 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarwinian Memory: A Training-Free Self-Regulating Memory System for GUI Agent Evolution
Jan 30, 2026Multimodal Large Language Model (MLLM) agents facilitate Graphical User Interface (GUI) automation but struggle with long-horizon, cross-application tasks due to limited context windows. While memory systems provide a viable solution, existing paradigms struggle to adapt to dynamic GUI environments, suffering from a granularity mismatch between high-level intent and low-level execution, and context pollution where the static accumulation of outdated experiences drives agents into hallucination. To address these bottlenecks, we propose the Darwinian Memory System (DMS), a self-evolving architecture that constructs memory as a dynamic ecosystem governed by the law of survival of the fittest. DMS decomposes complex trajectories into independent, reusable units for compositional flexibility, and implements Utility-driven Natural Selection to track survival value, actively pruning suboptimal paths and inhibiting high-risk plans. This evolutionary pressure compels the agent to derive superior strategies. Extensive experiments on real-world multi-app benchmarks validate that DMS boosts general-purpose MLLMs without training costs or architectural overhead, achieving average gains of 18.0% in success rate and 33.9% in execution stability, while reducing task latency, establishing it as an effective self-evolving memory system for GUI tasks.
LDTR: Transformer-based Lane Detection with Anchor-chain Representation
Mar 21, 2024Despite recent advances in lane detection methods, scenarios with limited- or no-visual-clue of lanes due to factors such as lighting conditions and occlusion remain challenging and crucial for automated driving. Moreover, current lane representations require complex post-processing and struggle with specific instances. Inspired by the DETR architecture, we propose LDTR, a transformer-based model to address these issues. Lanes are modeled with a novel anchor-chain, regarding a lane as a whole from the beginning, which enables LDTR to handle special lanes inherently. To enhance lane instance perception, LDTR incorporates a novel multi-referenced deformable attention module to distribute attention around the object. Additionally, LDTR incorporates two line IoU algorithms to improve convergence efficiency and employs a Gaussian heatmap auxiliary branch to enhance model representation capability during training. To evaluate lane detection models, we rely on Frechet distance, parameterized F1-score, and additional synthetic metrics. Experimental results demonstrate that LDTR achieves state-of-the-art performance on well-known datasets.
Pre-Training on Large-Scale Generated Docking Conformations with HelixDock to Unlock the Potential of Protein-ligand Structure Prediction Models
Oct 21, 2023Molecular docking, a pivotal computational tool for drug discovery, predicts the binding interactions between small molecules (ligands) and target proteins (receptors). Conventional physics-based docking tools, though widely used, face limitations in precision due to restricted conformational sampling and imprecise scoring functions. Recent endeavors have employed deep learning techniques to enhance docking accuracy, but their generalization remains a concern due to limited training data. Leveraging the success of extensive and diverse data in other domains, we introduce HelixDock, a novel approach for site-specific molecular docking. Hundreds of millions of binding poses are generated by traditional docking tools, encompassing diverse protein targets and small molecules. Our deep learning-based docking model, a SE(3)-equivariant network, is pre-trained with this large-scale dataset and then fine-tuned with a small number of precise receptor-ligand complex structures. Comparative analyses against physics-based and deep learning-based baseline methods highlight HelixDock's superiority, especially on challenging test sets. Our study elucidates the scaling laws of the pre-trained molecular docking models, showcasing consistent improvements with increased model parameters and pre-train data quantities. Harnessing the power of extensive and diverse generated data holds promise for advancing AI-driven drug discovery.
GRASS: Unified Generation Model for Speech-to-Semantic Tasks
Sep 11, 2023


This paper explores the instruction fine-tuning technique for speech-to-semantic tasks by introducing a unified end-to-end (E2E) framework that generates target text conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model achieves state-of-the-art (SOTA) results on many benchmarks covering speech named entity recognition, speech sentiment analysis, speech question answering, and more, after fine-tuning. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
CANet: Curved Guide Line Network with Adaptive Decoder for Lane Detection
Apr 23, 2023



