 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating and Enhancing the Robustness of Large Multimodal Models Against Temporal Inconsistency
May 20, 2025Large Multimodal Models (LMMs) have recently demonstrated impressive performance on general video comprehension benchmarks. Nevertheless, for broader applications, the robustness of their temporal analysis capability needs to be thoroughly investigated yet predominantly ignored. Motivated by this, we propose a novel temporal robustness benchmark (TemRobBench), which introduces temporal inconsistency perturbations separately at the visual and textual modalities to assess the robustness of models. We evaluate 16 mainstream LMMs and find that they exhibit over-reliance on prior knowledge and textual context in adversarial environments, while ignoring the actual temporal dynamics in the video. To mitigate this issue, we design panoramic direct preference optimization (PanoDPO), which encourages LMMs to incorporate both visual and linguistic feature preferences simultaneously. Experimental results show that PanoDPO can effectively enhance the model's robustness and reliability in temporal analysis.
Rethinking Visual Layer Selection in Multimodal LLMs
Apr 30, 2025Multimodal large language models (MLLMs) have achieved impressive performance across a wide range of tasks, typically using CLIP-ViT as their visual encoder due to its strong text-image alignment capabilities. While prior studies suggest that different CLIP-ViT layers capture different types of information, with shallower layers focusing on fine visual details and deeper layers aligning more closely with textual semantics, most MLLMs still select visual features based on empirical heuristics rather than systematic analysis. In this work, we propose a Layer-wise Representation Similarity approach to group CLIP-ViT layers with similar behaviors into {shallow, middle, and deep} categories and assess their impact on MLLM performance. Building on this foundation, we revisit the visual layer selection problem in MLLMs at scale, training LLaVA-style models ranging from 1.4B to 7B parameters. Through extensive experiments across 10 datasets and 4 tasks, we find that: (1) deep layers are essential for OCR tasks; (2) shallow and middle layers substantially outperform deep layers on reasoning tasks involving counting, positioning, and object localization; (3) a lightweight fusion of features across shallow, middle, and deep layers consistently outperforms specialized fusion baselines and single-layer selections, achieving gains on 9 out of 10 datasets. Our work offers the first principled study of visual layer selection in MLLMs, laying the groundwork for deeper investigations into visual representation learning for MLLMs.
MultiConIR: Towards multi-condition Information Retrieval
Mar 11, 2025



In this paper, we introduce MultiConIR, the first benchmark designed to evaluate retrieval models in multi-condition scenarios. Unlike existing datasets that primarily focus on single-condition queries from search engines, MultiConIR captures real-world complexity by incorporating five diverse domains: books, movies, people, medical cases, and legal documents. We propose three tasks to systematically assess retrieval and reranking models on multi-condition robustness, monotonic relevance ranking, and query format sensitivity. Our findings reveal that existing retrieval and reranking models struggle with multi-condition retrieval, with rerankers suffering severe performance degradation as query complexity increases. We further investigate the performance gap between retrieval and reranking models, exploring potential reasons for these discrepancies, and analysis the impact of different pooling strategies on condition placement sensitivity. Finally, we highlight the strengths of GritLM and Nv-Embed, which demonstrate enhanced adaptability to multi-condition queries, offering insights for future retrieval models. The code and datasets are available at https://github.com/EIT-NLP/MultiConIR.
Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices
Mar 08, 2025Multimodal Large Language Models (MLLMs) have made significant advancements in recent years, with visual features playing an increasingly critical role in enhancing model performance. However, the integration of multi-layer visual features in MLLMs remains underexplored, particularly with regard to optimal layer selection and fusion strategies. Existing methods often rely on arbitrary design choices, leading to suboptimal outcomes. In this paper, we systematically investigate two core aspects of multi-layer visual feature fusion: (1) selecting the most effective visual layers and (2) identifying the best fusion approach with the language model. Our experiments reveal that while combining visual features from multiple stages improves generalization, incorporating additional features from the same stage typically leads to diminished performance. Furthermore, we find that direct fusion of multi-layer visual features at the input stage consistently yields superior and more stable performance across various configurations. We make all our code publicly available: https://github.com/EIT-NLP/Layer_Select_Fuse_for_MLLM.
Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning
Feb 25, 2025



