 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA RAD approach to deep mixture models
Mar 18, 2019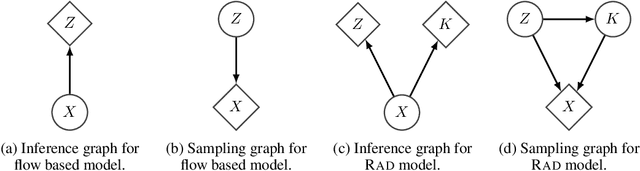
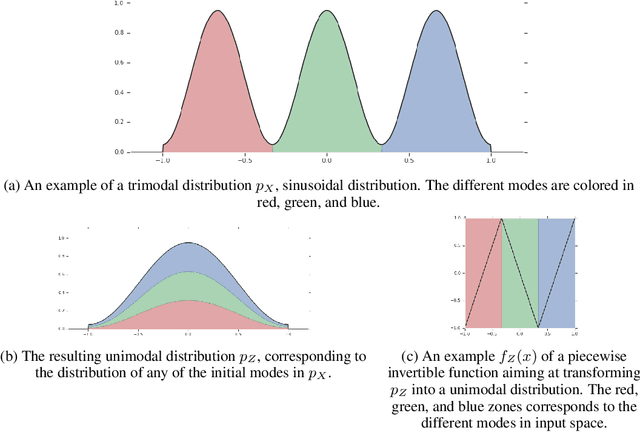
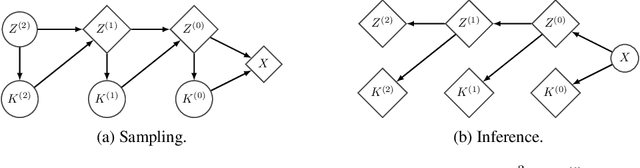
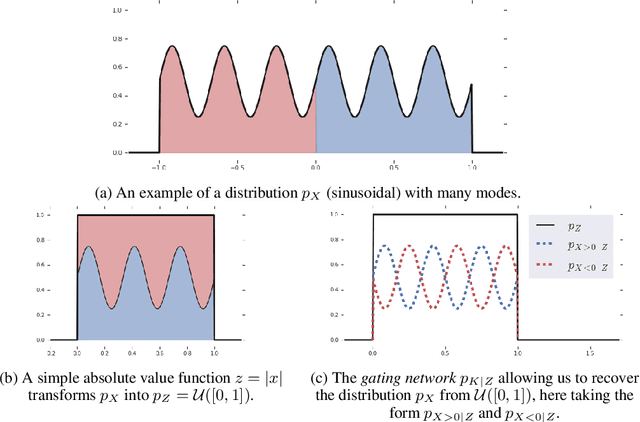
Flow based models such as Real NVP are an extremely powerful approach to density estimation. However, existing flow based models are restricted to transforming continuous densities over a continuous input space into similarly continuous distributions over continuous latent variables. This makes them poorly suited for modeling and representing discrete structures in data distributions, for example class membership or discrete symmetries. To address this difficulty, we present a normalizing flow architecture which relies on domain partitioning using locally invertible functions, and possesses both real and discrete valued latent variables. This Real and Discrete (RAD) approach retains the desirable normalizing flow properties of exact sampling, exact inference, and analytically computable probabilities, while at the same time allowing simultaneous modeling of both continuous and discrete structure in a data distribution.
