 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerial Path Online Planning for Urban Scene Updation
May 02, 2025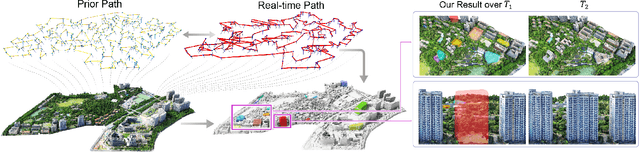

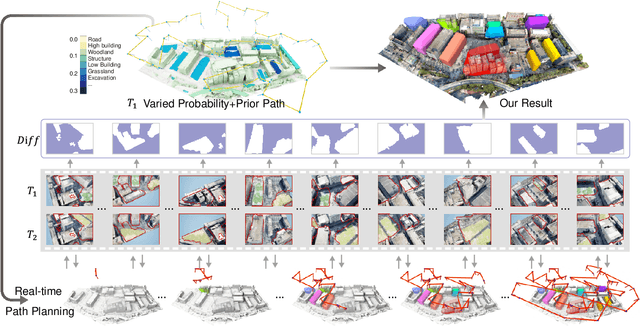
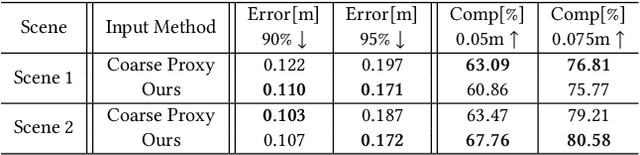
We present the first scene-update aerial path planning algorithm specifically designed for detecting and updating change areas in urban environments. While existing methods for large-scale 3D urban scene reconstruction focus on achieving high accuracy and completeness, they are inefficient for scenarios requiring periodic updates, as they often re-explore and reconstruct entire scenes, wasting significant time and resources on unchanged areas. To address this limitation, our method leverages prior reconstructions and change probability statistics to guide UAVs in detecting and focusing on areas likely to have changed. Our approach introduces a novel changeability heuristic to evaluate the likelihood of changes, driving the planning of two flight paths: a prior path informed by static priors and a dynamic real-time path that adapts to newly detected changes. The framework integrates surface sampling and candidate view generation strategies, ensuring efficient coverage of change areas with minimal redundancy. Extensive experiments on real-world urban datasets demonstrate that our method significantly reduces flight time and computational overhead, while maintaining high-quality updates comparable to full-scene re-exploration and reconstruction. These contributions pave the way for efficient, scalable, and adaptive UAV-based scene updates in complex urban environments.
CLR-Wire: Towards Continuous Latent Representations for 3D Curve Wireframe Generation
May 01, 2025We introduce CLR-Wire, a novel framework for 3D curve-based wireframe generation that integrates geometry and topology into a unified Continuous Latent Representation. Unlike conventional methods that decouple vertices, edges, and faces, CLR-Wire encodes curves as Neural Parametric Curves along with their topological connectivity into a continuous and fixed-length latent space using an attention-driven variational autoencoder (VAE). This unified approach facilitates joint learning and generation of both geometry and topology. To generate wireframes, we employ a flow matching model to progressively map Gaussian noise to these latents, which are subsequently decoded into complete 3D wireframes. Our method provides fine-grained modeling of complex shapes and irregular topologies, and supports both unconditional generation and generation conditioned on point cloud or image inputs. Experimental results demonstrate that, compared with state-of-the-art generative approaches, our method achieves substantial improvements in accuracy, novelty, and diversity, offering an efficient and comprehensive solution for CAD design, geometric reconstruction, and 3D content creation.
DREAM: Disentangling Risks to Enhance Safety Alignment in Multimodal Large Language Models
Apr 25, 2025



Multimodal Large Language Models (MLLMs) pose unique safety challenges due to their integration of visual and textual data, thereby introducing new dimensions of potential attacks and complex risk combinations. In this paper, we begin with a detailed analysis aimed at disentangling risks through step-by-step reasoning within multimodal inputs. We find that systematic multimodal risk disentanglement substantially enhances the risk awareness of MLLMs. Via leveraging the strong discriminative abilities of multimodal risk disentanglement, we further introduce \textbf{DREAM} (\textit{\textbf{D}isentangling \textbf{R}isks to \textbf{E}nhance Safety \textbf{A}lignment in \textbf{M}LLMs}), a novel approach that enhances safety alignment in MLLMs through supervised fine-tuning and iterative Reinforcement Learning from AI Feedback (RLAIF). Experimental results show that DREAM significantly boosts safety during both inference and training phases without compromising performance on normal tasks (namely oversafety), achieving a 16.17\% improvement in the SIUO safe\&effective score compared to GPT-4V. The data and code are available at https://github.com/Kizna1ver/DREAM.
