 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop
May 18, 2026Spatial intelligence unfolds through a perception-action loop: agents act to acquire observations, and reason about how observations vary as a function of action. Rather than passively processing what is seen, they actively uncover what is unseen - occluded structure, dynamics, containment, and functionality that cannot be resolved from passive sensing alone. We move beyond prior formulations of spatial intelligence that assume oracle observations by recasting the observer as an actor. We introduce ESI-BENCH, a comprehensive benchmark for embodied spatial intelligence spanning 10 task categories and 29 subcategories built on OmniGibson, grounded in Spelke's core knowledge systems. Agents must decide what abilities to deploy - perception, locomotion, and manipulation - and how to sequence them to actively accumulate task-relevant evidence. We conduct extensive experiments on state-of-the-art MLLMs and find that active exploration substantially outperforms passive counterparts, with agents spontaneously discovering emergent spatial strategies without explicit instructions, while random multi-view often adds noise rather than signal despite consuming far more images. Most failures stem not from weak perception but from action blindness: poor action choices lead to poor observations, which in turn drive cascading errors. While explicit 3D grounding stabilizes reasoning on depth-sensitive tasks, imperfect 3D representation proves more harmful than 2D baselines by distorting spatial relations. Human studies further reveal that unlike humans who seek falsifying viewpoints and revise beliefs under contradiction, models commit prematurely with high confidence regardless of evidence quality, exposing a metacognitive gap that neither better perception nor more embodied interaction alone can close.
Edit3r: Instant 3D Scene Editing from Sparse Unposed Images
Dec 31, 2025We present Edit3r, a feed-forward framework that reconstructs and edits 3D scenes in a single pass from unposed, view-inconsistent, instruction-edited images. Unlike prior methods requiring per-scene optimization, Edit3r directly predicts instruction-aligned 3D edits, enabling fast and photorealistic rendering without optimization or pose estimation. A key challenge in training such a model lies in the absence of multi-view consistent edited images for supervision. We address this with (i) a SAM2-based recoloring strategy that generates reliable, cross-view-consistent supervision, and (ii) an asymmetric input strategy that pairs a recolored reference view with raw auxiliary views, encouraging the network to fuse and align disparate observations. At inference, our model effectively handles images edited by 2D methods such as InstructPix2Pix, despite not being exposed to such edits during training. For large-scale quantitative evaluation, we introduce DL3DV-Edit-Bench, a benchmark built on the DL3DV test split, featuring 20 diverse scenes, 4 edit types and 100 edits in total. Comprehensive quantitative and qualitative results show that Edit3r achieves superior semantic alignment and enhanced 3D consistency compared to recent baselines, while operating at significantly higher inference speed, making it promising for real-time 3D editing applications.
Virtual Community: An Open World for Humans, Robots, and Society
Aug 20, 2025



The rapid progress in AI and Robotics may lead to a profound societal transformation, as humans and robots begin to coexist within shared communities, introducing both opportunities and challenges. To explore this future, we present Virtual Community-an open-world platform for humans, robots, and society-built on a universal physics engine and grounded in real-world 3D scenes. With Virtual Community, we aim to study embodied social intelligence at scale: 1) How robots can intelligently cooperate or compete; 2) How humans develop social relations and build community; 3) More importantly, how intelligent robots and humans can co-exist in an open world. To support these, Virtual Community features: 1) An open-source multi-agent physics simulator that supports robots, humans, and their interactions within a society; 2) A large-scale, real-world aligned community generation pipeline, including vast outdoor space, diverse indoor scenes, and a community of grounded agents with rich characters and appearances. Leveraging Virtual Community, we propose two novel challenges. The Community Planning Challenge evaluates multi-agent reasoning and planning ability in open-world settings, such as cooperating to help agents with daily activities and efficiently connecting other agents. The Community Robot Challenge requires multiple heterogeneous robots to collaborate in solving complex open-world tasks. We evaluate various baselines on these tasks and demonstrate the challenges in both high-level open-world task planning and low-level cooperation controls. We hope that Virtual Community will unlock further study of human-robot coexistence within open-world environments.
Architect: Generating Vivid and Interactive 3D Scenes with Hierarchical 2D Inpainting
Nov 14, 2024