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
Mar 07, 2019
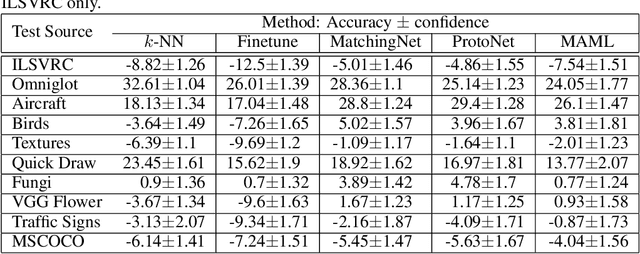

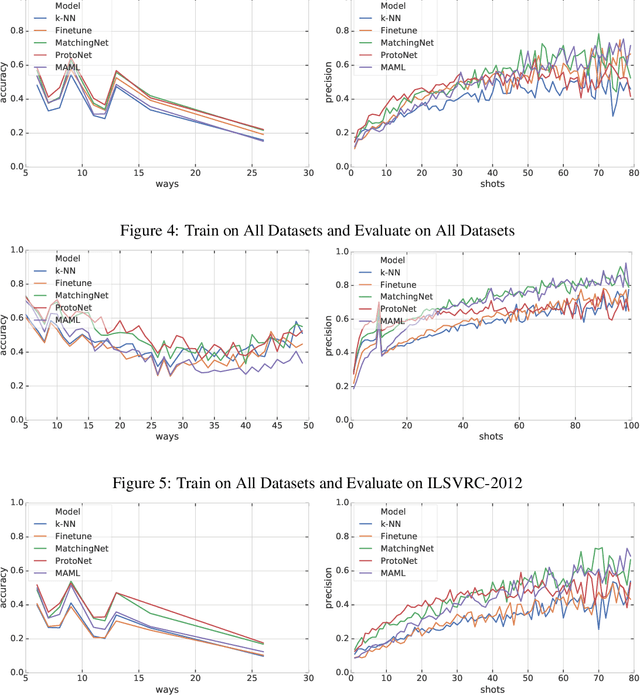
Few-shot classification refers to learning a classifier for new classes given only a few examples. While a plethora of models have emerged to tackle this recently, we find the current procedure and datasets that are used to systematically assess progress in this setting lacking. To address this, we propose Meta-Dataset: a new benchmark for training and evaluating few-shot classifiers that is large-scale, consists of multiple datasets, and presents more natural and realistic tasks. The aim is to measure the ability of state-of-the-art models to leverage diverse sources of data to achieve higher generalization, and to evaluate that generalization ability in a more challenging setting. We additionally measure robustness of current methods to variations in the number of available examples and the number of classes. Finally our extensive empirical evaluation leads us to identify weaknesses in Prototypical Networks and MAML, two popular few-shot classification methods, and to propose a new method, Proto-MAML, which achieves improved performance on our benchmark.
Hyperbolic Discounting and Learning over Multiple Horizons
Feb 28, 2019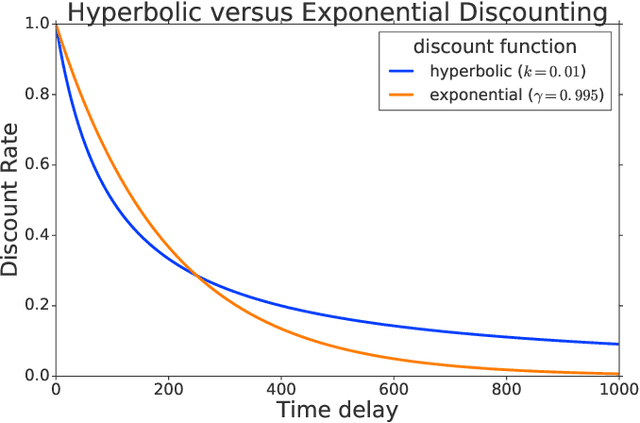

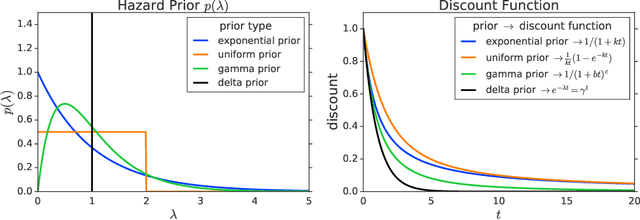
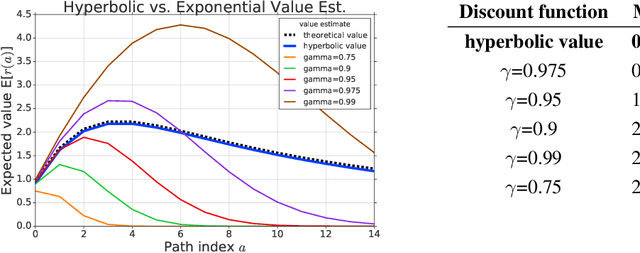
Reinforcement learning (RL) typically defines a discount factor as part of the Markov Decision Process. The discount factor values future rewards by an exponential scheme that leads to theoretical convergence guarantees of the Bellman equation. However, evidence from psychology, economics and neuroscience suggests that humans and animals instead have hyperbolic time-preferences. In this work we revisit the fundamentals of discounting in RL and bridge this disconnect by implementing an RL agent that acts via hyperbolic discounting. We demonstrate that a simple approach approximates hyperbolic discount functions while still using familiar temporal-difference learning techniques in RL. Additionally, and independent of hyperbolic discounting, we make a surprising discovery that simultaneously learning value functions over multiple time-horizons is an effective auxiliary task which often improves over a strong value-based RL agent, Rainbow.