HoLa: B-Rep Generation using a Holistic Latent Representation
Apr 22, 2025We introduce a novel representation for learning and generating Computer-Aided Design (CAD) models in the form of $\textit{boundary representations}$ (B-Reps). Our representation unifies the continuous geometric properties of B-Rep primitives in different orders (e.g., surfaces and curves) and their discrete topological relations in a $\textit{holistic latent}$ (HoLa) space. This is based on the simple observation that the topological connection between two surfaces is intrinsically tied to the geometry of their intersecting curve. Such a prior allows us to reformulate topology learning in B-Reps as a geometric reconstruction problem in Euclidean space. Specifically, we eliminate the presence of curves, vertices, and all the topological connections in the latent space by learning to distinguish and derive curve geometries from a pair of surface primitives via a neural intersection network. To this end, our holistic latent space is only defined on surfaces but encodes a full B-Rep model, including the geometry of surfaces, curves, vertices, and their topological relations. Our compact and holistic latent space facilitates the design of a first diffusion-based generator to take on a large variety of inputs including point clouds, single/multi-view images, 2D sketches, and text prompts. Our method significantly reduces ambiguities, redundancies, and incoherences among the generated B-Rep primitives, as well as training complexities inherent in prior multi-step B-Rep learning pipelines, while achieving greatly improved validity rate over current state of the art: 82% vs. $\approx$50%.
StrokeFusion: Vector Sketch Generation via Joint Stroke-UDF Encoding and Latent Sequence Diffusion
Mar 31, 2025In the field of sketch generation, raster-format trained models often produce non-stroke artifacts, while vector-format trained models typically lack a holistic understanding of sketches, leading to compromised recognizability. Moreover, existing methods struggle to extract common features from similar elements (e.g., eyes of animals) appearing at varying positions across sketches. To address these challenges, we propose StrokeFusion, a two-stage framework for vector sketch generation. It contains a dual-modal sketch feature learning network that maps strokes into a high-quality latent space. This network decomposes sketches into normalized strokes and jointly encodes stroke sequences with Unsigned Distance Function (UDF) maps, representing sketches as sets of stroke feature vectors. Building upon this representation, our framework exploits a stroke-level latent diffusion model that simultaneously adjusts stroke position, scale, and trajectory during generation. This enables high-fidelity sketch generation while supporting stroke interpolation editing. Extensive experiments on the QuickDraw dataset demonstrate that our framework outperforms state-of-the-art techniques, validating its effectiveness in preserving structural integrity and semantic features. Code and models will be made publicly available upon publication.
Enabling Inclusive Systematic Reviews: Incorporating Preprint Articles with Large Language Model-Driven Evaluations
Mar 19, 2025Background. Systematic reviews in comparative effectiveness research require timely evidence synthesis. Preprints accelerate knowledge dissemination but vary in quality, posing challenges for systematic reviews. Methods. We propose AutoConfidence (automated confidence assessment), an advanced framework for predicting preprint publication, which reduces reliance on manual curation and expands the range of predictors, including three key advancements: (1) automated data extraction using natural language processing techniques, (2) semantic embeddings of titles and abstracts, and (3) large language model (LLM)-driven evaluation scores. Additionally, we employed two prediction models: a random forest classifier for binary outcome and a survival cure model that predicts both binary outcome and publication risk over time. Results. The random forest classifier achieved AUROC 0.692 with LLM-driven scores, improving to 0.733 with semantic embeddings and 0.747 with article usage metrics. The survival cure model reached AUROC 0.716 with LLM-driven scores, improving to 0.731 with semantic embeddings. For publication risk prediction, it achieved a concordance index of 0.658, increasing to 0.667 with semantic embeddings. Conclusion. Our study advances the framework for preprint publication prediction through automated data extraction and multiple feature integration. By combining semantic embeddings with LLM-driven evaluations, AutoConfidence enhances predictive performance while reducing manual annotation burden. The framework has the potential to facilitate systematic incorporation of preprint articles in evidence-based medicine, supporting researchers in more effective evaluation and utilization of preprint resources.
