 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueryBuilder: Human-in-the-Loop Query Development for Information Retrieval
Sep 10, 2024Frequently, users of an Information Retrieval (IR) system start with an overarching information need (a.k.a., an analytic task) and proceed to define finer-grained queries covering various important aspects (i.e., sub-topics) of that analytic task. We present a novel, interactive system called $\textit{QueryBuilder}$, which allows a novice, English-speaking user to create queries with a small amount of effort, through efficient exploration of an English development corpus in order to rapidly develop cross-lingual information retrieval queries corresponding to the user's information needs. QueryBuilder performs near real-time retrieval of documents based on user-entered search terms; the user looks through the retrieved documents and marks sentences as relevant to the information needed. The marked sentences are used by the system as additional information in query formation and refinement: query terms (and, optionally, event features, which capture event $'triggers'$ (indicator terms) and agent/patient roles) are appropriately weighted, and a neural-based system, which better captures textual meaning, retrieves other relevant content. The process of retrieval and marking is repeated as many times as desired, giving rise to increasingly refined queries in each iteration. The final product is a fine-grained query used in Cross-Lingual Information Retrieval (CLIR). Our experiments using analytic tasks and requests from the IARPA BETTER IR datasets show that with a small amount of effort (at most 10 minutes per sub-topic), novice users can form $\textit{useful}$ fine-grained queries including in languages they don't understand. QueryBuilder also provides beneficial capabilities to the traditional corpus exploration and query formation process. A demonstration video is released at https://vimeo.com/734795835
ZS4IE: A toolkit for Zero-Shot Information Extraction with simple Verbalizations
Mar 28, 2022
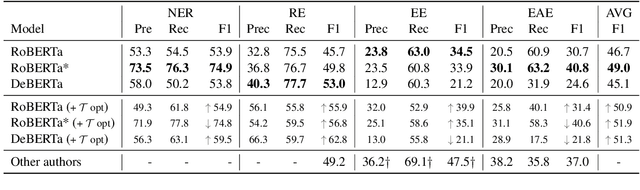
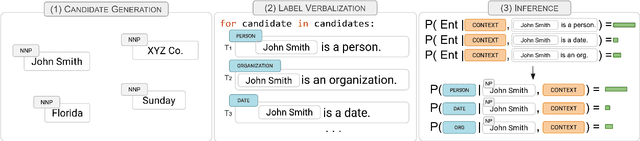

The current workflow for Information Extraction (IE) analysts involves the definition of the entities/relations of interest and a training corpus with annotated examples. In this demonstration we introduce a new workflow where the analyst directly verbalizes the entities/relations, which are then used by a Textual Entailment model to perform zero-shot IE. We present the design and implementation of a toolkit with a user interface, as well as experiments on four IE tasks that show that the system achieves very good performance at zero-shot learning using only 5--15 minutes per type of a user's effort. Our demonstration system is open-sourced at https://github.com/BBN-E/ZS4IE . A demonstration video is available at https://vimeo.com/676138340 .
