 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowDreamer: A RGB-D World Model with Flow-based Motion Representations for Robot Manipulation
May 15, 2025



This paper investigates training better visual world models for robot manipulation, i.e., models that can predict future visual observations by conditioning on past frames and robot actions. Specifically, we consider world models that operate on RGB-D frames (RGB-D world models). As opposed to canonical approaches that handle dynamics prediction mostly implicitly and reconcile it with visual rendering in a single model, we introduce FlowDreamer, which adopts 3D scene flow as explicit motion representations. FlowDreamer first predicts 3D scene flow from past frame and action conditions with a U-Net, and then a diffusion model will predict the future frame utilizing the scene flow. FlowDreamer is trained end-to-end despite its modularized nature. We conduct experiments on 4 different benchmarks, covering both video prediction and visual planning tasks. The results demonstrate that FlowDreamer achieves better performance compared to other baseline RGB-D world models by 7% on semantic similarity, 11% on pixel quality, and 6% on success rate in various robot manipulation domains.
LLM Enhancers for GNNs: An Analysis from the Perspective of Causal Mechanism Identification
May 13, 2025The use of large language models (LLMs) as feature enhancers to optimize node representations, which are then used as inputs for graph neural networks (GNNs), has shown significant potential in graph representation learning. However, the fundamental properties of this approach remain underexplored. To address this issue, we propose conducting a more in-depth analysis of this issue based on the interchange intervention method. First, we construct a synthetic graph dataset with controllable causal relationships, enabling precise manipulation of semantic relationships and causal modeling to provide data for analysis. Using this dataset, we conduct interchange interventions to examine the deeper properties of LLM enhancers and GNNs, uncovering their underlying logic and internal mechanisms. Building on the analytical results, we design a plug-and-play optimization module to improve the information transfer between LLM enhancers and GNNs. Experiments across multiple datasets and models validate the proposed module.
Trajectory Entropy Reinforcement Learning for Predictable and Robust Control
May 07, 2025Simplicity is a critical inductive bias for designing data-driven controllers, especially when robustness is important. Despite the impressive results of deep reinforcement learning in complex control tasks, it is prone to capturing intricate and spurious correlations between observations and actions, leading to failure under slight perturbations to the environment. To tackle this problem, in this work we introduce a novel inductive bias towards simple policies in reinforcement learning. The simplicity inductive bias is introduced by minimizing the entropy of entire action trajectories, corresponding to the number of bits required to describe information in action trajectories after the agent observes state trajectories. Our reinforcement learning agent, Trajectory Entropy Reinforcement Learning, is optimized to minimize the trajectory entropy while maximizing rewards. We show that the trajectory entropy can be effectively estimated by learning a variational parameterized action prediction model, and use the prediction model to construct an information-regularized reward function. Furthermore, we construct a practical algorithm that enables the joint optimization of models, including the policy and the prediction model. Experimental evaluations on several high-dimensional locomotion tasks show that our learned policies produce more cyclical and consistent action trajectories, and achieve superior performance, and robustness to noise and dynamic changes than the state-of-the-art.
A General Infrastructure and Workflow for Quadrotor Deep Reinforcement Learning and Reality Deployment
Apr 21, 2025Deploying robot learning methods to a quadrotor in unstructured outdoor environments is an exciting task. Quadrotors operating in real-world environments by learning-based methods encounter several challenges: a large amount of simulator generated data required for training, strict demands for real-time processing onboard, and the sim-to-real gap caused by dynamic and noisy conditions. Current works have made a great breakthrough in applying learning-based methods to end-to-end control of quadrotors, but rarely mention the infrastructure system training from scratch and deploying to reality, which makes it difficult to reproduce methods and applications. To bridge this gap, we propose a platform that enables the seamless transfer of end-to-end deep reinforcement learning (DRL) policies. We integrate the training environment, flight dynamics control, DRL algorithms, the MAVROS middleware stack, and hardware into a comprehensive workflow and architecture that enables quadrotors' policies to be trained from scratch to real-world deployment in several minutes. Our platform provides rich types of environments including hovering, dynamic obstacle avoidance, trajectory tracking, balloon hitting, and planning in unknown environments, as a physical experiment benchmark. Through extensive empirical validation, we demonstrate the efficiency of proposed sim-to-real platform, and robust outdoor flight performance under real-world perturbations. Details can be found from our website https://emnavi.tech/AirGym/.
MMTL-UniAD: A Unified Framework for Multimodal and Multi-Task Learning in Assistive Driving Perception
Apr 03, 2025Advanced driver assistance systems require a comprehensive understanding of the driver's mental/physical state and traffic context but existing works often neglect the potential benefits of joint learning between these tasks. This paper proposes MMTL-UniAD, a unified multi-modal multi-task learning framework that simultaneously recognizes driver behavior (e.g., looking around, talking), driver emotion (e.g., anxiety, happiness), vehicle behavior (e.g., parking, turning), and traffic context (e.g., traffic jam, traffic smooth). A key challenge is avoiding negative transfer between tasks, which can impair learning performance. To address this, we introduce two key components into the framework: one is the multi-axis region attention network to extract global context-sensitive features, and the other is the dual-branch multimodal embedding to learn multimodal embeddings from both task-shared and task-specific features. The former uses a multi-attention mechanism to extract task-relevant features, mitigating negative transfer caused by task-unrelated features. The latter employs a dual-branch structure to adaptively adjust task-shared and task-specific parameters, enhancing cross-task knowledge transfer while reducing task conflicts. We assess MMTL-UniAD on the AIDE dataset, using a series of ablation studies, and show that it outperforms state-of-the-art methods across all four tasks. The code is available on https://github.com/Wenzhuo-Liu/MMTL-UniAD.
Conditional Diffusion Model for Electrical Impedance Tomography
Jan 10, 2025