Introducing Unbiased Depth into 2D Gaussian Splatting for High-accuracy Surface Reconstruction
Mar 09, 2025



Recently, 2D Gaussian Splatting (2DGS) has demonstrated superior geometry reconstruction quality than the popular 3DGS by using 2D surfels to approximate thin surfaces. However, it falls short when dealing with glossy surfaces, resulting in visible holes in these areas. We found the reflection discontinuity causes the issue. To fit the jump from diffuse to specular reflection at different viewing angles, depth bias is introduced in the optimized Gaussian primitives. To address that, we first replace the depth distortion loss in 2DGS with a novel depth convergence loss, which imposes a strong constraint on depth continuity. Then, we rectified the depth criterion in determining the actual surface, which fully accounts for all the intersecting Gaussians along the ray. Qualitative and quantitative evaluations across various datasets reveal that our method significantly improves reconstruction quality, with more complete and accurate surfaces than 2DGS.
ArcPro: Architectural Programs for Structured 3D Abstraction of Sparse Points
Mar 05, 2025We introduce ArcPro, a novel learning framework built on architectural programs to recover structured 3D abstractions from highly sparse and low-quality point clouds. Specifically, we design a domain-specific language (DSL) to hierarchically represent building structures as a program, which can be efficiently converted into a mesh. We bridge feedforward and inverse procedural modeling by using a feedforward process for training data synthesis, allowing the network to make reverse predictions. We train an encoder-decoder on the points-program pairs to establish a mapping from unstructured point clouds to architectural programs, where a 3D convolutional encoder extracts point cloud features and a transformer decoder autoregressively predicts the programs in a tokenized form. Inference by our method is highly efficient and produces plausible and faithful 3D abstractions. Comprehensive experiments demonstrate that ArcPro outperforms both traditional architectural proxy reconstruction and learning-based abstraction methods. We further explore its potential to work with multi-view image and natural language inputs.
Attention Distillation: A Unified Approach to Visual Characteristics Transfer
Feb 27, 2025Recent advances in generative diffusion models have shown a notable inherent understanding of image style and semantics. In this paper, we leverage the self-attention features from pretrained diffusion networks to transfer the visual characteristics from a reference to generated images. Unlike previous work that uses these features as plug-and-play attributes, we propose a novel attention distillation loss calculated between the ideal and current stylization results, based on which we optimize the synthesized image via backpropagation in latent space. Next, we propose an improved Classifier Guidance that integrates attention distillation loss into the denoising sampling process, further accelerating the synthesis and enabling a broad range of image generation applications. Extensive experiments have demonstrated the extraordinary performance of our approach in transferring the examples' style, appearance, and texture to new images in synthesis. Code is available at https://github.com/xugao97/AttentionDistillation.
AIR: Complex Instruction Generation via Automatic Iterative Refinement
Feb 25, 2025



With the development of large language models, their ability to follow simple instructions has significantly improved. However, adhering to complex instructions remains a major challenge. Current approaches to generating complex instructions are often irrelevant to the current instruction requirements or suffer from limited scalability and diversity. Moreover, methods such as back-translation, while effective for simple instruction generation, fail to leverage the rich contents and structures in large web corpora. In this paper, we propose a novel automatic iterative refinement framework to generate complex instructions with constraints, which not only better reflects the requirements of real scenarios but also significantly enhances LLMs' ability to follow complex instructions. The AIR framework consists of two stages: (1)Generate an initial instruction from a document; (2)Iteratively refine instructions with LLM-as-judge guidance by comparing the model's output with the document to incorporate valuable constraints. Finally, we construct the AIR-10K dataset with 10K complex instructions and demonstrate that instructions generated with our approach significantly improve the model's ability to follow complex instructions, outperforming existing methods for instruction generation.