 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverageBench: Evaluating Information Coverage across Tasks and Domains
Mar 20, 2026We wish to measure the information coverage of an ad hoc retrieval algorithm, that is, how much of the range of available relevant information is covered by the search results. Information coverage is a central aspect for retrieval, especially when the retrieval system is integrated with generative models in a retrieval-augmented generation (RAG) system. The classic metrics for ad hoc retrieval, precision and recall, reward a system as more and more relevant documents are retrieved. However, since relevance in ad hoc test collections is defined for a document without any relation to other documents that might contain the same information, high recall is sufficient but not necessary to ensure coverage. The same is true for other metrics such as rank-biased precision (RBP), normalized discounted cumulative gain (nDCG), and mean average precision (MAP). Test collections developed around the notion of diversity ranking in web search incorporate multiple aspects that support a concept of coverage in the web domain. In this work, we construct a suite of collections for evaluating information coverage from existing collections. This suite offers researchers a unified testbed spanning multiple genres and tasks. All topics, nuggets, relevance labels, and baseline rankings are released on Hugging Face Datasets, along with instructions for accessing the publicly available document collections.
Beyond Relevance: On the Relationship Between Retrieval and RAG Information Coverage
Mar 11, 2026Retrieval-augmented generation (RAG) systems combine document retrieval with a generative model to address complex information seeking tasks like report generation. While the relationship between retrieval quality and generation effectiveness seems intuitive, it has not been systematically studied. We investigate whether upstream retrieval metrics can serve as reliable early indicators of the final generated response's information coverage. Through experiments across two text RAG benchmarks (TREC NeuCLIR 2024 and TREC RAG 2024) and one multimodal benchmark (WikiVideo), we analyze 15 text retrieval stacks and 10 multimodal retrieval stacks across four RAG pipelines and multiple evaluation frameworks (Auto-ARGUE and MiRAGE). Our findings demonstrate strong correlations between coverage-based retrieval metrics and nugget coverage in generated responses at both topic and system levels. This relationship holds most strongly when retrieval objectives align with generation goals, though more complex iterative RAG pipelines can partially decouple generation quality from retrieval effectiveness. These findings provide empirical support for using retrieval metrics as proxies for RAG performance.
Lessons from the TREC Plain Language Adaptation of Biomedical Abstracts (PLABA) track
Jul 18, 2025
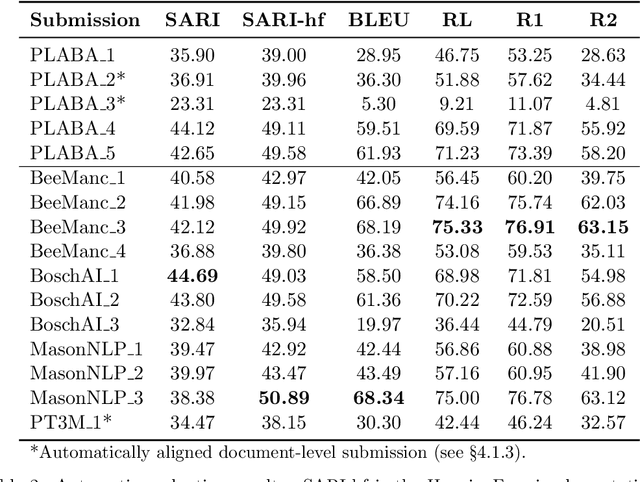
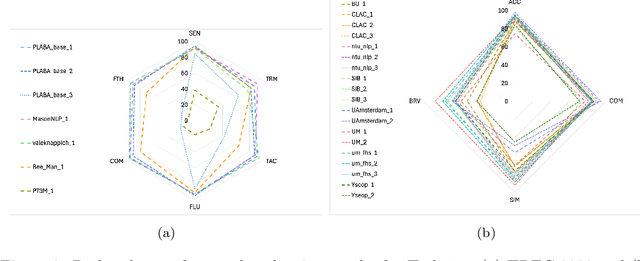
Objective: Recent advances in language models have shown potential to adapt professional-facing biomedical literature to plain language, making it accessible to patients and caregivers. However, their unpredictability, combined with the high potential for harm in this domain, means rigorous evaluation is necessary. Our goals with this track were to stimulate research and to provide high-quality evaluation of the most promising systems. Methods: We hosted the Plain Language Adaptation of Biomedical Abstracts (PLABA) track at the 2023 and 2024 Text Retrieval Conferences. Tasks included complete, sentence-level, rewriting of abstracts (Task 1) as well as identifying and replacing difficult terms (Task 2). For automatic evaluation of Task 1, we developed a four-fold set of professionally-written references. Submissions for both Tasks 1 and 2 were provided extensive manual evaluation from biomedical experts. Results: Twelve teams spanning twelve countries participated in the track, with models from multilayer perceptrons to large pretrained transformers. In manual judgments of Task 1, top-performing models rivaled human levels of factual accuracy and completeness, but not simplicity or brevity. Automatic, reference-based metrics generally did not correlate well with manual judgments. In Task 2, systems struggled with identifying difficult terms and classifying how to replace them. When generating replacements, however, LLM-based systems did well in manually judged accuracy, completeness, and simplicity, though not in brevity. Conclusion: The PLABA track showed promise for using Large Language Models to adapt biomedical literature for the general public, while also highlighting their deficiencies and the need for improved automatic benchmarking tools.