Lane detection is challenging due to the complicated on road scenarios and line deformation from different camera perspectives. Lots of solutions were proposed, but can not deal with corner lanes well. To address this problem, this paper proposes a new top-down deep learning lane detection approach, CANET. A lane instance is first responded by the heat-map on the U-shaped curved guide line at global semantic level, thus the corresponding features of each lane are aggregated at the response point. Then CANET obtains the heat-map response of the entire lane through conditional convolution, and finally decodes the point set to describe lanes via adaptive decoder. The experimental results show that CANET reaches SOTA in different metrics. Our code will be released soon.
Graph Signal Sampling for Inductive One-Bit Matrix Completion: a Closed-form Solution
Feb 08, 2023Inductive one-bit matrix completion is motivated by modern applications such as recommender systems, where new users would appear at test stage with the ratings consisting of only ones and no zeros. We propose a unified graph signal sampling framework which enjoys the benefits of graph signal analysis and processing. The key idea is to transform each user's ratings on the items to a function (signal) on the vertices of an item-item graph, then learn structural graph properties to recover the function from its values on certain vertices -- the problem of graph signal sampling. We propose a class of regularization functionals that takes into account discrete random label noise in the graph vertex domain, then develop the GS-IMC approach which biases the reconstruction towards functions that vary little between adjacent vertices for noise reduction. Theoretical result shows that accurate reconstructions can be achieved under mild conditions. For the online setting, we develop a Bayesian extension, i.e., BGS-IMC which considers continuous random Gaussian noise in the graph Fourier domain and builds upon a prediction-correction update algorithm to obtain the unbiased and minimum-variance reconstruction. Both GS-IMC and BGS-IMC have closed-form solutions and thus are highly scalable in large data. Experiments show that our methods achieve state-of-the-art performance on public benchmarks.
S4OD: Semi-Supervised learning for Single-Stage Object Detection
Apr 09, 2022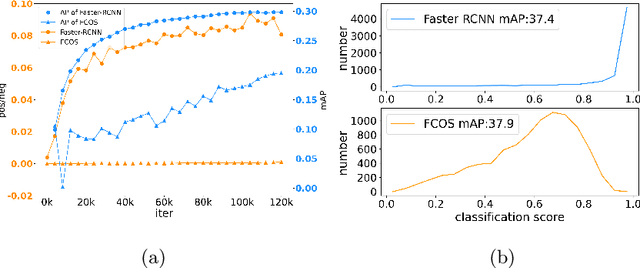
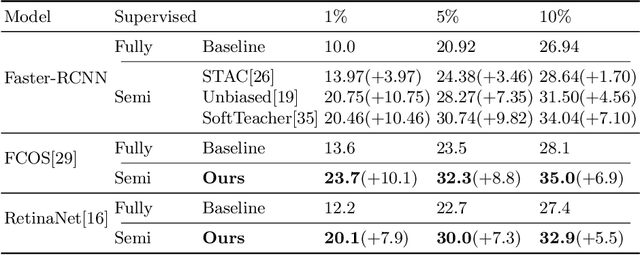
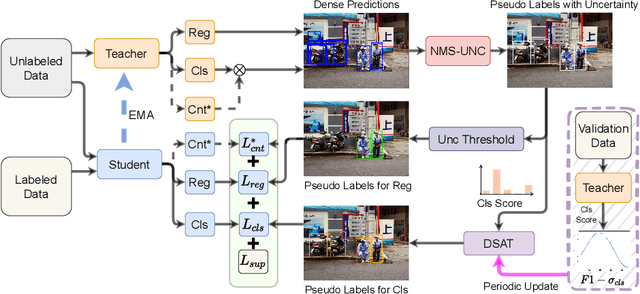

Single-stage detectors suffer from extreme foreground-background class imbalance, while two-stage detectors do not. Therefore, in semi-supervised object detection, two-stage detectors can deliver remarkable performance by only selecting high-quality pseudo labels based on classification scores. However, directly applying this strategy to single-stage detectors would aggravate the class imbalance with fewer positive samples. Thus, single-stage detectors have to consider both quality and quantity of pseudo labels simultaneously. In this paper, we design a dynamic self-adaptive threshold (DSAT) strategy in classification branch, which can automatically select pseudo labels to achieve an optimal trade-off between quality and quantity. Besides, to assess the regression quality of pseudo labels in single-stage detectors, we propose a module to compute the regression uncertainty of boxes based on Non-Maximum Suppression. By leveraging only 10% labeled data from COCO, our method achieves 35.0% AP on anchor-free detector (FCOS) and 32.9% on anchor-based detector (RetinaNet).
An End-to-End Visual-Audio Attention Network for Emotion Recognition in User-Generated Videos
Feb 12, 2020

