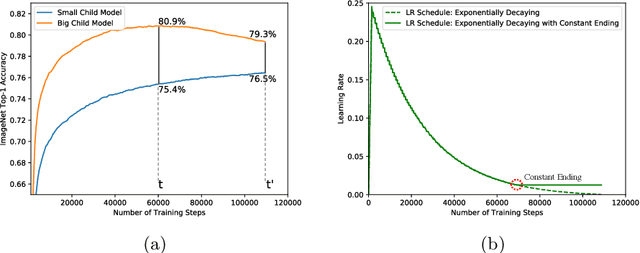
Neural architecture search (NAS) has shown promising results discovering models that are both accurate and fast. For NAS, training a one-shot model has become a popular strategy to rank the relative quality of different architectures (child models) using a single set of shared weights. However, while one-shot model weights can effectively rank different network architectures, the absolute accuracies from these shared weights are typically far below those obtained from stand-alone training. To compensate, existing methods assume that the weights must be retrained, finetuned, or otherwise post-processed after the search is completed. These steps significantly increase the compute requirements and complexity of the architecture search and model deployment. In this work, we propose BigNAS, an approach that challenges the conventional wisdom that post-processing of the weights is necessary to get good prediction accuracies. Without extra retraining or post-processing steps, we are able to train a single set of shared weights on ImageNet and use these weights to obtain child models whose sizes range from 200 to 1000 MFLOPs. Our discovered model family, BigNASModels, achieve top-1 accuracies ranging from 76.5% to 80.9%, surpassing state-of-the-art models in this range including EfficientNets and Once-for-All networks without extra retraining or post-processing. We present ablative study and analysis to further understand the proposed BigNASModels.
Scale-wise Convolution for Image Restoration
Dec 19, 2019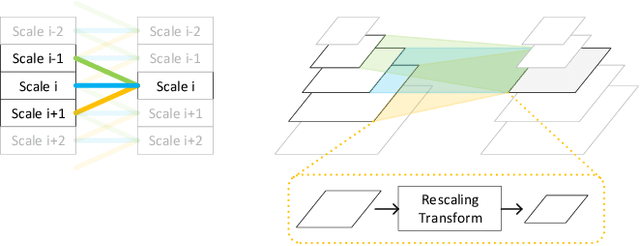
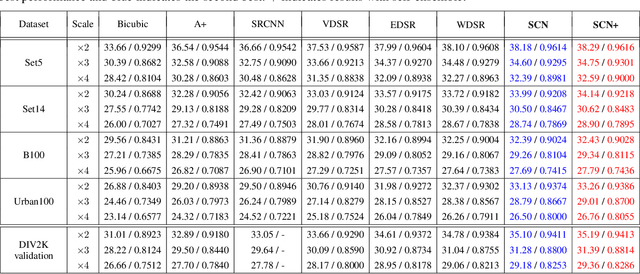
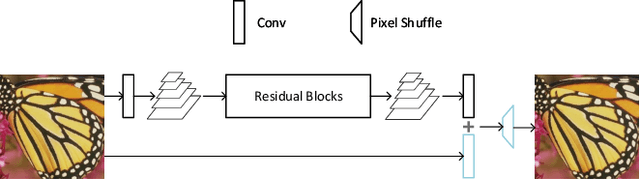
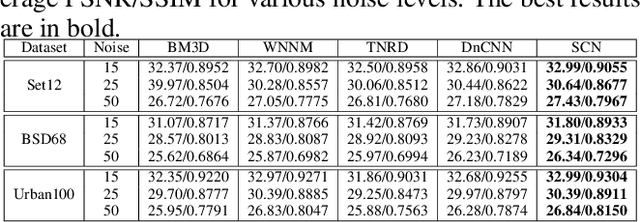
While scale-invariant modeling has substantially boosted the performance of visual recognition tasks, it remains largely under-explored in deep networks based image restoration. Naively applying those scale-invariant techniques (e.g. multi-scale testing, random-scale data augmentation) to image restoration tasks usually leads to inferior performance. In this paper, we show that properly modeling scale-invariance into neural networks can bring significant benefits to image restoration performance. Inspired from spatial-wise convolution for shift-invariance, "scale-wise convolution" is proposed to convolve across multiple scales for scale-invariance. In our scale-wise convolutional network (SCN), we first map the input image to the feature space and then build a feature pyramid representation via bi-linear down-scaling progressively. The feature pyramid is then passed to a residual network with scale-wise convolutions. The proposed scale-wise convolution learns to dynamically activate