Electrical impedance tomography (EIT) is a non-invasive imaging technique, which has been widely used in the fields of industrial inspection, medical monitoring and tactile sensing. However, due to the inherent non-linearity and ill-conditioned nature of the EIT inverse problem, the reconstructed image is highly sensitive to the measured data, and random noise artifacts often appear in the reconstructed image, which greatly limits the application of EIT. To address this issue, a conditional diffusion model with voltage consistency (CDMVC) is proposed in this study. The method consists of a pre-imaging module, a conditional diffusion model for reconstruction, a forward voltage constraint network and a scheme of voltage consistency constraint during sampling process. The pre-imaging module is employed to generate the initial reconstruction. This serves as a condition for training the conditional diffusion model. Finally, based on the forward voltage constraint network, a voltage consistency constraint is implemented in the sampling phase to incorporate forward information of EIT, thereby enhancing imaging quality. A more complete dataset, including both common and complex concave shapes, is generated. The proposed method is validated using both simulation and physical experiments. Experimental results demonstrate that our method can significantly improves the quality of reconstructed images. In addition, experimental results also demonstrate that our method has good robustness and generalization performance.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024
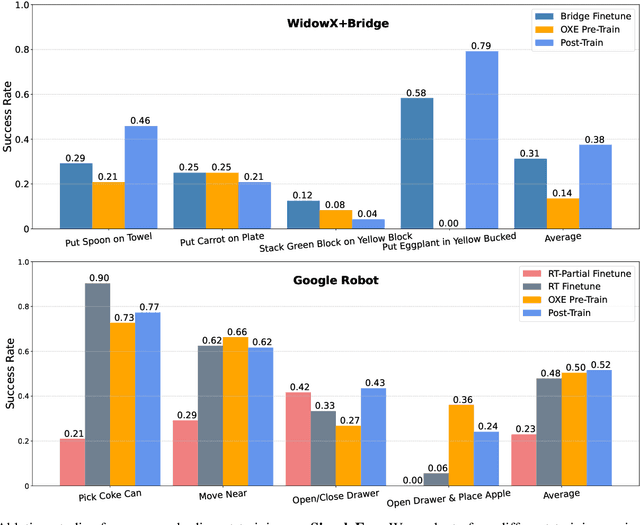

