 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain-Specific Curated Benchmark for Entity and Document-Level Relation Extraction
Feb 04, 2026Information Extraction (IE), encompassing Named Entity Recognition (NER), Named Entity Linking (NEL), and Relation Extraction (RE), is critical for transforming the rapidly growing volume of scientific publications into structured, actionable knowledge. This need is especially evident in fast-evolving biomedical fields such as the gut-brain axis, where research investigates complex interactions between the gut microbiota and brain-related disorders. Existing biomedical IE benchmarks, however, are often narrow in scope and rely heavily on distantly supervised or automatically generated annotations, limiting their utility for advancing robust IE methods. We introduce GutBrainIE, a benchmark based on more than 1,600 PubMed abstracts, manually annotated by biomedical and terminological experts with fine-grained entities, concept-level links, and relations. While grounded in the gut-brain axis, the benchmark's rich schema, multiple tasks, and combination of highly curated and weakly supervised data make it broadly applicable to the development and evaluation of biomedical IE systems across domains.
LISP -- A Rich Interaction Dataset and Loggable Interactive Search Platform
Jan 14, 2026We present a reusable dataset and accompanying infrastructure for studying human search behavior in Interactive Information Retrieval (IIR). The dataset combines detailed interaction logs from 61 participants (122 sessions) with user characteristics, including perceptual speed, topic-specific interest, search expertise, and demographic information. To facilitate reproducibility and reuse, we provide a fully documented study setup, a web-based perceptual speed test, and a framework for conducting similar user studies. Our work allows researchers to investigate individual and contextual factors affecting search behavior, and to develop or validate user simulators that account for such variability. We illustrate the datasets potential through an illustrative analysis and release all resources as open-access, supporting reproducible research and resource sharing in the IIR community.
Demographically-Inspired Query Variants Using an LLM
Aug 25, 2025This study proposes a method to diversify queries in existing test collections to reflect some of the diversity of search engine users, aligning with an earlier vision of an 'ideal' test collection. A Large Language Model (LLM) is used to create query variants: alternative queries that have the same meaning as the original. These variants represent user profiles characterised by different properties, such as language and domain proficiency, which are known in the IR literature to influence query formulation. The LLM's ability to generate query variants that align with user profiles is empirically validated, and the variants' utility is further explored for IR system evaluation. Results demonstrate that the variants impact how systems are ranked and show that user profiles experience significantly different levels of system effectiveness. This method enables an alternative perspective on system evaluation where we can observe both the impact of user profiles on system rankings and how system performance varies across users.
Reproducibility and Artifact Consistency of the SIGIR 2022 Recommender Systems Papers Based on Message Passing
Mar 10, 2025Graph-based techniques relying on neural networks and embeddings have gained attention as a way to develop Recommender Systems (RS) with several papers on the topic presented at SIGIR 2022 and 2023. Given the importance of ensuring that published research is methodologically sound and reproducible, in this paper we analyze 10 graph-based RS papers, most of which were published at SIGIR 2022, and assess their impact on subsequent work published in SIGIR 2023. Our analysis reveals several critical points that require attention: (i) the prevalence of bad practices, such as erroneous data splits or information leakage between training and testing data, which call into question the validity of the results; (ii) frequent inconsistencies between the provided artifacts (source code and data) and their descriptions in the paper, causing uncertainty about what is actually being evaluated; and (iii) the preference for new or complex baselines that are weaker compared to simpler ones, creating the impression of continuous improvement even when, particularly for the Amazon-Book dataset, the state-of-the-art has significantly worsened. Due to these issues, we are unable to confirm the claims made in most of the papers we examined and attempted to reproduce.
Words Blending Boxes. Obfuscating Queries in Information Retrieval using Differential Privacy
May 15, 2024



Ensuring the effectiveness of search queries while protecting user privacy remains an open issue. When an Information Retrieval System (IRS) does not protect the privacy of its users, sensitive information may be disclosed through the queries sent to the system. Recent improvements, especially in NLP, have shown the potential of using Differential Privacy to obfuscate texts while maintaining satisfactory effectiveness. However, such approaches may protect the user's privacy only from a theoretical perspective while, in practice, the real user's information need can still be inferred if perturbed terms are too semantically similar to the original ones. We overcome such limitations by proposing Word Blending Boxes, a novel differentially private mechanism for query obfuscation, which protects the words in the user queries by employing safe boxes. To measure the overall effectiveness of the proposed WBB mechanism, we measure the privacy obtained by the obfuscation process, i.e., the lexical and semantic similarity between original and obfuscated queries. Moreover, we assess the effectiveness of the privatized queries in retrieving relevant documents from the IRS. Our findings indicate that WBB can be integrated effectively into existing IRSs, offering a key to the challenge of protecting user privacy from both a theoretical and a practical point of view.