ExcavatorCovid: Extracting Events and Relations from Text Corpora for Temporal and Causal Analysis for COVID-19
May 05, 2021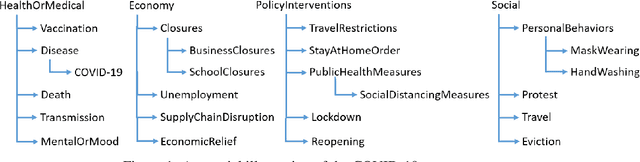
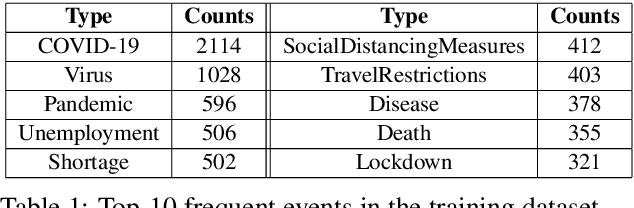
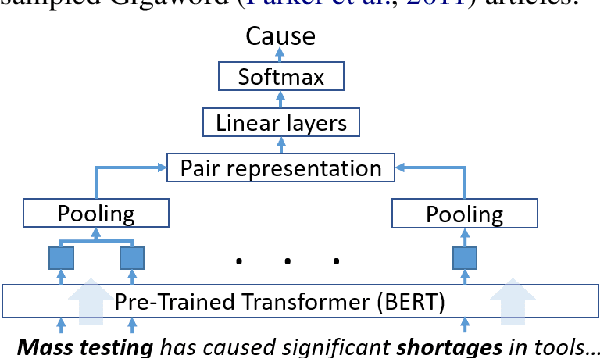
Timely responses from policy makers to mitigate the impact of the COVID-19 pandemic rely on a comprehensive grasp of events, their causes, and their impacts. These events are reported at such a speed and scale as to be overwhelming. In this paper, we present ExcavatorCovid, a machine reading system that ingests open-source text documents (e.g., news and scientific publications), extracts COVID19 related events and relations between them, and builds a Temporal and Causal Analysis Graph (TCAG). Excavator will help government agencies alleviate the information overload, understand likely downstream effects of political and economic decisions and events related to the pandemic, and respond in a timely manner to mitigate the impact of COVID-19. We expect the utility of Excavator to outlive the COVID-19 pandemic: analysts and decision makers will be empowered by Excavator to better understand and solve complex problems in the future. An interactive TCAG visualization is available at http://afrl402.bbn.com:5050/index.html. We also released a demonstration video at https://vimeo.com/528619007.
Rapid Customization for Event Extraction
Sep 20, 2018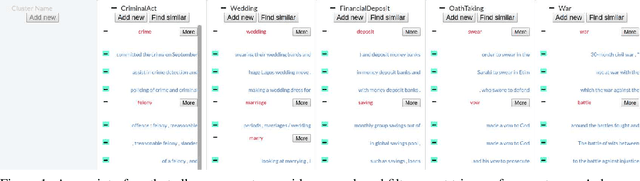
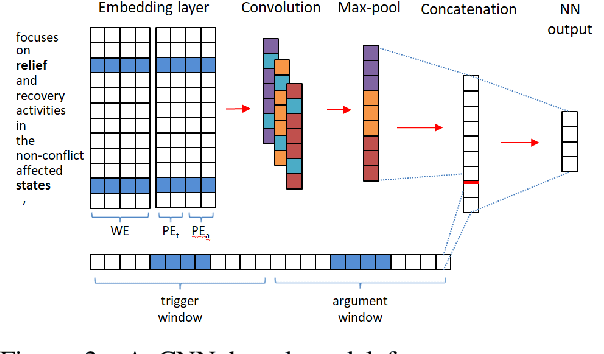
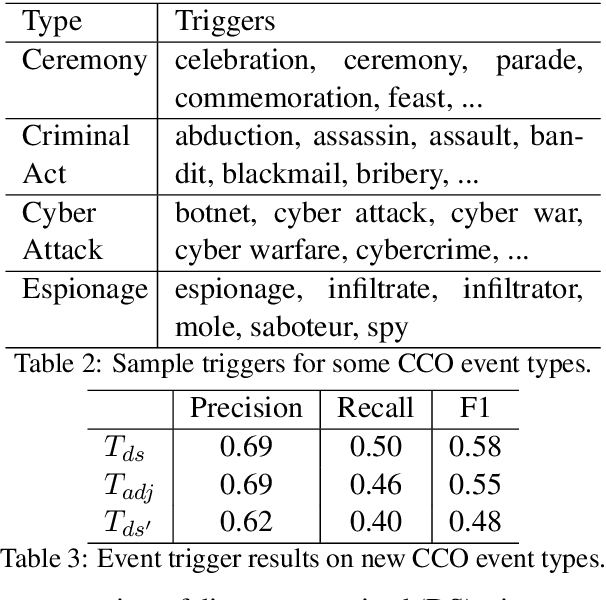
We present a system for rapidly customizing event extraction capability to find new event types and their arguments. The system allows a user to find, expand and filter event triggers for a new event type by exploring an unannotated corpus. The system will then automatically generate mention-level event annotation automatically, and train a Neural Network model for finding the corresponding event. Additionally, the system uses the ACE corpus to train an argument model for extracting Actor, Place, and Time arguments for any event types, including ones not seen in its training data. Experiments show that with less than 10 minutes of human effort per event type, the system achieves good performance for 67 novel event types. The code, documentation, and a demonstration video will be released as open source on github.com.