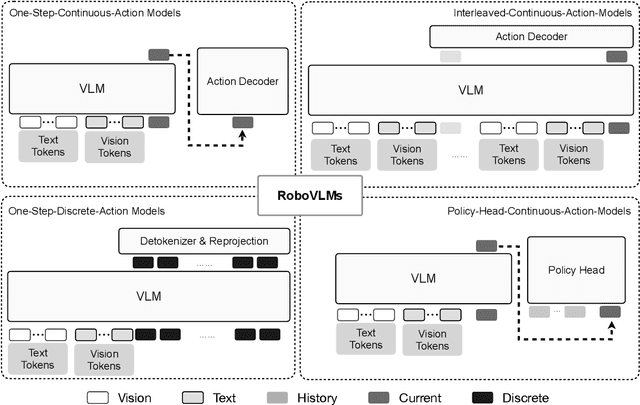
Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
Bootstrapping Heterogeneous Graph Representation Learning via Large Language Models: A Generalized Approach
Dec 11, 2024



Graph representation learning methods are highly effective in handling complex non-Euclidean data by capturing intricate relationships and features within graph structures. However, traditional methods face challenges when dealing with heterogeneous graphs that contain various types of nodes and edges due to the diverse sources and complex nature of the data. Existing Heterogeneous Graph Neural Networks (HGNNs) have shown promising results but require prior knowledge of node and edge types and unified node feature formats, which limits their applicability. Recent advancements in graph representation learning using Large Language Models (LLMs) offer new solutions by integrating LLMs' data processing capabilities, enabling the alignment of various graph representations. Nevertheless, these methods often overlook heterogeneous graph data and require extensive preprocessing. To address these limitations, we propose a novel method that leverages the strengths of both LLM and GNN, allowing for the processing of graph data with any format and type of nodes and edges without the need for type information or special preprocessing. Our method employs LLM to automatically summarize and classify different data formats and types, aligns node features, and uses a specialized GNN for targeted learning, thus obtaining effective graph representations for downstream tasks. Theoretical analysis and experimental validation have demonstrated the effectiveness of our method.
A High-frequency Pneumatic Oscillator for Soft Robotics
Nov 12, 2024



Soft robots, while highly adaptable to diverse environments through various actuation methods, still face significant performance boundary due to the inherent properties of materials. These limitations manifest in the challenge of guaranteeing rapid response and large-scale movements simultaneously, ultimately restricting the robots' absolute speed and overall efficiency. In this paper, we introduce a high-frequency pneumatic oscillator (HIPO) to overcome these challenges. Through a collision-induced phase resetting mechanism, our HIPO leverages event-based nonlinearity to trigger self-oscillation of pneumatic actuator, which positively utilizes intrinsic characteristics of materials. This enables the system to spontaneously generate periodic control signals and directly produce motion responses, eliminating the need for incorporating external actuation components. By efficiently and rapidly converting internal energy of airflow into the kinetic energy of robots, HIPO achieves a frequency of up to 20 Hz. Furthermore, we demonstrate the versatility and high-performance capabilities of HIPO through bio-inspired robots: an insect-like fast-crawler (with speeds up to 50.27 cm/s), a high-frequency butterfly-like wing-flapper, and a maneuverable duck-like swimmer. By eliminating external components and seamlessly fusing signal generation, energy conversion, and motion output, HIPO unleashes rapid and efficient motion, unlocking potential for high-performance soft robotics.
MIPD: A Multi-sensory Interactive Perception Dataset for Embodied Intelligent Driving
Nov 08, 2024



During the process of driving, humans usually rely on multiple senses to gather information and make decisions. Analogously, in order to achieve embodied intelligence in autonomous driving, it is essential to integrate multidimensional sensory information in order to facilitate interaction with the environment. However, the current multi-modal fusion sensing schemes often neglect these additional sensory inputs, hindering the realization of fully autonomous driving. This paper considers multi-sensory information and proposes a multi-modal interactive perception dataset named MIPD, enabling expanding the current autonomous driving algorithm framework, for supporting the research on embodied intelligent driving. In addition to the conventional camera, lidar, and 4D radar data, our dataset incorporates multiple sensor inputs including sound, light intensity, vibration intensity and vehicle speed to enrich the dataset comprehensiveness. Comprising 126 consecutive sequences, many exceeding twenty seconds, MIPD features over 8,500 meticulously synchronized and annotated frames. Moreover, it encompasses many challenging scenarios, covering various road and lighting conditions. The dataset has undergone thorough experimental validation, producing valuable insights for the exploration of next-generation autonomous driving frameworks.