 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Automation for Embodied Benchmark Construction: Pipelines, Embodiments, Simulators, and Trends
Jun 10, 2026Embodied intelligence now spans navigation, household assistance, manipulation, autonomous driving, aerial agents, and multimodal large-model control. This expansion has made benchmark construction a central bottleneck for reliable evaluation. Unlike static datasets, embodied benchmarks combine task specifications, environments, robot data, demonstrations, annotations, metrics, evaluation scripts, and release policies into a single evaluation system. This survey reviews the literature through a five-stage construction pipeline: requirement and task construction, data acquisition, data cleaning and annotation, benchmark suite generation and metric definition, and evaluation execution with diagnostic feedback. For each stage, the survey analyzes the transition from manual curation to traditional automation, foundation-model assistance, and agentic closed-loop workflows. It also compares qualitative construction costs across human labor, data and asset acquisition, compute and simulation, validation and debugging, governance and maintenance, and rework risk. The main conclusion is that automation does not simply reduce benchmark cost. Instead, it often shifts cost toward validation, auditability, version control, and long-term governance. Progress in embodied evaluation will therefore depend not only on larger benchmark suites, but also on construction pipelines that are diagnosable, auditable, and responsibly refreshable.
Embodied-BenchClaw: An Autonomous Multi-Agent System for Embodied Spatial Intelligence Benchmark Construction
Jun 10, 2026Benchmarks are essential for evaluating embodied spatial intelligence, yet their construction is labor-intensive, hard to reuse, and difficult to maintain. Existing embodied benchmarks are often static and may quickly become saturated as models improve, limiting their ability to distinguish new capabilities. We propose Embodied-BenchClaw, an autonomous agentic system for constructing embodied spatial intelligence benchmarks. Given a user-specified evaluation intent, Embodied-BenchClaw automatically produces a complete and continually updatable benchmark package through a five-stage pipeline: intent blueprinting, data collection, structuring and cleaning, benchmark synthesis, and evaluation reporting. The pipeline is coordinated by three agents for planning, construction, and evaluation. To improve reusability and reliability, Embodied-BenchClaw introduces an extensible Skill Library and process quality control, enabling benchmark construction to be composable, verifiable, and repairable. We instantiate multiple benchmarks covering indoor spatial reasoning, outdoor spatial reasoning, robotic manipulation, quadruped robot navigation, UAV/aerial-view understanding, and static benchmark enhancement. These benchmarks span diverse embodied carriers, data sources, and spatial capabilities. Experiments with human evaluation, judge-based assessment, consistency checks, cost analysis, and ablations show that Embodied-BenchClaw can construct verifiable, executable, maintainable, and diagnostically useful embodied spatial benchmarks with reduced manual effort.
Aerial Path Online Planning for Urban Scene Updation
May 02, 2025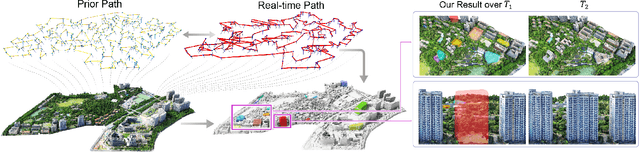

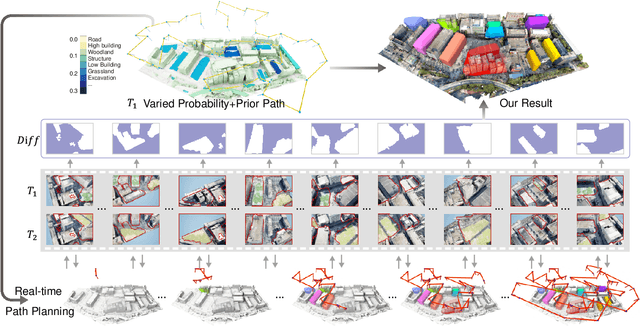
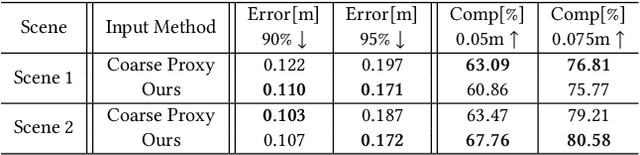
We present the first scene-update aerial path planning algorithm specifically designed for detecting and updating change areas in urban environments. While existing methods for large-scale 3D urban scene reconstruction focus on achieving high accuracy and completeness, they are inefficient for scenarios requiring periodic updates, as they often re-explore and reconstruct entire scenes, wasting significant time and resources on unchanged areas. To address this limitation, our method leverages prior reconstructions and change probability statistics to guide UAVs in detecting and focusing on areas likely to have changed. Our approach introduces a novel changeability heuristic to evaluate the likelihood of changes, driving the planning of two flight paths: a prior path informed by static priors and a dynamic real-time path that adapts to newly detected changes. The framework integrates surface sampling and candidate view generation strategies, ensuring efficient coverage of change areas with minimal redundancy. Extensive experiments on real-world urban datasets demonstrate that our method significantly reduces flight time and computational overhead, while maintaining high-quality updates comparable to full-scene re-exploration and reconstruction. These contributions pave the way for efficient, scalable, and adaptive UAV-based scene updates in complex urban environments.
