 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality Guided Representation Learning for Cross-Style Hate Speech Detection
Oct 09, 2025



The proliferation of online hate speech poses a significant threat to the harmony of the web. While explicit hate is easily recognized through overt slurs, implicit hate speech is often conveyed through sarcasm, irony, stereotypes, or coded language -- making it harder to detect. Existing hate speech detection models, which predominantly rely on surface-level linguistic cues, fail to generalize effectively across diverse stylistic variations. Moreover, hate speech spread on different platforms often targets distinct groups and adopts unique styles, potentially inducing spurious correlations between them and labels, further challenging current detection approaches. Motivated by these observations, we hypothesize that the generation of hate speech can be modeled as a causal graph involving key factors: contextual environment, creator motivation, target, and style. Guided by this graph, we propose CADET, a causal representation learning framework that disentangles hate speech into interpretable latent factors and then controls confounders, thereby isolating genuine hate intent from superficial linguistic cues. Furthermore, CADET allows counterfactual reasoning by intervening on style within the latent space, naturally guiding the model to robustly identify hate speech in varying forms. CADET demonstrates superior performance in comprehensive experiments, highlighting the potential of causal priors in advancing generalizable hate speech detection.
Generative Models for Synthetic Data: Transforming Data Mining in the GenAI Era
Aug 27, 2025Generative models such as Large Language Models, Diffusion Models, and generative adversarial networks have recently revolutionized the creation of synthetic data, offering scalable solutions to data scarcity, privacy, and annotation challenges in data mining. This tutorial introduces the foundations and latest advances in synthetic data generation, covers key methodologies and practical frameworks, and discusses evaluation strategies and applications. Attendees will gain actionable insights into leveraging generative synthetic data to enhance data mining research and practice. More information can be found on our website: https://syndata4dm.github.io/.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Are Today's LLMs Ready to Explain Well-Being Concepts?
Aug 06, 2025Well-being encompasses mental, physical, and social dimensions essential to personal growth and informed life decisions. As individuals increasingly consult Large Language Models (LLMs) to understand well-being, a key challenge emerges: Can LLMs generate explanations that are not only accurate but also tailored to diverse audiences? High-quality explanations require both factual correctness and the ability to meet the expectations of users with varying expertise. In this work, we construct a large-scale dataset comprising 43,880 explanations of 2,194 well-being concepts, generated by ten diverse LLMs. We introduce a principle-guided LLM-as-a-judge evaluation framework, employing dual judges to assess explanation quality. Furthermore, we show that fine-tuning an open-source LLM using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) can significantly enhance the quality of generated explanations. Our results reveal: (1) The proposed LLM judges align well with human evaluations; (2) explanation quality varies significantly across models, audiences, and categories; and (3) DPO- and SFT-finetuned models outperform their larger counterparts, demonstrating the effectiveness of preference-based learning for specialized explanation tasks.
HGMP:Heterogeneous Graph Multi-Task Prompt Learning
Jul 10, 2025



The pre-training and fine-tuning methods have gained widespread attention in the field of heterogeneous graph neural networks due to their ability to leverage large amounts of unlabeled data during the pre-training phase, allowing the model to learn rich structural features. However, these methods face the issue of a mismatch between the pre-trained model and downstream tasks, leading to suboptimal performance in certain application scenarios. Prompt learning methods have emerged as a new direction in heterogeneous graph tasks, as they allow flexible adaptation of task representations to address target inconsistency. Building on this idea, this paper proposes a novel multi-task prompt framework for the heterogeneous graph domain, named HGMP. First, to bridge the gap between the pre-trained model and downstream tasks, we reformulate all downstream tasks into a unified graph-level task format. Next, we address the limitations of existing graph prompt learning methods, which struggle to integrate contrastive pre-training strategies in the heterogeneous graph domain. We design a graph-level contrastive pre-training strategy to better leverage heterogeneous information and enhance performance in multi-task scenarios. Finally, we introduce heterogeneous feature prompts, which enhance model performance by refining the representation of input graph features. Experimental results on public datasets show that our proposed method adapts well to various tasks and significantly outperforms baseline methods.
Domain Knowledge-Enhanced LLMs for Fraud and Concept Drift Detection
Jun 26, 2025Detecting deceptive conversations on dynamic platforms is increasingly difficult due to evolving language patterns and Concept Drift (CD)\-i.e., semantic or topical shifts that alter the context or intent of interactions over time. These shifts can obscure malicious intent or mimic normal dialogue, making accurate classification challenging. While Large Language Models (LLMs) show strong performance in natural language tasks, they often struggle with contextual ambiguity and hallucinations in risk\-sensitive scenarios. To address these challenges, we present a Domain Knowledge (DK)\-Enhanced LLM framework that integrates pretrained LLMs with structured, task\-specific insights to perform fraud and concept drift detection. The proposed architecture consists of three main components: (1) a DK\-LLM module to detect fake or deceptive conversations; (2) a drift detection unit (OCDD) to determine whether a semantic shift has occurred; and (3) a second DK\-LLM module to classify the drift as either benign or fraudulent. We first validate the value of domain knowledge using a fake review dataset and then apply our full framework to SEConvo, a multiturn dialogue dataset that includes various types of fraud and spam attacks. Results show that our system detects fake conversations with high accuracy and effectively classifies the nature of drift. Guided by structured prompts, the LLaMA\-based implementation achieves 98\% classification accuracy. Comparative studies against zero\-shot baselines demonstrate that incorporating domain knowledge and drift awareness significantly improves performance, interpretability, and robustness in high\-stakes NLP applications.
Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
Jun 25, 2025



Agents based on Large Language Models (LLMs) have demonstrated strong capabilities across a wide range of tasks. However, deploying LLM-based agents in high-stakes domains comes with significant safety and ethical risks. Unethical behavior by these agents can directly result in serious real-world consequences, including physical harm and financial loss. To efficiently steer the ethical behavior of agents, we frame agent behavior steering as a model editing task, which we term Behavior Editing. Model editing is an emerging area of research that enables precise and efficient modifications to LLMs while preserving their overall capabilities. To systematically study and evaluate this approach, we introduce BehaviorBench, a multi-tier benchmark grounded in psychological moral theories. This benchmark supports both the evaluation and editing of agent behaviors across a variety of scenarios, with each tier introducing more complex and ambiguous scenarios. We first demonstrate that Behavior Editing can dynamically steer agents toward the target behavior within specific scenarios. Moreover, Behavior Editing enables not only scenario-specific local adjustments but also more extensive shifts in an agent's global moral alignment. We demonstrate that Behavior Editing can be used to promote ethical and benevolent behavior or, conversely, to induce harmful or malicious behavior. Through comprehensive evaluations on agents based on frontier LLMs, BehaviorBench shows the effectiveness of Behavior Editing across different models and scenarios. Our findings offer key insights into a new paradigm for steering agent behavior, highlighting both the promise and perils of Behavior Editing.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025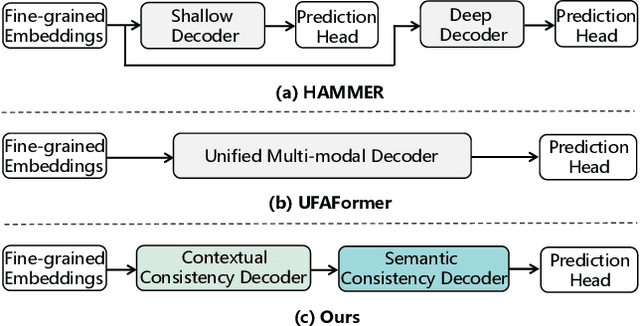
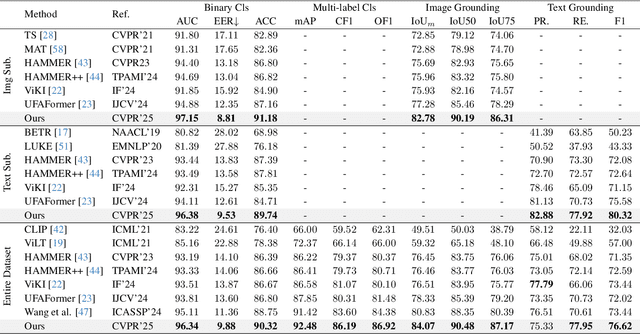
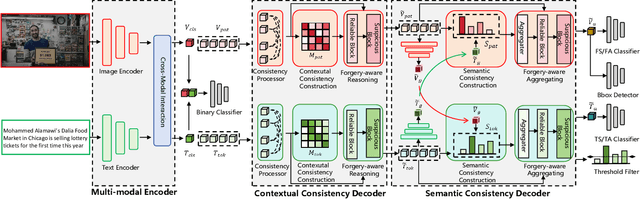
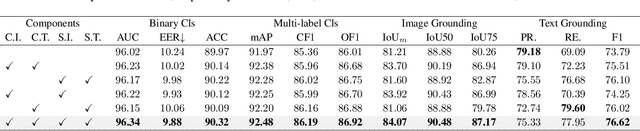
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.
