 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Multi-source Distilling Domain Adaptation
Nov 22, 2019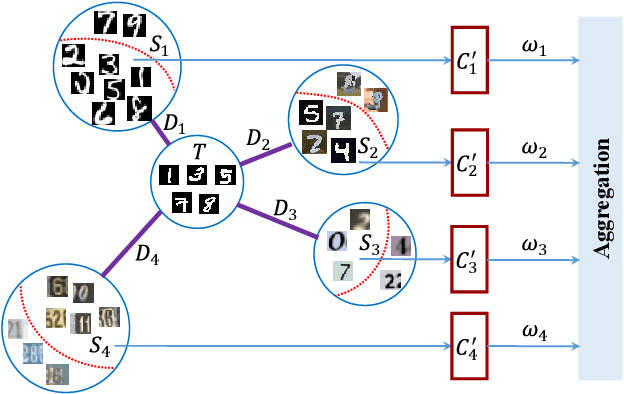
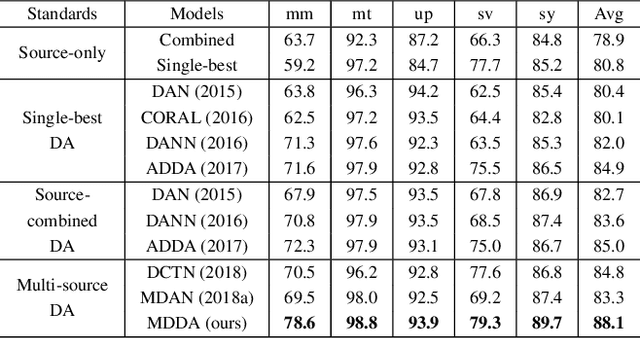
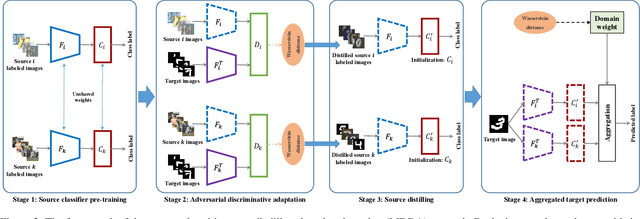
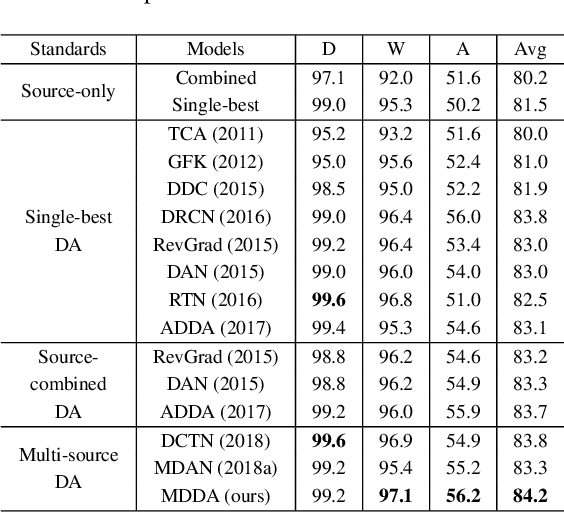
Deep neural networks suffer from performance decay when there is domain shift between the labeled source domain and unlabeled target domain, which motivates the research on domain adaptation (DA). Conventional DA methods usually assume that the labeled data is sampled from a single source distribution. However, in practice, labeled data may be collected from multiple sources, while naive application of the single-source DA algorithms may lead to suboptimal solutions. In this paper, we propose a novel multi-source distilling domain adaptation (MDDA) network, which not only considers the different distances among multiple sources and the target, but also investigates the different similarities of the source samples to the target ones. Specifically, the proposed MDDA includes four stages: (1) pre-train the source classifiers separately using the training data from each source; (2) adversarially map the target into the feature space of each source respectively by minimizing the empirical Wasserstein distance between source and target; (3) select the source training samples that are closer to the target to fine-tune the source classifiers; and (4) classify each encoded target feature by corresponding source classifier, and aggregate different predictions using respective domain weight, which corresponds to the discrepancy between each source and target. Extensive experiments are conducted on public DA benchmarks, and the results demonstrate that the proposed MDDA significantly outperforms the state-of-the-art approaches. Our source code is released at: https://github.com/daoyuan98/MDDA.
Person Re-Identification via Recurrent Feature Aggregation
Jan 23, 2017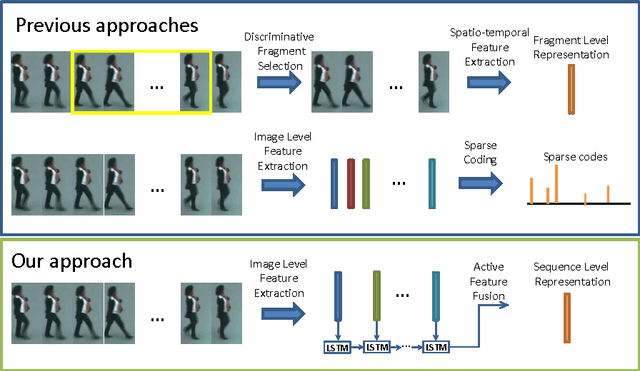
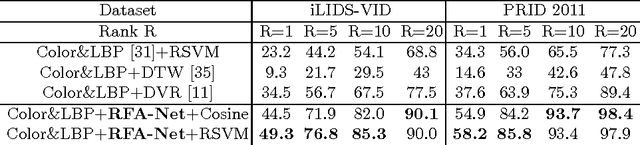
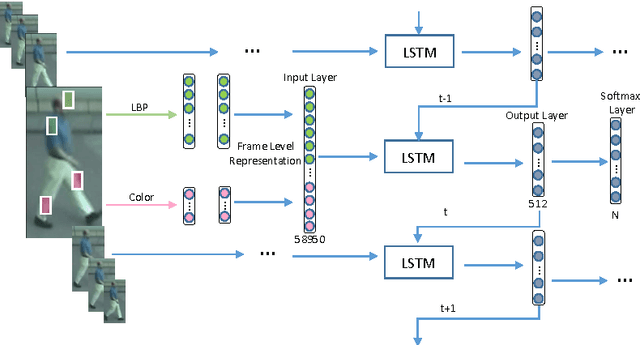

We address the person re-identification problem by effectively exploiting a globally discriminative feature representation from a sequence of tracked human regions/patches. This is in contrast to previous person re-id works, which rely on either single frame based person to person patch matching, or graph based sequence to sequence matching. We show that a progressive/sequential fusion framework based on long short term memory (LSTM) network aggregates the frame-wise human region representation at each time stamp and yields a sequence level human feature representation. Since LSTM nodes can remember and propagate previously accumulated good features and forget newly input inferior ones, even with simple hand-crafted features, the proposed recurrent feature aggregation network (RFA-Net) is effective in generating highly discriminative sequence level human representations. Extensive experimental results on two person re-identification benchmarks demonstrate that the proposed method performs favorably against state-of-the-art person re-identification methods.