Large Language Models (LLMs) excel in reasoning tasks through Chain-of-Thought (CoT) prompting. However, CoT prompting greatly increases computational demands, which has prompted growing interest in distilling CoT capabilities into Small Language Models (SLMs). This study systematically examines the factors influencing CoT distillation, including the choice of granularity, format and teacher model. Through experiments involving four teacher models and seven student models across seven mathematical and commonsense reasoning datasets, we uncover three key findings: (1) Unlike LLMs, SLMs exhibit a non-monotonic relationship with granularity, with stronger models benefiting from finer-grained reasoning and weaker models performing better with simpler CoT supervision; (2) CoT format significantly impacts LLMs but has minimal effect on SLMs, likely due to their reliance on supervised fine-tuning rather than pretraining preferences; (3) Stronger teacher models do NOT always produce better student models, as diversity and complexity in CoT supervision can outweigh accuracy alone. These findings emphasize the need to tailor CoT strategies to specific student model, offering actionable insights for optimizing CoT distillation in SLMs. The code and datasets are available at https://github.com/EIT-NLP/Distilling-CoT-Reasoning.
Detecting Errors through Ensembling Prompts (DEEP): An End-to-End LLM Framework for Detecting Factual Errors
Jun 18, 2024Accurate text summarization is one of the most common and important tasks performed by Large Language Models, where the costs of human review for an entire document may be high, but the costs of errors in summarization may be even greater. We propose Detecting Errors through Ensembling Prompts (DEEP) - an end-to-end large language model framework for detecting factual errors in text summarization. Our framework uses a diverse set of LLM prompts to identify factual inconsistencies, treating their outputs as binary features, which are then fed into ensembling models. We then calibrate the ensembled models to produce empirically accurate probabilities that a text is factually consistent or free of hallucination. We demonstrate that prior models for detecting factual errors in summaries perform significantly worse without optimizing the thresholds on subsets of the evaluated dataset. Our framework achieves state-of-the-art (SOTA) balanced accuracy on the AggreFact-XSUM FTSOTA, TofuEval Summary-Level, and HaluEval Summarization benchmarks in detecting factual errors within transformer-generated text summaries. It does so without any fine-tuning of the language model or reliance on thresholding techniques not available in practical settings.
Unraveling the Mystery of Scaling Laws: Part I
Mar 21, 2024


Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
SASFormer: Transformers for Sparsely Annotated Semantic Segmentation
Dec 06, 2022



Semantic segmentation based on sparse annotation has advanced in recent years. It labels only part of each object in the image, leaving the remainder unlabeled. Most of the existing approaches are time-consuming and often necessitate a multi-stage training strategy. In this work, we propose a simple yet effective sparse annotated semantic segmentation framework based on segformer, dubbed SASFormer, that achieves remarkable performance. Specifically, the framework first generates hierarchical patch attention maps, which are then multiplied by the network predictions to produce correlated regions separated by valid labels. Besides, we also introduce the affinity loss to ensure consistency between the features of correlation results and network predictions. Extensive experiments showcase that our proposed approach is superior to existing methods and achieves cutting-edge performance. The source code is available at \url{https://github.com/su-hui-zz/SASFormer}.
WeLM: A Well-Read Pre-trained Language Model for Chinese
Oct 12, 2022
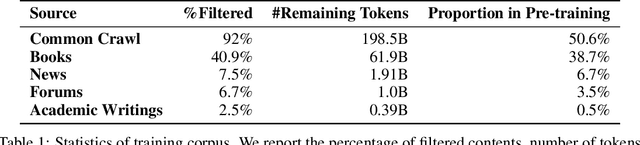
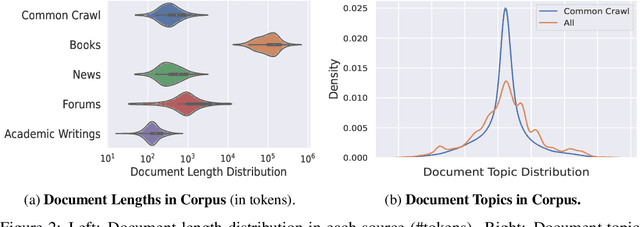

Large Language Models pre-trained with self-supervised learning have demonstrated impressive zero-shot generalization capabilities on a wide spectrum of tasks. In this work, we present WeLM: a well-read pre-trained language model for Chinese that is able to seamlessly perform different types of tasks with zero or few-shot demonstrations. WeLM is trained with 10B parameters by "reading" a curated high-quality corpus covering a wide range of topics. We show that WeLM is equipped with broad knowledge on various domains and languages. On 18 monolingual (Chinese) tasks, WeLM can significantly outperform existing pre-trained models with similar sizes and match the performance of models up to 25 times larger. WeLM also exhibits strong capabilities in multi-lingual and code-switching understanding, outperforming existing multilingual language models pre-trained on 30 languages. Furthermore, We collected human-written prompts for a large set of supervised datasets in Chinese and fine-tuned WeLM with multi-prompted training. The resulting model can attain strong generalization on unseen types of tasks and outperform the unsupervised WeLM in zero-shot learning. Finally, we demonstrate that WeLM has basic skills at explaining and calibrating the decisions from itself, which can be promising directions for future research. Our models can be applied from https://welm.weixin.qq.com/docs/api/.
Re-Attention Transformer for Weakly Supervised Object Localization
Aug 03, 2022Weakly supervised object localization is a challenging task which aims to localize objects with coarse annotations such as image categories. Existing deep network approaches are mainly based on class activation map, which focuses on highlighting discriminative local region while ignoring the full object. In addition, the emerging transformer-based techniques constantly put a lot of emphasis on the backdrop that impedes the ability to identify complete objects. To address these issues, we present a re-attention mechanism termed token refinement transformer (TRT) that captures the object-level semantics to guide the localization well. Specifically, TRT introduces a novel module named token priority scoring module (TPSM) to suppress the effects of background noise while focusing on the target object. Then, we incorporate the class activation map as the semantically aware input to restrain the attention map to the target object. Extensive experiments on two benchmarks showcase the superiority of our proposed method against existing methods with image category annotations. Source code is available in \url{https://github.com/su-hui-zz/ReAttentionTransformer}.