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look
Nov 13, 2024The application of large language models to provide relevance assessments presents exciting opportunities to advance information retrieval, natural language processing, and beyond, but to date many unknowns remain. This paper reports on the results of a large-scale evaluation (the TREC 2024 RAG Track) where four different relevance assessment approaches were deployed in situ: the "standard" fully manual process that NIST has implemented for decades and three different alternatives that take advantage of LLMs to different extents using the open-source UMBRELA tool. This setup allows us to correlate system rankings induced by the different approaches to characterize tradeoffs between cost and quality. We find that in terms of nDCG@20, nDCG@100, and Recall@100, system rankings induced by automatically generated relevance assessments from UMBRELA correlate highly with those induced by fully manual assessments across a diverse set of 77 runs from 19 teams. Our results suggest that automatically generated UMBRELA judgments can replace fully manual judgments to accurately capture run-level effectiveness. Surprisingly, we find that LLM assistance does not appear to increase correlation with fully manual assessments, suggesting that costs associated with human-in-the-loop processes do not bring obvious tangible benefits. Overall, human assessors appear to be stricter than UMBRELA in applying relevance criteria. Our work validates the use of LLMs in academic TREC-style evaluations and provides the foundation for future studies.
QueryBuilder: Human-in-the-Loop Query Development for Information Retrieval
Sep 10, 2024Frequently, users of an Information Retrieval (IR) system start with an overarching information need (a.k.a., an analytic task) and proceed to define finer-grained queries covering various important aspects (i.e., sub-topics) of that analytic task. We present a novel, interactive system called $\textit{QueryBuilder}$, which allows a novice, English-speaking user to create queries with a small amount of effort, through efficient exploration of an English development corpus in order to rapidly develop cross-lingual information retrieval queries corresponding to the user's information needs. QueryBuilder performs near real-time retrieval of documents based on user-entered search terms; the user looks through the retrieved documents and marks sentences as relevant to the information needed. The marked sentences are used by the system as additional information in query formation and refinement: query terms (and, optionally, event features, which capture event $'triggers'$ (indicator terms) and agent/patient roles) are appropriately weighted, and a neural-based system, which better captures textual meaning, retrieves other relevant content. The process of retrieval and marking is repeated as many times as desired, giving rise to increasingly refined queries in each iteration. The final product is a fine-grained query used in Cross-Lingual Information Retrieval (CLIR). Our experiments using analytic tasks and requests from the IARPA BETTER IR datasets show that with a small amount of effort (at most 10 minutes per sub-topic), novice users can form $\textit{useful}$ fine-grained queries including in languages they don't understand. QueryBuilder also provides beneficial capabilities to the traditional corpus exploration and query formation process. A demonstration video is released at https://vimeo.com/734795835
Breaking Boundaries: Investigating the Effects of Model Editing on Cross-linguistic Performance
Jun 17, 2024The integration of pretrained language models (PLMs) like BERT and GPT has revolutionized NLP, particularly for English, but it has also created linguistic imbalances. This paper strategically identifies the need for linguistic equity by examining several knowledge editing techniques in multilingual contexts. We evaluate the performance of models such as Mistral, TowerInstruct, OpenHathi, Tamil-Llama, and Kan-Llama across languages including English, German, French, Italian, Spanish, Hindi, Tamil, and Kannada. Our research identifies significant discrepancies in normal and merged models concerning cross-lingual consistency. We employ strategies like 'each language for itself' (ELFI) and 'each language for others' (ELFO) to stress-test these models. Our findings demonstrate the potential for LLMs to overcome linguistic barriers, laying the groundwork for future research in achieving linguistic inclusivity in AI technologies.