How Discriminative Are Your Qrels? How To Study the Statistical Significance of Document Adjudication Methods
Aug 28, 2023



Creating test collections for offline retrieval evaluation requires human effort to judge documents' relevance. This expensive activity motivated much work in developing methods for constructing benchmarks with fewer assessment costs. In this respect, adjudication methods actively decide both which documents and the order in which experts review them, in order to better exploit the assessment budget or to lower it. Researchers evaluate the quality of those methods by measuring the correlation between the known gold ranking of systems under the full collection and the observed ranking of systems under the lower-cost one. This traditional analysis ignores whether and how the low-cost judgements impact on the statistically significant differences among systems with respect to the full collection. We fill this void by proposing a novel methodology to evaluate how the low-cost adjudication methods preserve the pairwise significant differences between systems as the full collection. In other terms, while traditional approaches look for stability in answering the question "is system A better than system B?", our proposed approach looks for stability in answering the question "is system A significantly better than system B?", which is the ultimate questions researchers need to answer to guarantee the generalisability of their results. Among other results, we found that the best methods in terms of ranking of systems correlation do not always match those preserving statistical significance.
Report from Dagstuhl Seminar 23031: Frontiers of Information Access Experimentation for Research and Education
Apr 18, 2023



This report documents the program and the outcomes of Dagstuhl Seminar 23031 ``Frontiers of Information Access Experimentation for Research and Education'', which brought together 37 participants from 12 countries. The seminar addressed technology-enhanced information access (information retrieval, recommender systems, natural language processing) and specifically focused on developing more responsible experimental practices leading to more valid results, both for research as well as for scientific education. The seminar brought together experts from various sub-fields of information access, namely IR, RS, NLP, information science, and human-computer interaction to create a joint understanding of the problems and challenges presented by next generation information access systems, from both the research and the experimentation point of views, to discuss existing solutions and impediments, and to propose next steps to be pursued in the area in order to improve not also our research methods and findings but also the education of the new generation of researchers and developers. The seminar featured a series of long and short talks delivered by participants, who helped in setting a common ground and in letting emerge topics of interest to be explored as the main output of the seminar. This led to the definition of five groups which investigated challenges, opportunities, and next steps in the following areas: reality check, i.e. conducting real-world studies, human-machine-collaborative relevance judgment frameworks, overcoming methodological challenges in information retrieval and recommender systems through awareness and education, results-blind reviewing, and guidance for authors.
Query Performance Prediction for Neural IR: Are We There Yet?
Feb 20, 2023Evaluation in Information Retrieval relies on post-hoc empirical procedures, which are time-consuming and expensive operations. To alleviate this, Query Performance Prediction (QPP) models have been developed to estimate the performance of a system without the need for human-made relevance judgements. Such models, usually relying on lexical features from queries and corpora, have been applied to traditional sparse IR methods - with various degrees of success. With the advent of neural IR and large Pre-trained Language Models, the retrieval paradigm has significantly shifted towards more semantic signals. In this work, we study and analyze to what extent current QPP models can predict the performance of such systems. Our experiments consider seven traditional bag-of-words and seven BERT-based IR approaches, as well as nineteen state-of-the-art QPPs evaluated on two collections, Deep Learning '19 and Robust '04. Our findings show that QPPs perform statistically significantly worse on neural IR systems. In settings where semantic signals are prominent (e.g., passage retrieval), their performance on neural models drops by as much as 10% compared to bag-of-words approaches. On top of that, in lexical-oriented scenarios, QPPs fail to predict performance for neural IR systems on those queries where they differ from traditional approaches the most.