Centroid Networks for Few-Shot Clustering and Unsupervised Few-Shot Classification
Feb 22, 2019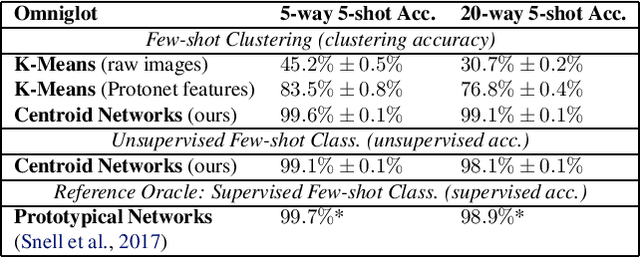
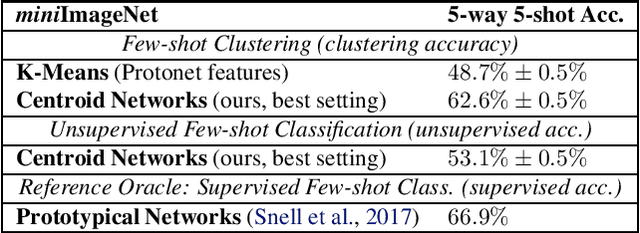
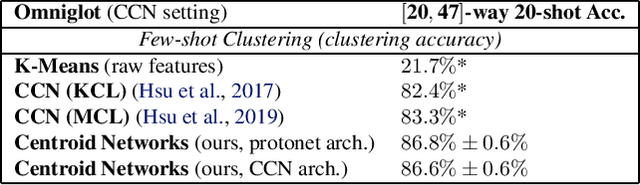
Traditional clustering algorithms such as K-means rely heavily on the nature of the chosen metric or data representation. To get meaningful clusters, these representations need to be tailored to the downstream task (e.g. cluster photos by object category, cluster faces by identity). Therefore, we frame clustering as a meta-learning task, few-shot clustering, which allows us to specify how to cluster the data at the meta-training level, despite the clustering algorithm itself being unsupervised. We propose Centroid Networks, a simple and efficient few-shot clustering method based on learning representations which are tailored both to the task to solve and to its internal clustering module. We also introduce unsupervised few-shot classification, which is conceptually similar to few-shot clustering, but is strictly harder than supervised* few-shot classification and therefore allows direct comparison with existing supervised few-shot classification methods. On Omniglot and miniImageNet, our method achieves accuracy competitive with popular supervised few-shot classification algorithms, despite using *no labels* from the support set. We also show performance competitive with state-of-the-art learning-to-cluster methods.