and aggregate features from different input scales in each residual building block, in order to exploit contextual information on multiple scales. In experiments, we compare the restoration accuracy and parameter efficiency among our model and many different variants of multi-scale neural networks. The proposed network with scale-wise convolution achieves superior performance in multiple image restoration tasks including image super-resolution, image denoising and image compression artifacts removal. Code and models are available at: https://github.com/ychfan/scn_sr
Adversarial-Based Knowledge Distillation for Multi-Model Ensemble and Noisy Data Refinement
Aug 22, 2019
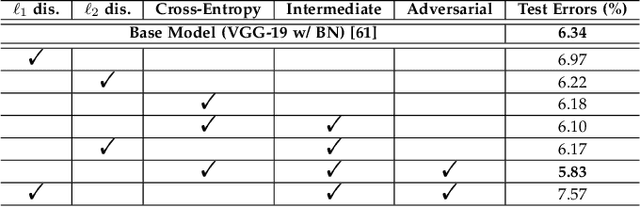
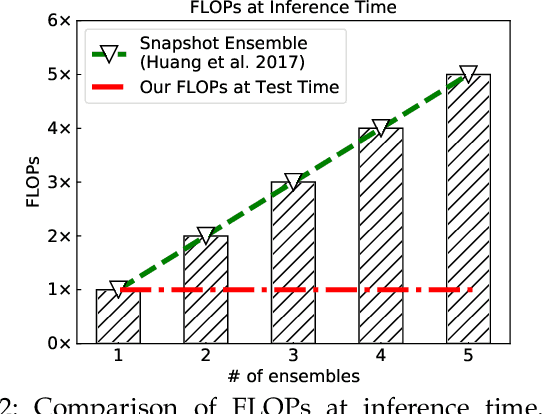
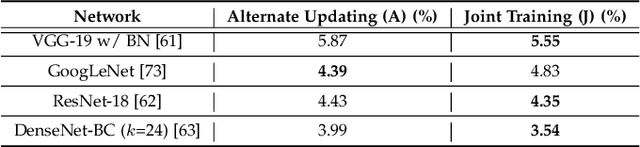
Generic Image recognition is a fundamental and fairly important visual problem in computer vision. One of the major challenges of this task lies in the fact that single image usually has multiple objects inside while the labels are still one-hot, another one is noisy and sometimes missing labels when annotated by humans. In this paper, we focus on tackling these challenges accompanying with two different image recognition problems: multi-model ensemble and noisy data recognition with a unified framework. As is well-known, usually the best performing deep neural models are ensembles of multiple base-level networks, as it can mitigate the variation or noise containing in the dataset. Unfortunately, the space required to store these many networks, and the time required to execute them at runtime, prohibit their use in applications where test sets are large (e.g., ImageNet). In this paper, we present a method for compressing large, complex trained ensembles into a single network, where the knowledge from a variety of trained deep neural networks (DNNs) is distilled and transferred to a single DNN. In order to distill diverse knowledge from different trained (teacher) models, we propose to use adversarial-based learning strategy where we define a block-wise training loss to guide and optimize the predefined student network to recover the knowledge in teacher models, and to promote the discriminator network to distinguish teacher vs. student features simultaneously. Extensive experiments on CIFAR-10/100, SVHN, ImageNet and iMaterialist Challenge Dataset demonstrate the effectiveness of our MEAL method. On ImageNet, our ResNet-50 based MEAL achieves top-1/5 21.79%/5.99% val error, which outperforms the original model by 2.06%/1.14%. On iMaterialist Challenge Dataset, our MEAL obtains a remarkable improvement of top-3 1.15% (official evaluation metric) on a strong baseline model of ResNet-101.