 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Reasoning Quality in LLMs: A Multi-Dimensional Behavioral Framework
May 23, 2026LLMs have achieved remarkable success in complex reasoning tasks, yet current evaluation approaches predominantly rely on final-answer correctness, offering limited insight into the underlying reasoning processes that produce those answers. To address this gap, this study proposes a unified multi-dimensional framework for measuring reasoning quality in LLMs from a behavioral perspective, operationalizing six theoretically grounded dimensions: Correctness (CQ), Consistency (CS), Robustness (RS), Logical Coherence (LS), Efficiency (ES), and Stability (SS). Extensive experiments on seven LLMs across 975 items from four benchmarks demonstrate that the framework reveals behaviors invisible to accuracy-only metrics. Notably, logical coherence is orthogonal to correctness (r = -0.172, ns), confirming that correct answers can arise from incoherent reasoning, while Claude-Haiku-4.5 achieves the highest multi-dimensional score (Q_bal = 0.778). Furthermore, the framework exposes critical ranking inversions: DeepSeek-V3 ranks second under accuracy-priority but fifth under legal/compliance weighting, a reversal that single-metric evaluation cannot detect. Discriminant validity confirms 11/15 dimension pairs are independent (|r| < 0.50), providing psychometric support for treating each dimension as a distinct signal. The dimensional profiles produced by the framework directly support three classes of deployment decision: identifying models whose reasoning traces would fail accountability audits despite correct final answers (LS--CQ orthogonality); preventing ranking errors caused by accuracy-only benchmarking; and ensuring that no single metric silently substitutes for the six independent signals the framework captures.
From Workflow Automation to Capability Closure: A Formal Framework for Safe and Revenue-Aware Customer Service AI
Mar 16, 2026Customer service automation is undergoing a structural transformation. The dominant paradigm is shifting from scripted chatbots and single-agent responders toward networks of specialised AI agents that compose capabilities dynamically across billing, service provision, payments, and fulfilment. This shift introduces a safety gap that no current platform has closed: two agents individually verified as safe can, when combined, reach a forbidden goal through an emergent conjunctive dependency that neither possesses alone.
EssayCBM: Rubric-Aligned Concept Bottleneck Models for Transparent Essay Grading
Dec 23, 2025



Understanding how automated grading systems evaluate essays remains a significant challenge for educators and students, especially when large language models function as black boxes. We introduce EssayCBM, a rubric-aligned framework that prioritizes interpretability in essay assessment. Instead of predicting grades directly from text, EssayCBM evaluates eight writing concepts, such as Thesis Clarity and Evidence Use, through dedicated prediction heads on an encoder. These concept scores form a transparent bottleneck, and a lightweight network computes the final grade using only concepts. Instructors can adjust concept predictions and instantly view the updated grade, enabling accountable human-in-the-loop evaluation. EssayCBM matches black-box performance while offering actionable, concept-level feedback through an intuitive web interface.
Redefining CX with Agentic AI: Minerva CQ Case Study
Sep 16, 2025Despite advances in AI for contact centers, customer experience (CX) continues to suffer from high average handling time (AHT), low first-call resolution, and poor customer satisfaction (CSAT). A key driver is the cognitive load on agents, who must navigate fragmented systems, troubleshoot manually, and frequently place customers on hold. Existing AI-powered agent-assist tools are often reactive driven by static rules, simple prompting, or retrieval-augmented generation (RAG) without deeper contextual reasoning. We introduce Agentic AI goal-driven, autonomous, tool-using systems that proactively support agents in real time. Unlike conventional approaches, Agentic AI identifies customer intent, triggers modular workflows, maintains evolving context, and adapts dynamically to conversation state. This paper presents a case study of Minerva CQ, a real-time Agent Assist product deployed in voice-based customer support. Minerva CQ integrates real-time transcription, intent and sentiment detection, entity recognition, contextual retrieval, dynamic customer profiling, and partial conversational summaries enabling proactive workflows and continuous context-building. Deployed in live production, Minerva CQ acts as an AI co-pilot, delivering measurable improvements in agent efficiency and customer experience across multiple deployments.