On the Evaluation of Machine-Generated Reports
May 02, 2024



Large Language Models (LLMs) have enabled new ways to satisfy information needs. Although great strides have been made in applying them to settings like document ranking and short-form text generation, they still struggle to compose complete, accurate, and verifiable long-form reports. Reports with these qualities are necessary to satisfy the complex, nuanced, or multi-faceted information needs of users. In this perspective paper, we draw together opinions from industry and academia, and from a variety of related research areas, to present our vision for automatic report generation, and -- critically -- a flexible framework by which such reports can be evaluated. In contrast with other summarization tasks, automatic report generation starts with a detailed description of an information need, stating the necessary background, requirements, and scope of the report. Further, the generated reports should be complete, accurate, and verifiable. These qualities, which are desirable -- if not required -- in many analytic report-writing settings, require rethinking how to build and evaluate systems that exhibit these qualities. To foster new efforts in building these systems, we present an evaluation framework that draws on ideas found in various evaluations. To test completeness and accuracy, the framework uses nuggets of information, expressed as questions and answers, that need to be part of any high-quality generated report. Additionally, evaluation of citations that map claims made in the report to their source documents ensures verifiability.
Corrected Evaluation Results of the NTCIR WWW-2, WWW-3, and WWW-4 English Subtasks
Oct 19, 2022
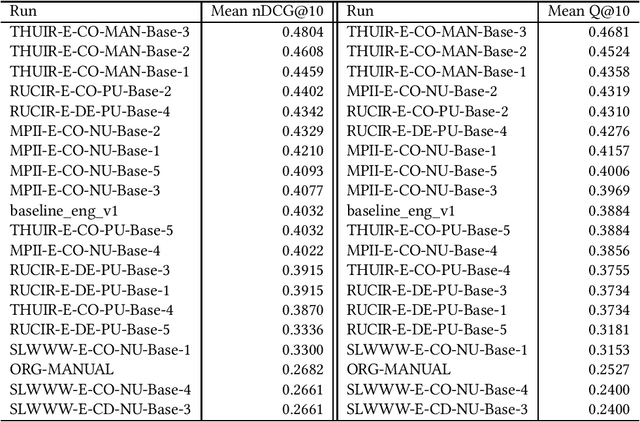
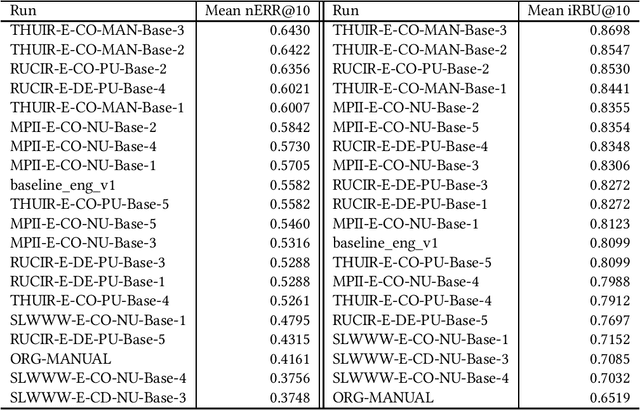

Unfortunately, the official English (sub)task results reported in the NTCIR-14 WWW-2, NTCIR-15 WWW-3, and NTCIR-16 WWW-4 overview papers are incorrect due to noise in the official qrels files; this paper reports results based on the corrected qrels files. The noise is due to a fatal bug in the backend of our relevance assessment interface. More specifically, at WWW-2, WWW-3, and WWW-4, two versions of pool files were created for each English topic: a PRI ("prioritised") file, which uses the NTCIRPOOL script to prioritise likely relevant documents, and a RND ("randomised") file, which randomises the pooled documents. This was done for the purpose of studying the effect of document ordering for relevance assessors. However, the programmer who wrote the interface backend assumed that a combination of a topic ID and a document rank in the pool file uniquely determines a document ID; this is obviously incorrect as we have two versions of pool files. The outcome is that all the PRI-based relevance labels for the WWW-2 test collection are incorrect (while all the RND-based relevance labels are correct), and all the RND-based relevance labels for the WWW-3 and WWW-4 test collections are incorrect (while all the PRI-based relevance labels are correct). This bug was finally discovered at the NTCIR-16 WWW-4 task when the first seven authors of this paper served as Gold assessors (i.e., topic creators who define what is relevant) and closely examined the disagreements with Bronze assessors (i.e., non-topic-creators; non-experts). We would like to apologise to the WWW participants and the NTCIR chairs for the inconvenience and confusion caused due to this bug.
Can Old TREC Collections Reliably Evaluate Modern Neural Retrieval Models?