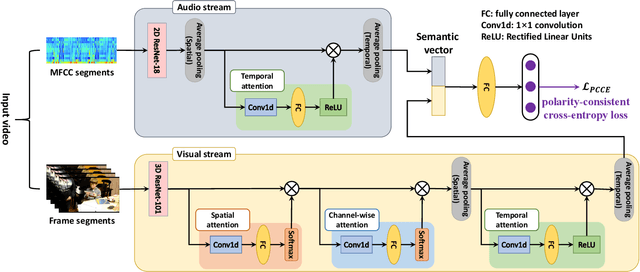

Emotion recognition in user-generated videos plays an important role in human-centered computing. Existing methods mainly employ traditional two-stage shallow pipeline, i.e. extracting visual and/or audio features and training classifiers. In this paper, we propose to recognize video emotions in an end-to-end manner based on convolutional neural networks (CNNs). Specifically, we develop a deep Visual-Audio Attention Network (VAANet), a novel architecture that integrates spatial, channel-wise, and temporal attentions into a visual 3D CNN and temporal attentions into an audio 2D CNN. Further, we design a special classification loss, i.e. polarity-consistent cross-entropy loss, based on the polarity-emotion hierarchy constraint to guide the attention generation. Extensive experiments conducted on the challenging VideoEmotion-8 and Ekman-6 datasets demonstrate that the proposed VAANet outperforms the state-of-the-art approaches for video emotion recognition. Our source code is released at: https://github.com/maysonma/VAANet.
Multi-source Distilling Domain Adaptation
Nov 22, 2019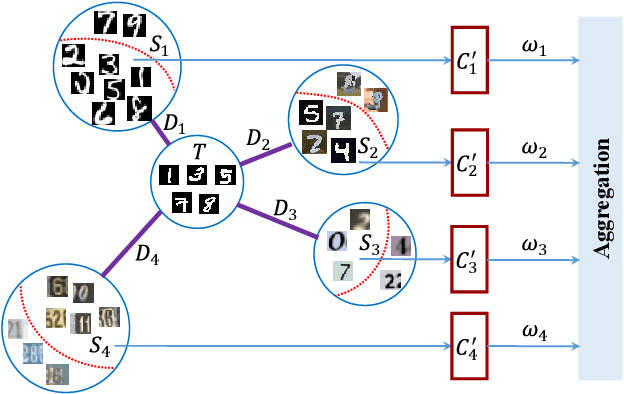
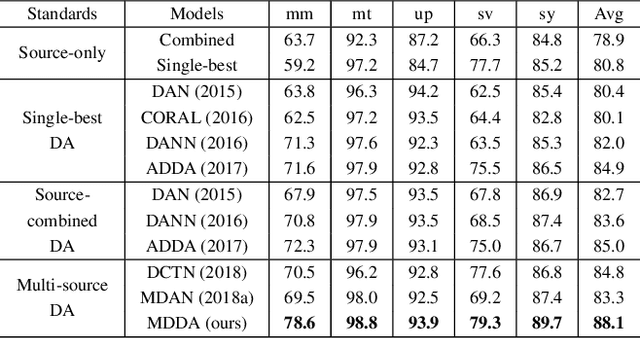
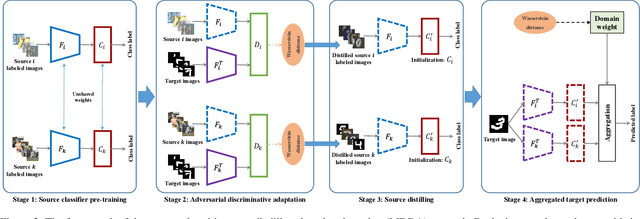
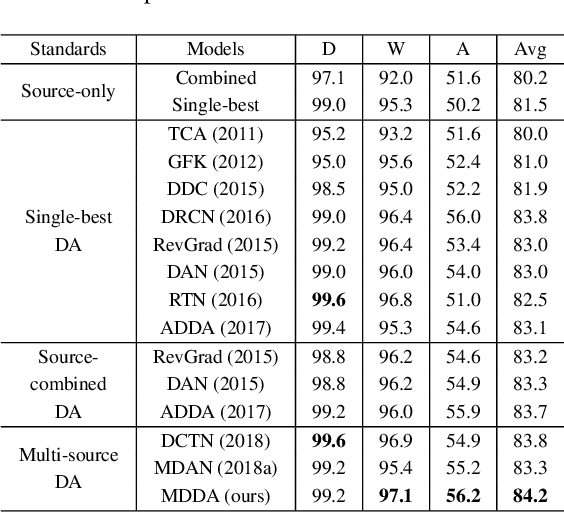
Deep neural networks suffer from performance decay when there is domain shift between the labeled source domain and unlabeled target domain, which motivates the research on domain adaptation (DA). Conventional DA methods usually assume that the labeled data is sampled from a single source distribution. However, in practice, labeled data may be collected from multiple sources, while naive application of the single-source DA algorithms may lead to suboptimal solutions. In this paper, we propose a novel multi-source distilling domain adaptation (MDDA) network, which not only considers the different distances among multiple sources and the target, but also investigates the different similarities of the source samples to the target ones. Specifically, the proposed MDDA includes four stages: (1) pre-train the source classifiers separately using the training data from each source; (2) adversarially map the target into the feature space of each source respectively by minimizing the empirical Wasserstein distance between source and target; (3) select the source training samples that are closer to the target to fine-tune the source classifiers; and (4) classify each encoded target feature by corresponding source classifier, and aggregate different predictions using respective domain weight, which corresponds to the discrepancy between each source and target. Extensive experiments are conducted on public DA benchmarks, and the results demonstrate that the proposed MDDA significantly outperforms the state-of-the-art approaches. Our source code is released at: https://github.com/daoyuan98/MDDA.
Multi-source Domain Adaptation for Semantic Segmentation
Oct 27, 2019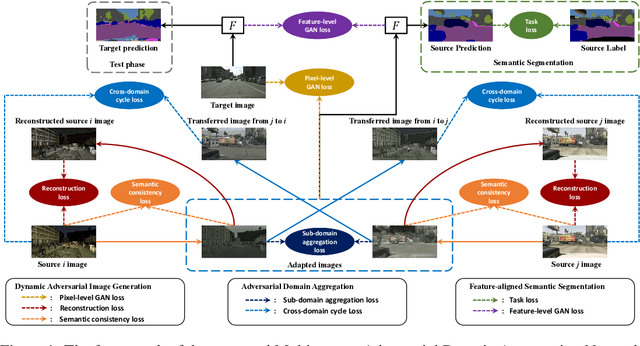