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019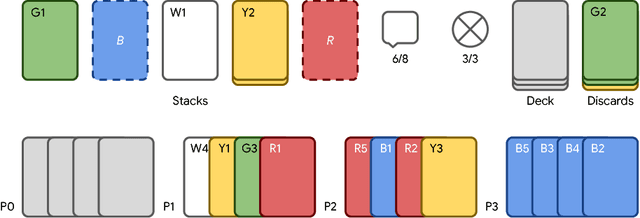
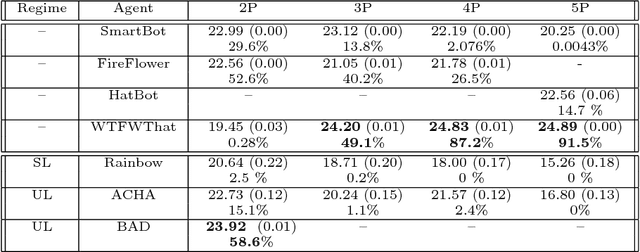
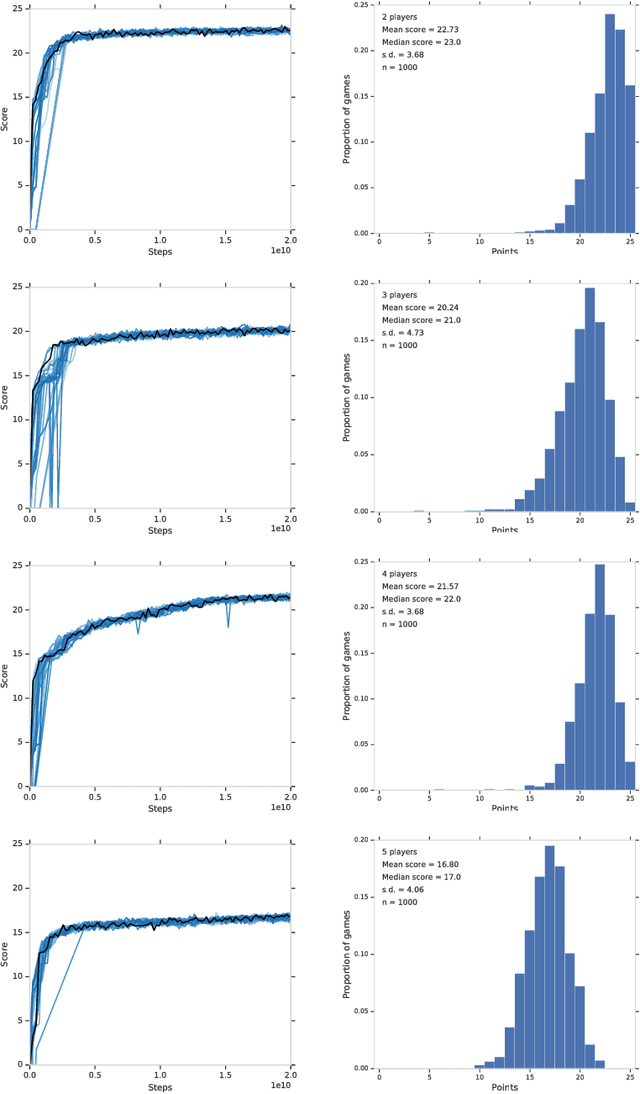
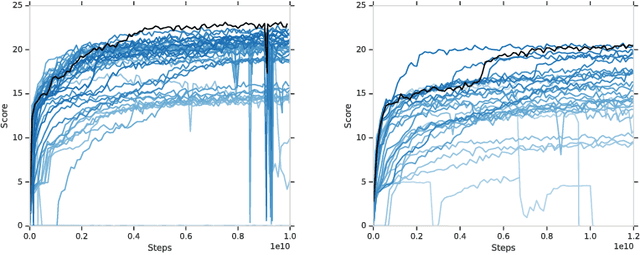
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
Blindfold Baselines for Embodied QA
Nov 12, 2018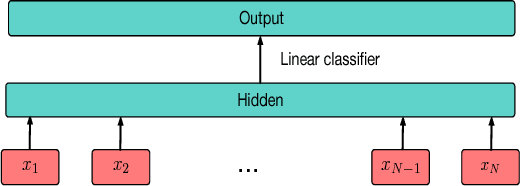
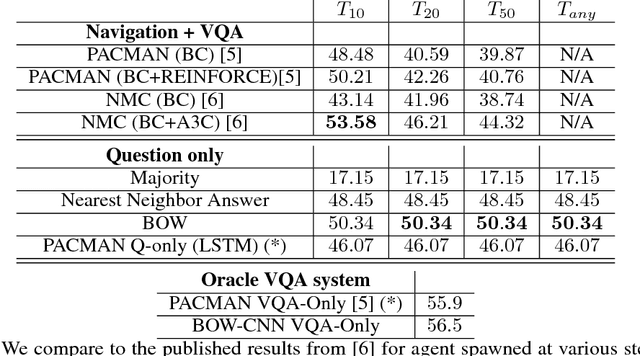
We explore blindfold (question-only) baselines for Embodied Question Answering. The EmbodiedQA task requires an agent to answer a question by intelligently navigating in a simulated environment, gathering necessary visual information only through first-person vision before finally answering. Consequently, a blindfold baseline which ignores the environment and visual information is a degenerate solution, yet we show through our experiments on the EQAv1 dataset that a simple question-only baseline achieves state-of-the-art results on the EmbodiedQA task in all cases except when the agent is spawned extremely close to the object.