Domain Knowledge-Enhanced LLMs for Fraud and Concept Drift Detection
Jun 26, 2025Detecting deceptive conversations on dynamic platforms is increasingly difficult due to evolving language patterns and Concept Drift (CD)\-i.e., semantic or topical shifts that alter the context or intent of interactions over time. These shifts can obscure malicious intent or mimic normal dialogue, making accurate classification challenging. While Large Language Models (LLMs) show strong performance in natural language tasks, they often struggle with contextual ambiguity and hallucinations in risk\-sensitive scenarios. To address these challenges, we present a Domain Knowledge (DK)\-Enhanced LLM framework that integrates pretrained LLMs with structured, task\-specific insights to perform fraud and concept drift detection. The proposed architecture consists of three main components: (1) a DK\-LLM module to detect fake or deceptive conversations; (2) a drift detection unit (OCDD) to determine whether a semantic shift has occurred; and (3) a second DK\-LLM module to classify the drift as either benign or fraudulent. We first validate the value of domain knowledge using a fake review dataset and then apply our full framework to SEConvo, a multiturn dialogue dataset that includes various types of fraud and spam attacks. Results show that our system detects fake conversations with high accuracy and effectively classifies the nature of drift. Guided by structured prompts, the LLaMA\-based implementation achieves 98\% classification accuracy. Comparative studies against zero\-shot baselines demonstrate that incorporating domain knowledge and drift awareness significantly improves performance, interpretability, and robustness in high\-stakes NLP applications.
Reversing the Paradigm: Building AI-First Systems with Human Guidance
Jun 13, 2025The relationship between humans and artificial intelligence is no longer science fiction -- it's a growing reality reshaping how we live and work. AI has moved beyond research labs into everyday life, powering customer service chats, personalizing travel, aiding doctors in diagnosis, and supporting educators. What makes this moment particularly compelling is AI's increasing collaborative nature. Rather than replacing humans, AI augments our capabilities -- automating routine tasks, enhancing decisions with data, and enabling creativity in fields like design, music, and writing. The future of work is shifting toward AI agents handling tasks autonomously, with humans as supervisors, strategists, and ethical stewards. This flips the traditional model: instead of humans using AI as a tool, intelligent agents will operate independently within constraints, managing everything from scheduling and customer service to complex workflows. Humans will guide and fine-tune these agents to ensure alignment with goals, values, and context. This shift offers major benefits -- greater efficiency, faster decisions, cost savings, and scalability. But it also brings risks: diminished human oversight, algorithmic bias, security flaws, and a widening skills gap. To navigate this transition, organizations must rethink roles, invest in upskilling, embed ethical principles, and promote transparency. This paper examines the technological and organizational changes needed to enable responsible adoption of AI-first systems -- where autonomy is balanced with human intent, oversight, and values.
Joint Detection of Fraud and Concept Drift inOnline Conversations with LLM-Assisted Judgment
May 07, 2025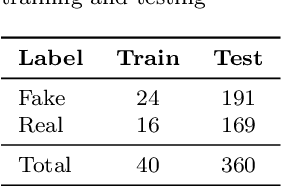
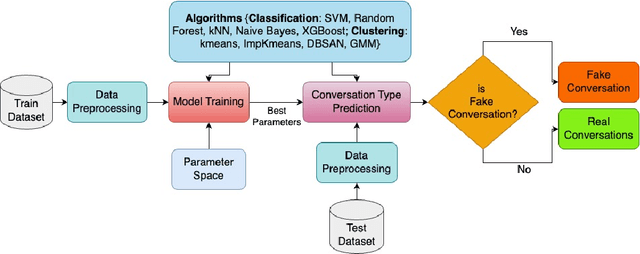
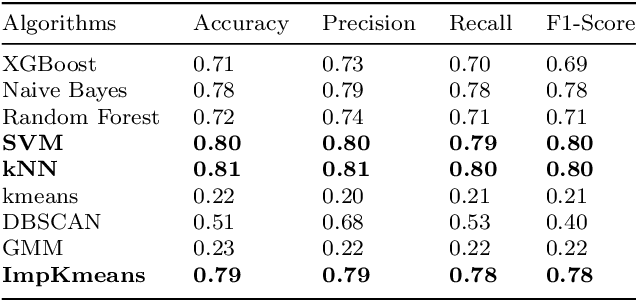
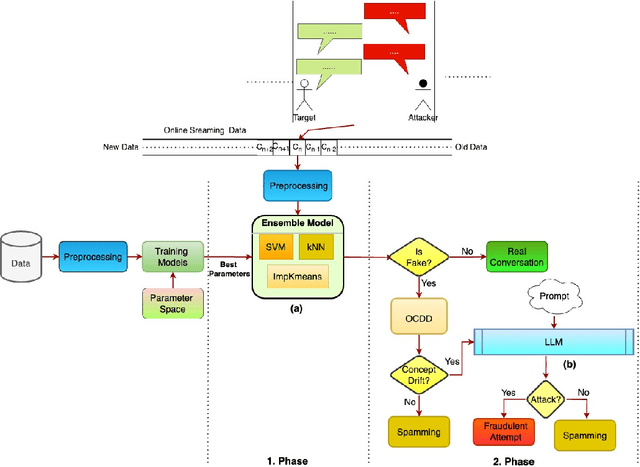
Detecting fake interactions in digital communication platforms remains a challenging and insufficiently addressed problem. These interactions may appear as harmless spam or escalate into sophisticated scam attempts, making it difficult to flag malicious intent early. Traditional detection methods often rely on static anomaly detection techniques that fail to adapt to dynamic conversational shifts. One key limitation is the misinterpretation of benign topic transitions referred to as concept drift as fraudulent behavior, leading to either false alarms or missed threats. We propose a two stage detection framework that first identifies suspicious conversations using a tailored ensemble classification model. To improve the reliability of detection, we incorporate a concept drift analysis step using a One Class Drift Detector (OCDD) to isolate conversational shifts within flagged dialogues. When drift is detected, a large language model (LLM) assesses whether the shift indicates fraudulent manipulation or a legitimate topic change. In cases where no drift is found, the behavior is inferred to be spam like. We validate our framework using a dataset of social engineering chat scenarios and demonstrate its practical advantages in improving both accuracy and interpretability for real time fraud detection. To contextualize the trade offs, we compare our modular approach against a Dual LLM baseline that performs detection and judgment using different language models.
CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented Generation
Apr 01, 2025


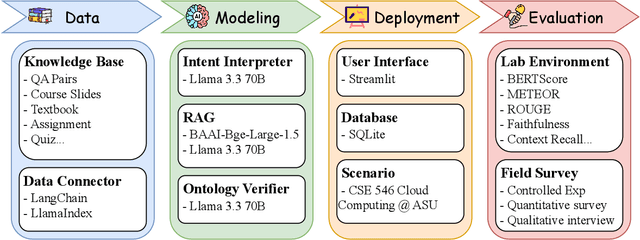
Advancements in large language models (LLMs) have enabled the development of intelligent educational tools that support inquiry-based learning across technical domains. In cybersecurity education, where accuracy and safety are paramount, systems must go beyond surface-level relevance to provide information that is both trustworthy and domain-appropriate. To address this challenge, we introduce CyberBOT, a question-answering chatbot that leverages a retrieval-augmented generation (RAG) pipeline to incorporate contextual information from course-specific materials and validate responses using a domain-specific cybersecurity ontology. The ontology serves as a structured reasoning layer that constrains and verifies LLM-generated answers, reducing the risk of misleading or unsafe guidance. CyberBOT has been deployed in a large graduate-level course at Arizona State University (ASU), where more than one hundred students actively engage with the system through a dedicated web-based platform. Computational evaluations in lab environments highlight the potential capacity of CyberBOT, and a forthcoming field study will evaluate its pedagogical impact. By integrating structured domain reasoning with modern generative capabilities, CyberBOT illustrates a promising direction for developing reliable and curriculum-aligned AI applications in specialized educational contexts.
RedditESS: A Mental Health Social Support Interaction Dataset -- Understanding Effective Social Support to Refine AI-Driven Support Tools
Mar 27, 2025Effective mental health support is crucial for alleviating psychological distress. While large language model (LLM)-based assistants have shown promise in mental health interventions, existing research often defines "effective" support primarily in terms of empathetic acknowledgments, overlooking other essential dimensions such as informational guidance, community validation, and tangible coping strategies. To address this limitation and better understand what constitutes effective support, we introduce RedditESS, a novel real-world dataset derived from Reddit posts, including supportive comments and original posters' follow-up responses. Grounded in established social science theories, we develop an ensemble labeling mechanism to annotate supportive comments as effective or not and perform qualitative assessments to ensure the reliability of the annotations. Additionally, we demonstrate the practical utility of RedditESS by using it to guide LLM alignment toward generating more context-sensitive and genuinely helpful supportive responses. By broadening the understanding of effective support, our study paves the way for advanced AI-driven mental health interventions.
Ontology-Aware RAG for Improved Question-Answering in Cybersecurity Education
Dec 10, 2024Integrating AI into education has the potential to transform the teaching of science and technology courses, particularly in the field of cybersecurity. AI-driven question-answering (QA) systems can actively manage uncertainty in cybersecurity problem-solving, offering interactive, inquiry-based learning experiences. Large language models (LLMs) have gained prominence in AI-driven QA systems, offering advanced language understanding and user engagement. However, they face challenges like hallucinations and limited domain-specific knowledge, which reduce their reliability in educational settings. To address these challenges, we propose CyberRAG, an ontology-aware retrieval-augmented generation (RAG) approach for developing a reliable and safe QA system in cybersecurity education. CyberRAG employs a two-step approach: first, it augments the domain-specific knowledge by retrieving validated cybersecurity documents from a knowledge base to enhance the relevance and accuracy of the response. Second, it mitigates hallucinations and misuse by integrating a knowledge graph ontology to validate the final answer. Experiments on publicly available cybersecurity datasets show that CyberRAG delivers accurate, reliable responses aligned with domain knowledge, demonstrating the potential of AI tools to enhance education.