 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Total Correlation Reinforcement Learning
May 22, 2025Simplicity is a powerful inductive bias. In reinforcement learning, regularization is used for simpler policies, data augmentation for simpler representations, and sparse reward functions for simpler objectives, all that, with the underlying motivation to increase generalizability and robustness by focusing on the essentials. Supplementary to these techniques, we investigate how to promote simple behavior throughout the episode. To that end, we introduce a modification of the reinforcement learning problem that additionally maximizes the total correlation within the induced trajectories. We propose a practical algorithm that optimizes all models, including policy and state representation, based on a lower-bound approximation. In simulated robot environments, our method naturally generates policies that induce periodic and compressible trajectories, and that exhibit superior robustness to noise and changes in dynamics compared to baseline methods, while also improving performance in the original tasks.
Trajectory Entropy Reinforcement Learning for Predictable and Robust Control
May 07, 2025



Simplicity is a critical inductive bias for designing data-driven controllers, especially when robustness is important. Despite the impressive results of deep reinforcement learning in complex control tasks, it is prone to capturing intricate and spurious correlations between observations and actions, leading to failure under slight perturbations to the environment. To tackle this problem, in this work we introduce a novel inductive bias towards simple policies in reinforcement learning. The simplicity inductive bias is introduced by minimizing the entropy of entire action trajectories, corresponding to the number of bits required to describe information in action trajectories after the agent observes state trajectories. Our reinforcement learning agent, Trajectory Entropy Reinforcement Learning, is optimized to minimize the trajectory entropy while maximizing rewards. We show that the trajectory entropy can be effectively estimated by learning a variational parameterized action prediction model, and use the prediction model to construct an information-regularized reward function. Furthermore, we construct a practical algorithm that enables the joint optimization of models, including the policy and the prediction model. Experimental evaluations on several high-dimensional locomotion tasks show that our learned policies produce more cyclical and consistent action trajectories, and achieve superior performance, and robustness to noise and dynamic changes than the state-of-the-art.
Multimodal Information Bottleneck for Deep Reinforcement Learning with Multiple Sensors
Oct 23, 2024Reinforcement learning has achieved promising results on robotic control tasks but struggles to leverage information effectively from multiple sensory modalities that differ in many characteristics. Recent works construct auxiliary losses based on reconstruction or mutual information to extract joint representations from multiple sensory inputs to improve the sample efficiency and performance of reinforcement learning algorithms. However, the representations learned by these methods could capture information irrelevant to learning a policy and may degrade the performance. We argue that compressing information in the learned joint representations about raw multimodal observations is helpful, and propose a multimodal information bottleneck model to learn task-relevant joint representations from egocentric images and proprioception. Our model compresses and retains the predictive information in multimodal observations for learning a compressed joint representation, which fuses complementary information from visual and proprioceptive feedback and meanwhile filters out task-irrelevant information in raw multimodal observations. We propose to minimize the upper bound of our multimodal information bottleneck objective for computationally tractable optimization. Experimental evaluations on several challenging locomotion tasks with egocentric images and proprioception show that our method achieves better sample efficiency and zero-shot robustness to unseen white noise than leading baselines. We also empirically demonstrate that leveraging information from egocentric images and proprioception is more helpful for learning policies on locomotion tasks than solely using one single modality.
* 31 pages
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022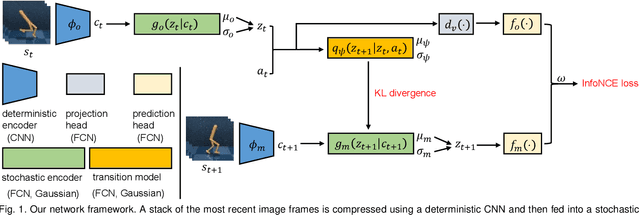
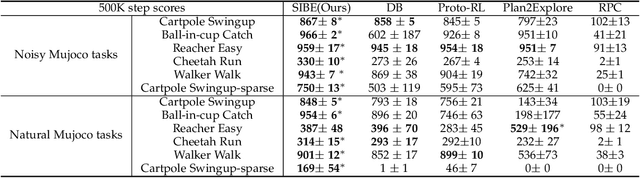
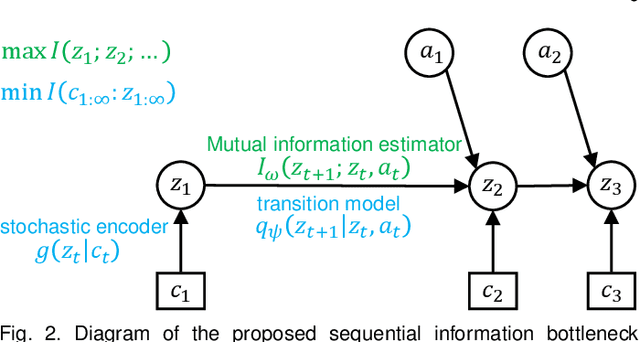

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
Integrating Contrastive Learning with Dynamic Models for Reinforcement Learning from Images
Mar 02, 2022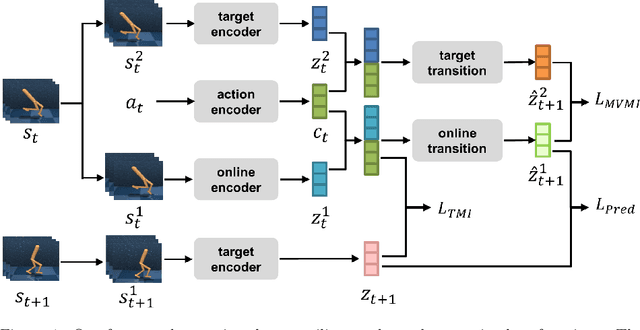

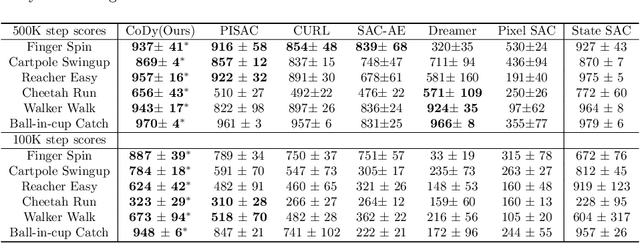
Recent methods for reinforcement learning from images use auxiliary tasks to learn image features that are used by the agent's policy or Q-function. In particular, methods based on contrastive learning that induce linearity of the latent dynamics or invariance to data augmentation have been shown to greatly improve the sample efficiency of the reinforcement learning algorithm and the generalizability of the learned embedding. We further argue, that explicitly improving Markovianity of the learned embedding is desirable and propose a self-supervised representation learning method which integrates contrastive learning with dynamic models to synergistically combine these three objectives: (1) We maximize the InfoNCE bound on the mutual information between the state- and action-embedding and the embedding of the next state to induce a linearly predictive embedding without explicitly learning a linear transition model, (2) we further improve Markovianity of the learned embedding by explicitly learning a non-linear transition model using regression, and (3) we maximize the mutual information between the two nonlinear predictions of the next embeddings based on the current action and two independent augmentations of the current state, which naturally induces transformation invariance not only for the state embedding, but also for the nonlinear transition model. Experimental evaluation on the Deepmind control suite shows that our proposed method achieves higher sample efficiency and better generalization than state-of-art methods based on contrastive learning or reconstruction.
* 28 pages, 11 figures, 5 tables