 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the TREC Plain Language Adaptation of Biomedical Abstracts (PLABA) track
Jul 18, 2025
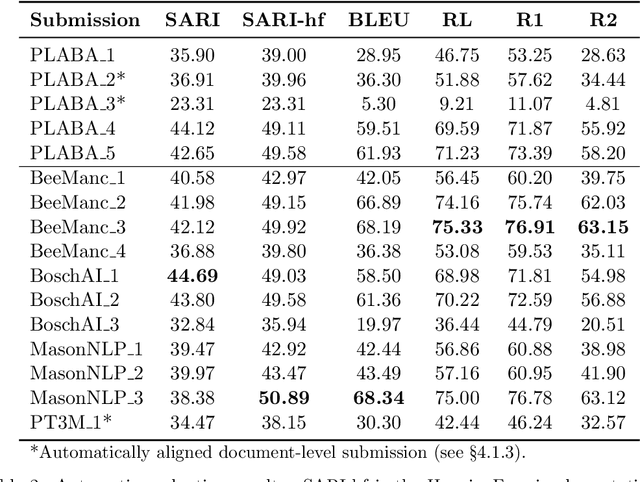
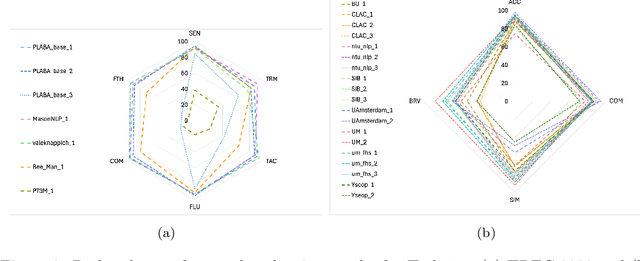
Objective: Recent advances in language models have shown potential to adapt professional-facing biomedical literature to plain language, making it accessible to patients and caregivers. However, their unpredictability, combined with the high potential for harm in this domain, means rigorous evaluation is necessary. Our goals with this track were to stimulate research and to provide high-quality evaluation of the most promising systems. Methods: We hosted the Plain Language Adaptation of Biomedical Abstracts (PLABA) track at the 2023 and 2024 Text Retrieval Conferences. Tasks included complete, sentence-level, rewriting of abstracts (Task 1) as well as identifying and replacing difficult terms (Task 2). For automatic evaluation of Task 1, we developed a four-fold set of professionally-written references. Submissions for both Tasks 1 and 2 were provided extensive manual evaluation from biomedical experts. Results: Twelve teams spanning twelve countries participated in the track, with models from multilayer perceptrons to large pretrained transformers. In manual judgments of Task 1, top-performing models rivaled human levels of factual accuracy and completeness, but not simplicity or brevity. Automatic, reference-based metrics generally did not correlate well with manual judgments. In Task 2, systems struggled with identifying difficult terms and classifying how to replace them. When generating replacements, however, LLM-based systems did well in manually judged accuracy, completeness, and simplicity, though not in brevity. Conclusion: The PLABA track showed promise for using Large Language Models to adapt biomedical literature for the general public, while also highlighting their deficiencies and the need for improved automatic benchmarking tools.
Towards Answering Health-related Questions from Medical Videos: Datasets and Approaches
Sep 21, 2023



The increase in the availability of online videos has transformed the way we access information and knowledge. A growing number of individuals now prefer instructional videos as they offer a series of step-by-step procedures to accomplish particular tasks. The instructional videos from the medical domain may provide the best possible visual answers to first aid, medical emergency, and medical education questions. Toward this, this paper is focused on answering health-related questions asked by the public by providing visual answers from medical videos. The scarcity of large-scale datasets in the medical domain is a key challenge that hinders the development of applications that can help the public with their health-related questions. To address this issue, we first proposed a pipelined approach to create two large-scale datasets: HealthVidQA-CRF and HealthVidQA-Prompt. Later, we proposed monomodal and multimodal approaches that can effectively provide visual answers from medical videos to natural language questions. We conducted a comprehensive analysis of the results, focusing on the impact of the created datasets on model training and the significance of visual features in enhancing the performance of the monomodal and multi-modal approaches. Our findings suggest that these datasets have the potential to enhance the performance of medical visual answer localization tasks and provide a promising future direction to further enhance the performance by using pre-trained language-vision models.
A Dataset for Medical Instructional Video Classification and Question Answering
Jan 30, 2022This paper introduces a new challenge and datasets to foster research toward designing systems that can understand medical videos and provide visual answers to natural language questions. We believe medical videos may provide the best possible answers to many first aids, medical emergency, and medical education questions. Toward this, we created the MedVidCL and MedVidQA datasets and introduce the tasks of Medical Video Classification (MVC) and Medical Visual Answer Localization (MVAL), two tasks that focus on cross-modal (medical language and medical video) understanding. The proposed tasks and datasets have the potential to support the development of sophisticated downstream applications that can benefit the public and medical practitioners. Our datasets consist of 6,117 annotated videos for the MVC task and 3,010 annotated questions and answers timestamps from 899 videos for the MVAL task. These datasets have been verified and corrected by medical informatics experts. We have also benchmarked each task with the created MedVidCL and MedVidQA datasets and proposed the multimodal learning methods that set competitive baselines for future research.