DOGe: Defensive Output Generation for LLM Protection Against Knowledge Distillation
May 26, 2025
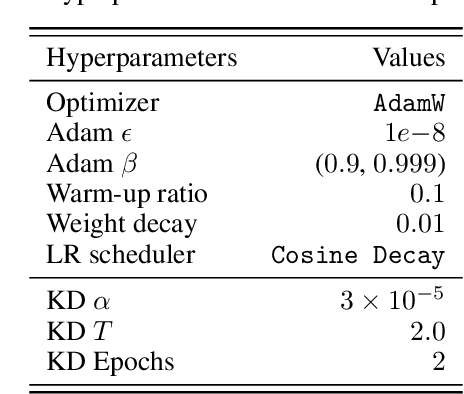
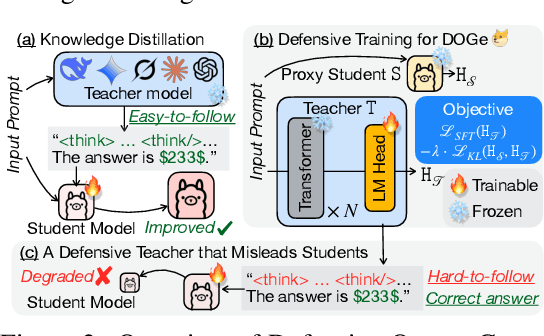

Large Language Models (LLMs) represent substantial intellectual and economic investments, yet their effectiveness can inadvertently facilitate model imitation via knowledge distillation (KD).In practical scenarios, competitors can distill proprietary LLM capabilities by simply observing publicly accessible outputs, akin to reverse-engineering a complex performance by observation alone. Existing protective methods like watermarking only identify imitation post-hoc, while other defenses assume the student model mimics the teacher's internal logits, rendering them ineffective against distillation purely from observed output text. This paper confronts the challenge of actively protecting LLMs within the realistic constraints of API-based access. We introduce an effective and efficient Defensive Output Generation (DOGe) strategy that subtly modifies the output behavior of an LLM. Its outputs remain accurate and useful for legitimate users, yet are designed to be misleading for distillation, significantly undermining imitation attempts. We achieve this by fine-tuning only the final linear layer of the teacher LLM with an adversarial loss. This targeted training approach anticipates and disrupts distillation attempts during inference time. Our experiments show that, while preserving or even improving the original performance of the teacher model, student models distilled from the defensively generated teacher outputs demonstrate catastrophically reduced performance, demonstrating our method's effectiveness as a practical safeguard against KD-based model imitation.
Joint Detection of Fraud and Concept Drift inOnline Conversations with LLM-Assisted Judgment
May 07, 2025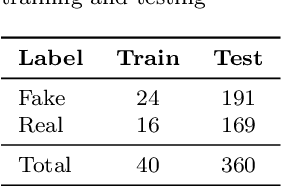
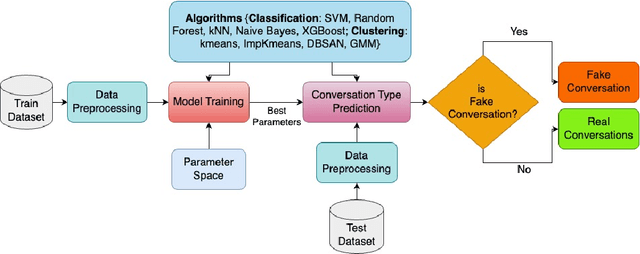
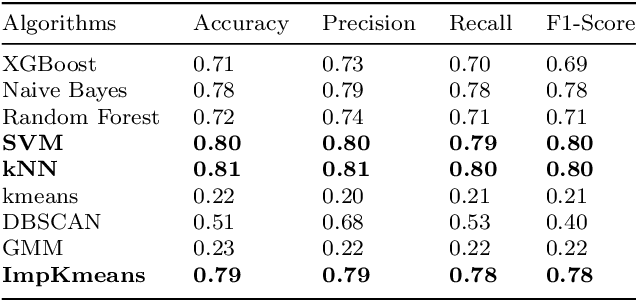
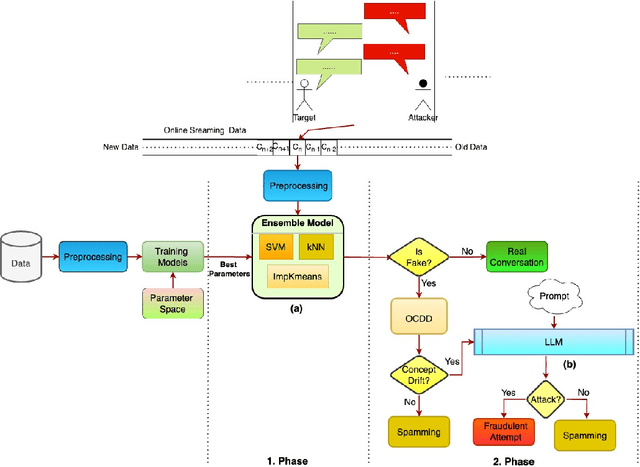
Detecting fake interactions in digital communication platforms remains a challenging and insufficiently addressed problem. These interactions may appear as harmless spam or escalate into sophisticated scam attempts, making it difficult to flag malicious intent early. Traditional detection methods often rely on static anomaly detection techniques that fail to adapt to dynamic conversational shifts. One key limitation is the misinterpretation of benign topic transitions referred to as concept drift as fraudulent behavior, leading to either false alarms or missed threats. We propose a two stage detection framework that first identifies suspicious conversations using a tailored ensemble classification model. To improve the reliability of detection, we incorporate a concept drift analysis step using a One Class Drift Detector (OCDD) to isolate conversational shifts within flagged dialogues. When drift is detected, a large language model (LLM) assesses whether the shift indicates fraudulent manipulation or a legitimate topic change. In cases where no drift is found, the behavior is inferred to be spam like. We validate our framework using a dataset of social engineering chat scenarios and demonstrate its practical advantages in improving both accuracy and interpretability for real time fraud detection. To contextualize the trade offs, we compare our modular approach against a Dual LLM baseline that performs detection and judgment using different language models.