Communicating with sentences: A multi-word naming game model
Sep 18, 2017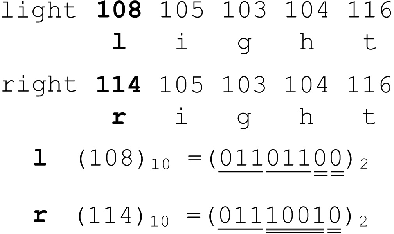
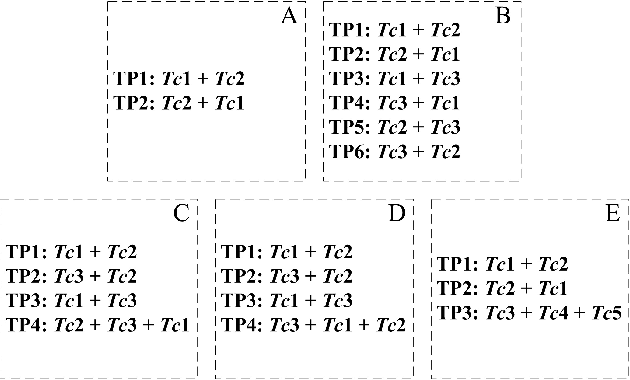
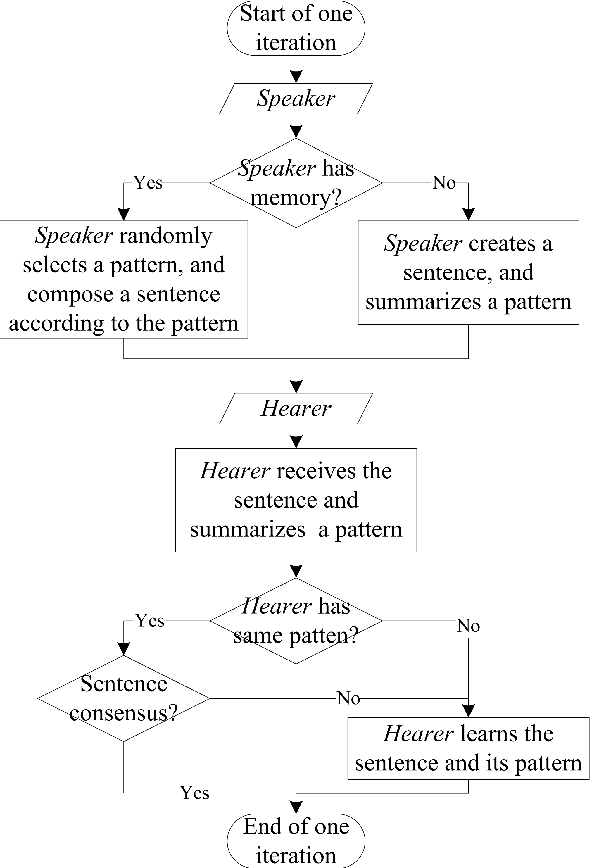
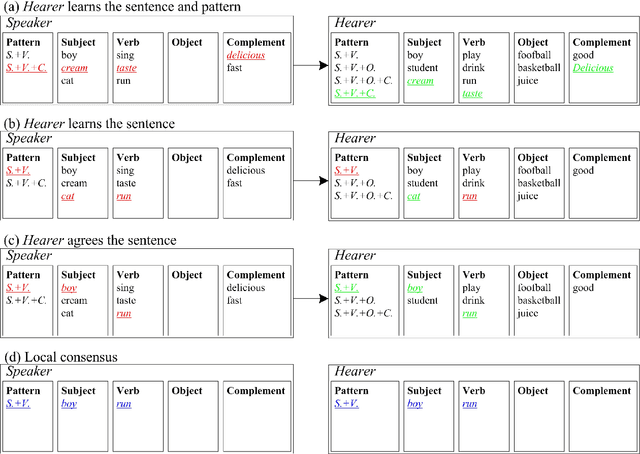
Naming game simulates the process of naming an object by a single word, in which a population of communicating agents can reach global consensus asymptotically through iteratively pair-wise conversations. We propose an extension of the single-word model to a multi-word naming game (MWNG), simulating the case of describing a complex object by a sentence (multiple words). Words are defined in categories, and then organized as sentences by combining them from different categories. We refer to a formatted combination of several words as a pattern. In such an MWNG, through a pair-wise conversation, it requires the hearer to achieve consensus with the speaker with respect to both every single word in the sentence as well as the sentence pattern, so as to guarantee the correct meaning of the saying, otherwise, they fail reaching consensus in the interaction. We validate the model in three typical topologies as the underlying communication network, and employ both conventional and man-designed patterns in performing the MWNG.