Creating large-scale interactive 3D environments is essential for the development of Robotics and Embodied AI research. Current methods, including manual design, procedural generation, diffusion-based scene generation, and large language model (LLM) guided scene design, are hindered by limitations such as excessive human effort, reliance on predefined rules or training datasets, and limited 3D spatial reasoning ability. Since pre-trained 2D image generative models better capture scene and object configuration than LLMs, we address these challenges by introducing Architect, a generative framework that creates complex and realistic 3D embodied environments leveraging diffusion-based 2D image inpainting. In detail, we utilize foundation visual perception models to obtain each generated object from the image and leverage pre-trained depth estimation models to lift the generated 2D image to 3D space. Our pipeline is further extended to a hierarchical and iterative inpainting process to continuously generate placement of large furniture and small objects to enrich the scene. This iterative structure brings the flexibility for our method to generate or refine scenes from various starting points, such as text, floor plans, or pre-arranged environments.
Connecting Multi-modal Contrastive Representations
May 22, 2023



Multi-modal Contrastive Representation (MCR) learning aims to encode different modalities into a semantically aligned shared space. This paradigm shows remarkable generalization ability on numerous downstream tasks across various modalities. However, the reliance on massive high-quality data pairs limits its further development on more modalities. This paper proposes a novel training-efficient method for learning MCR without paired data called Connecting Multi-modal Contrastive Representations (C-MCR). Specifically, given two existing MCRs pre-trained on (A, B) and (B, C) modality pairs, we project them to a new space and use the data from the overlapping modality B to aligning the two MCRs in the new space. Meanwhile, since the modality pairs (A, B) and (B, C) are already aligned within each MCR, the connection learned by overlapping modality can also be transferred to non-overlapping modality pair (A, C). To unleash the potential of C-MCR, we further introduce a semantic-enhanced inter- and intra-MCR connection method. We first enhance the semantic consistency and completion of embeddings across different modalities for more robust alignment. Then we utilize the inter-MCR alignment to establish the connection, and employ the intra-MCR alignment to better maintain the connection for inputs from non-overlapping modalities. We take the field of audio-visual contrastive learning as an example to demonstrate the effectiveness of C-MCR. We connect pre-trained CLIP and CLAP models via texts to derive audio-visual contrastive representations. Remarkably, without using any paired audio-visual data and further tuning, C-MCR achieves state-of-the-art performance on six datasets across three audio-visual downstream tasks.
Variance-Reduced Stochastic Learning by Networked Agents under Random Reshuffling
May 29, 2018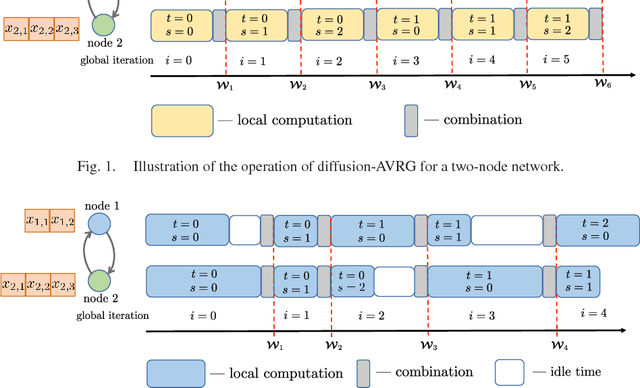

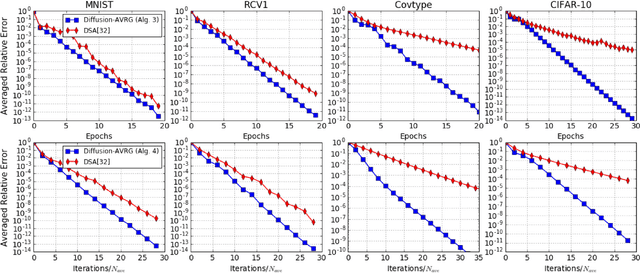
A new amortized variance-reduced gradient (AVRG) algorithm was developed in \cite{ying2017convergence}, which has constant storage requirement in comparison to SAGA and balanced gradient computations in comparison to SVRG. One key advantage of the AVRG strategy is its amenability to decentralized implementations. In this work, we show how AVRG can be extended to the network case where multiple learning agents are assumed to be connected by a graph topology. In this scenario, each agent observes data that is spatially distributed and all agents are only allowed to communicate with direct neighbors. Moreover, the amount of data observed by the individual agents may differ drastically. For such situations, the balanced gradient computation property of AVRG becomes a real advantage in reducing idle time caused by unbalanced local data storage requirements, which is characteristic of other reduced-variance gradient algorithms. The resulting diffusion-AVRG algorithm is shown to have linear convergence to the exact solution, and is much more memory efficient than other alternative algorithms. In addition, we propose a mini-batch strategy to balance the communication and computation efficiency for diffusion-AVRG. When a proper batch size is employed, it is observed in simulations that diffusion-AVRG is more computationally efficient than exact diffusion or EXTRA while maintaining almost the same communication efficiency.