Language GANs Falling Short
Nov 08, 2018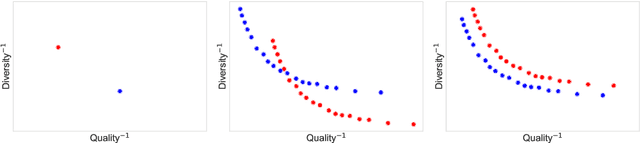

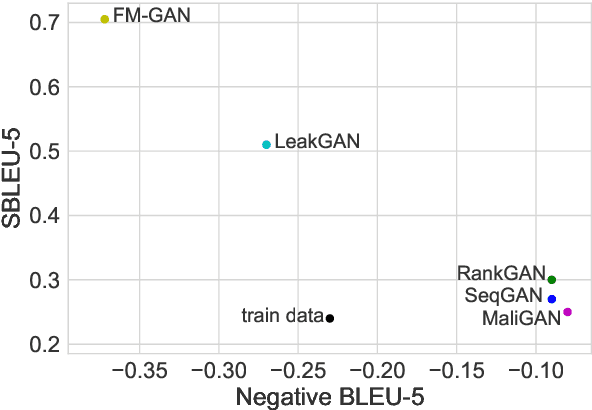
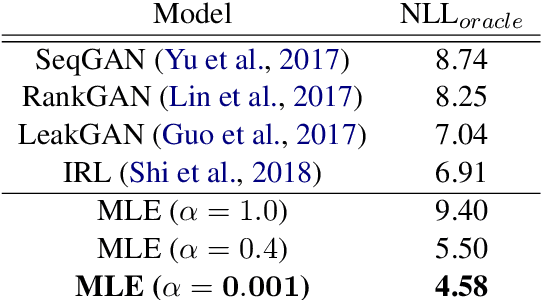
Generating high-quality text with sufficient diversity is essential for a wide range of Natural Language Generation (NLG) tasks. Maximum-Likelihood (MLE) models trained with teacher forcing have constantly been reported as weak baselines, where poor performance is attributed to exposure bias; at inference time, the model is fed its own prediction instead of a ground-truth token, which can lead to accumulating errors and poor samples. This line of reasoning has led to an outbreak of adversarial based approaches for NLG, on the account that GANs do not suffer from exposure bias. In this work, we make several surprising observations with contradict common beliefs. We first revisit the canonical evaluation framework for NLG, and point out fundamental flaws with quality-only evaluation: we show that one can outperform such metrics using a simple, well-known temperature parameter to artificially reduce the entropy of the model's conditional distributions. Second, we leverage the control over the quality / diversity tradeoff given by this parameter to evaluate models over the whole quality-diversity spectrum, and find MLE models constantly outperform the proposed GAN variants, over the whole quality-diversity space. Our results have several implications: 1) The impact of exposure bias on sample quality is less severe than previously thought, 2) temperature tuning provides a better quality / diversity trade off than adversarial training, while being easier to train, easier to cross-validate, and less computationally expensive.