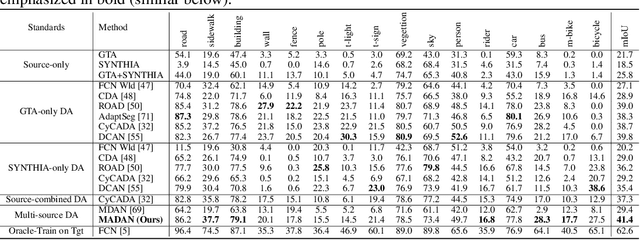

Simulation-to-real domain adaptation for semantic segmentation has been actively studied for various applications such as autonomous driving. Existing methods mainly focus on a single-source setting, which cannot easily handle a more practical scenario of multiple sources with different distributions. In this paper, we propose to investigate multi-source domain adaptation for semantic segmentation. Specifically, we design a novel framework, termed Multi-source Adversarial Domain Aggregation Network (MADAN), which can be trained in an end-to-end manner. First, we generate an adapted domain for each source with dynamic semantic consistency while aligning at the pixel-level cycle-consistently towards the target. Second, we propose sub-domain aggregation discriminator and cross-domain cycle discriminator to make different adapted domains more closely aggregated. Finally, feature-level alignment is performed between the aggregated domain and target domain while training the segmentation network. Extensive experiments from synthetic GTA and SYNTHIA to real Cityscapes and BDDS datasets demonstrate that the proposed MADAN model outperforms state-of-the-art approaches. Our source code is released at: https://github.com/Luodian/MADAN.