Jan 26, 2022Neural retrieval models are generally regarded as fundamentally different from the retrieval techniques used in the late 1990's when the TREC ad hoc test collections were constructed. They thus provide the opportunity to empirically test the claim that pooling-built test collections can reliably evaluate retrieval systems that did not contribute to the construction of the collection (in other words, that such collections can be reusable). To test the reusability claim, we asked TREC assessors to judge new pools created from new search results for the TREC-8 ad hoc collection. These new search results consisted of five new runs (one each from three transformer-based models and two baseline runs that use BM25) plus the set of TREC-8 submissions that did not previously contribute to pools. The new runs did retrieve previously unseen documents, but the vast majority of those documents were not relevant. The ranking of all runs by mean evaluation score when evaluated using the official TREC-8 relevance judgment set and the newly expanded relevance set are almost identical, with Kendall's tau correlations greater than 0.99. Correlations for individual topics are also high. The TREC-8 ad hoc collection was originally constructed using deep pools over a diverse set of runs, including several effective manual runs. Its judgment budget, and hence construction cost, was relatively large. However, it does appear that the expense was well-spent: even with the advent of neural techniques, the collection has stood the test of time and remains a reliable evaluation instrument as retrieval techniques have advanced.
Podcast Metadata and Content: Episode Relevance andAttractiveness in Ad Hoc Search
Aug 25, 2021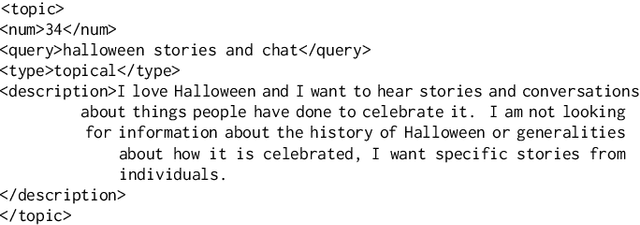

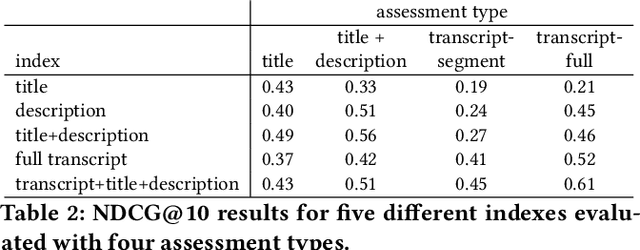
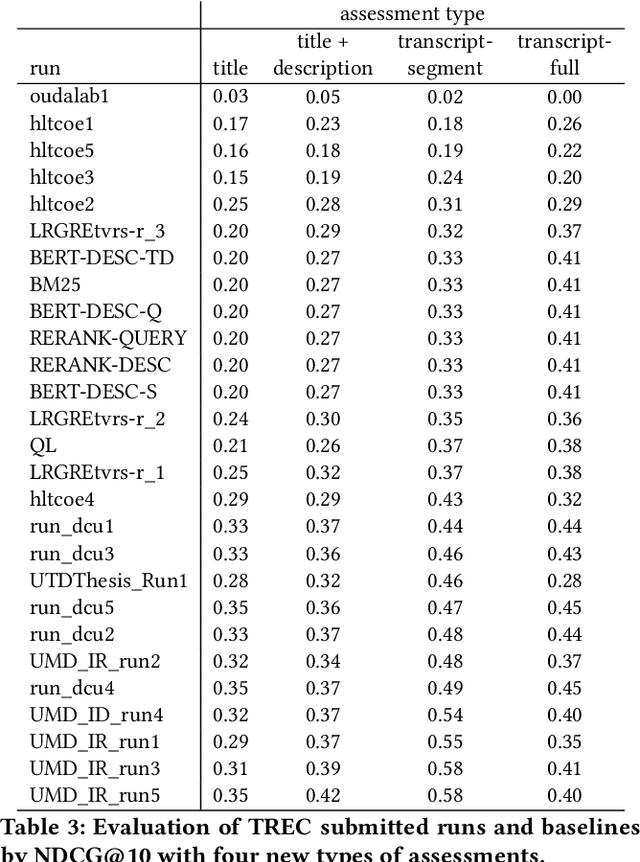
Rapidly growing online podcast archives contain diverse content on a wide range of topics. These archives form an important resource for entertainment and professional use, but their value can only be realized if users can rapidly and reliably locate content of interest. Search for relevant content can be based on metadata provided by content creators, but also on transcripts of the spoken content itself. Excavating relevant content from deep within these audio streams for diverse types of information needs requires varying the approach to systems prototyping. We describe a set of diverse podcast information needs and different approaches to assessing retrieved content for relevance. We use these information needs in an investigation of the utility and effectiveness of these information sources. Based on our analysis, we recommend approaches for indexing and retrieving podcast content for ad hoc search.