Recall Traces: Backtracking Models for Efficient Reinforcement Learning
Apr 02, 2018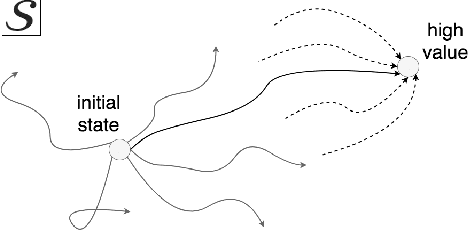

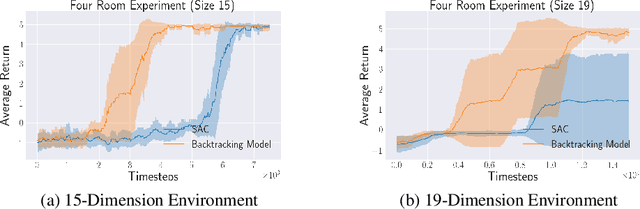

In many environments only a tiny subset of all states yield high reward. In these cases, few of the interactions with the environment provide a relevant learning signal. Hence, we may want to preferentially train on those high-reward states and the probable trajectories leading to them. To this end, we advocate for the use of a backtracking model that predicts the preceding states that terminate at a given high-reward state. We can train a model which, starting from a high value state (or one that is estimated to have high value), predicts and sample for which the (state, action)-tuples may have led to that high value state. These traces of (state, action) pairs, which we refer to as Recall Traces, sampled from this backtracking model starting from a high value state, are informative as they terminate in good states, and hence we can use these traces to improve a policy. We provide a variational interpretation for this idea and a practical algorithm in which the backtracking model samples from an approximate posterior distribution over trajectories which lead to large rewards. Our method improves the sample efficiency of both on- and off-policy RL algorithms across several environments and tasks.
Meta-Learning for Semi-Supervised Few-Shot Classification
Mar 02, 2018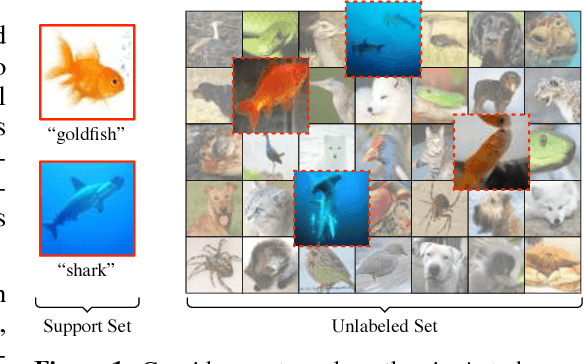
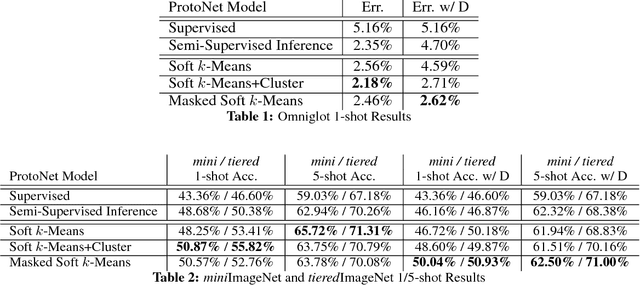
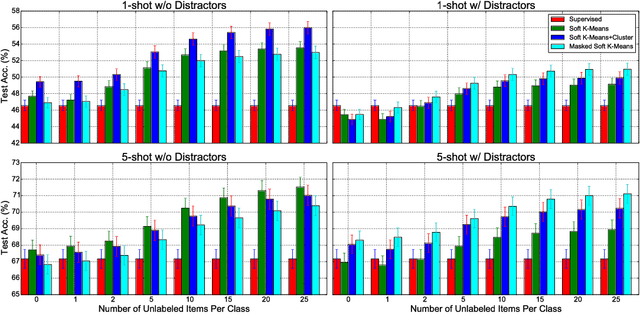
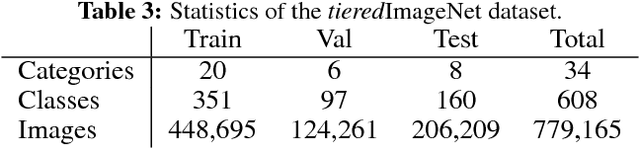