Response to Moffat's Comment on "Towards Meaningful Statements in IR Evaluation: Mapping Evaluation Measures to Interval Scales"
Dec 22, 2022Moffat recently commented on our previous work. Our work focused on how laying the foundations of our evaluation methodology into the theory of measurement can improve our knowledge and understanding of the evaluation measures we use in IR and how it can shed light on the different types of scales adopted by our evaluation measures; we also provided evidence, through extensive experimentation, on the impact of the different types of scales on the statistical analyses, as well as on the impact of departing from their assumptions. Moreover, we investigated, for the first time in IR, the concept of meaningfulness, i.e. the invariance of the experimental statements and inferences you draw, and proposed it as a way to ensure more valid and generalizabile results. Moffat's comments build on: (i) misconceptions about the representational theory of measurement, such as what an interval scale actually is and what axioms it has to comply with; (ii) they totally miss the central concept of meaningfulness. Therefore, we reply to Moffat's comments by properly framing them in the representational theory of measurement and in the concept of meaningfulness. All in all, we can only reiterate what we said several times: the goal of this research line is to theoretically ground our evaluation methodology - and IR is a field where it is extremely challenging to perform any theoretical advances - in order to aim for more robust and generalizable inferences - something we currently lack in the field. Possibly there are other and better ways to achieve this objective and these proposals could emerge from an open discussion in the field and from the work of others. On the other hand, reducing everything to a contrast on what is (or pretend to be) an interval scale or whether all or none evaluation measures are interval scales may be more a barrier from than a help in progressing towards this goal.
Corrected Evaluation Results of the NTCIR WWW-2, WWW-3, and WWW-4 English Subtasks
Oct 19, 2022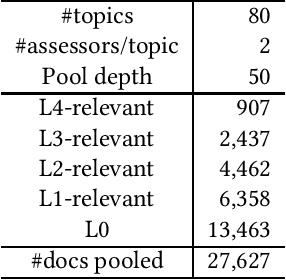
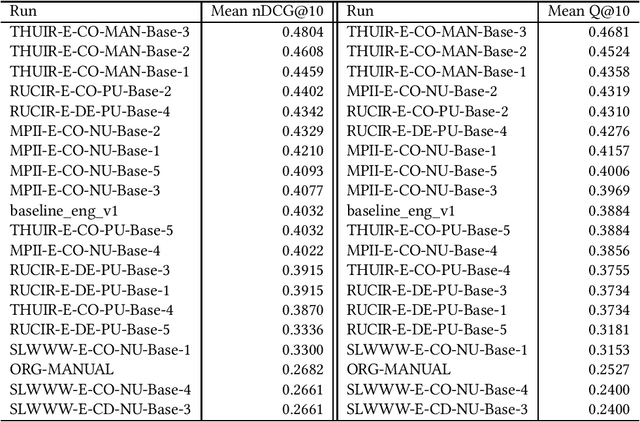
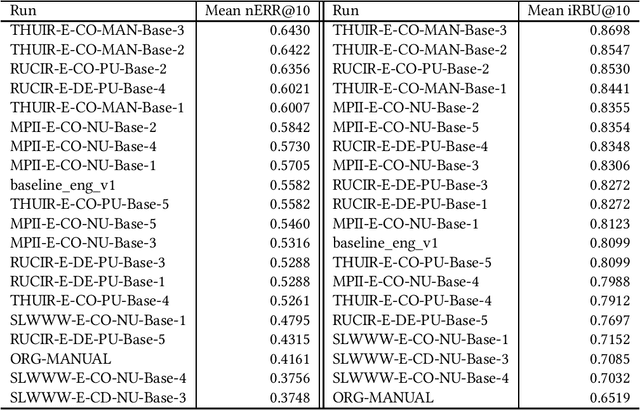

Unfortunately, the official English (sub)task results reported in the NTCIR-14 WWW-2, NTCIR-15 WWW-3, and NTCIR-16 WWW-4 overview papers are incorrect due to noise in the official qrels files; this paper reports results based on the corrected qrels files. The noise is due to a fatal bug in the backend of our relevance assessment interface. More specifically, at WWW-2, WWW-3, and WWW-4, two versions of pool files were created for each English topic: a PRI ("prioritised") file, which uses the NTCIRPOOL script to prioritise likely relevant documents, and a RND ("randomised") file, which randomises the pooled documents. This was done for the purpose of studying the effect of document ordering for relevance assessors. However, the programmer who wrote the interface backend assumed that a combination of a topic ID and a document rank in the pool file uniquely determines a document ID; this is obviously incorrect as we have two versions of pool files. The outcome is that all the PRI-based relevance labels for the WWW-2 test collection are incorrect (while all the RND-based relevance labels are correct), and all the RND-based relevance labels for the WWW-3 and WWW-4 test collections are incorrect (while all the PRI-based relevance labels are correct). This bug was finally discovered at the NTCIR-16 WWW-4 task when the first seven authors of this paper served as Gold assessors (i.e., topic creators who define what is relevant) and closely examined the disagreements with Bronze assessors (i.e., non-topic-creators; non-experts). We would like to apologise to the WWW participants and the NTCIR chairs for the inconvenience and confusion caused due to this bug.