In few-shot classification, we are interested in learning algorithms that train a classifier from only a handful of labeled examples. Recent progress in few-shot classification has featured meta-learning, in which a parameterized model for a learning algorithm is defined and trained on episodes representing different classification problems, each with a small labeled training set and its corresponding test set. In this work, we advance this few-shot classification paradigm towards a scenario where unlabeled examples are also available within each episode. We consider two situations: one where all unlabeled examples are assumed to belong to the same set of classes as the labeled examples of the episode, as well as the more challenging situation where examples from other distractor classes are also provided. To address this paradigm, we propose novel extensions of Prototypical Networks (Snell et al., 2017) that are augmented with the ability to use unlabeled examples when producing prototypes. These models are trained in an end-to-end way on episodes, to learn to leverage the unlabeled examples successfully. We evaluate these methods on versions of the Omniglot and miniImageNet benchmarks, adapted to this new framework augmented with unlabeled examples. We also propose a new split of ImageNet, consisting of a large set of classes, with a hierarchical structure. Our experiments confirm that our Prototypical Networks can learn to improve their predictions due to unlabeled examples, much like a semi-supervised algorithm would.
Disentangling the independently controllable factors of variation by interacting with the world
Feb 26, 2018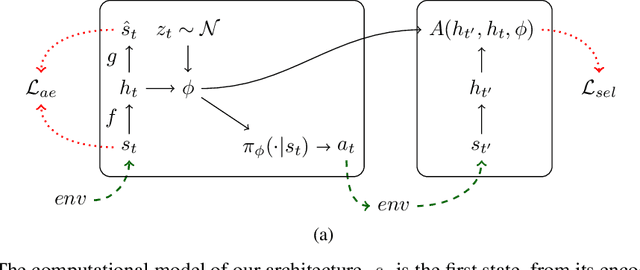
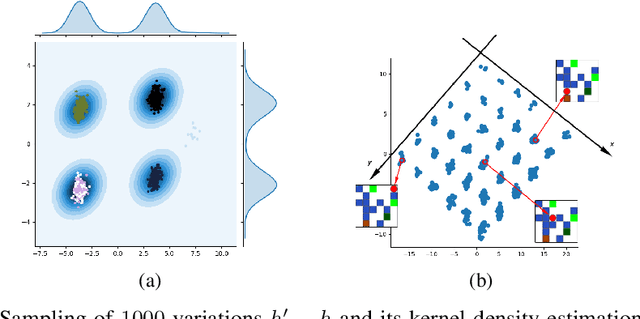
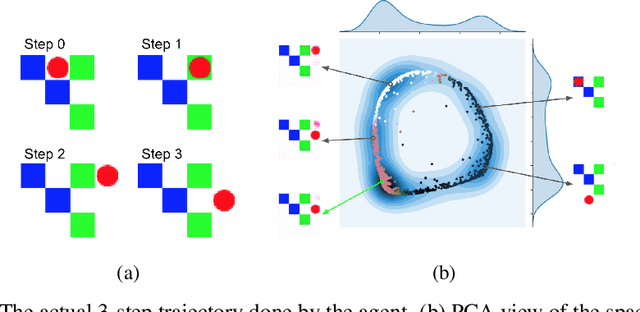
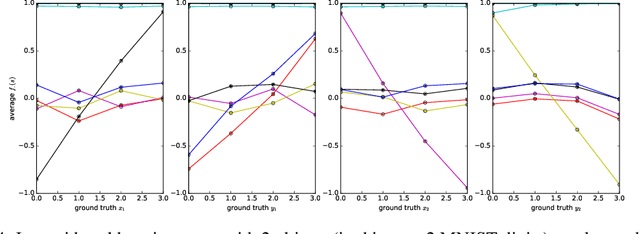
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors, and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.